Chat Completions、Memory、JSONMode 实战 电脑版发表于:2025/7/17 14:58  >#Chat Completions、Memory、JSONMode 实战 [TOC] 简单的对话 ------------ tn2>安装 Python:https://www.python.org/downloads/ 安装 OpenAI Python 包:`pip install --upgrade openai` 申请 API Key(测试阶段可使用国内代理,有免费额度,不保证可用性) 设置环境变量:`export OPENAI_API_KEY='your-api-key-here'` 编写代码:https://platform.openai.com/docs/quickstart/step-3-sending-your-first-api-request  ### 简单的对话案例 ```python from openai import OpenAI client = OpenAI( api_key="你的key", ) completion = client.chat.completions.create( model="gpt-4o-mini", messages=[ { "role": "system", "content": "你现在是一个运维专家,你的工作是帮助用户解决技术问题。", }, { "role": "user", "content": "linux 端口被占用怎么排查?直接给我一条命令即可。", }, ], ) print(completion.choices[0].message.content) ``` | Role的类型 | 描述 | | ------------ | ------------ | | `role=system` | 系统设定 Prompt | | `role=user` | 用户消息 | | `role=assistant` | AI 回复的消息 | tn2>运行测试一下: ```bash python main.py ``` 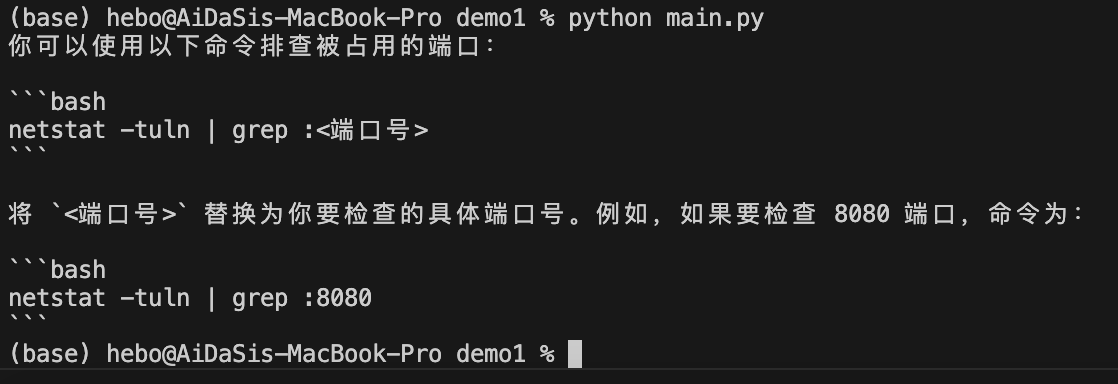 tn2>问题:如何基于 AI 的回答继续对话?(记忆问题怎么处理) ### 内存存储对话内容 tn2>由于对话接口是无状态的,每次推理都需要把历史聊天记录追加到 message 参数 保持记忆=把聊天记录上下文传到 message 参数 ```python from openai import OpenAI client = OpenAI( api_key="你的key", ) messages = [ { "role": "system", "content": "你现在是一个运维专家,你的工作是帮助用户解决技术问题。", } ] while True: user_input = input("输入问题:") messages.append( { "role": "user", "content": user_input, } ) print("当前聊天上下文:", messages) completion = client.chat.completions.create( model="gpt-4o-mini", messages=messages, ) reply = completion.choices[0].message.content print(f"\n运维专家: {reply}") messages.append( { "role": "assistant", "content": reply, } ) ``` 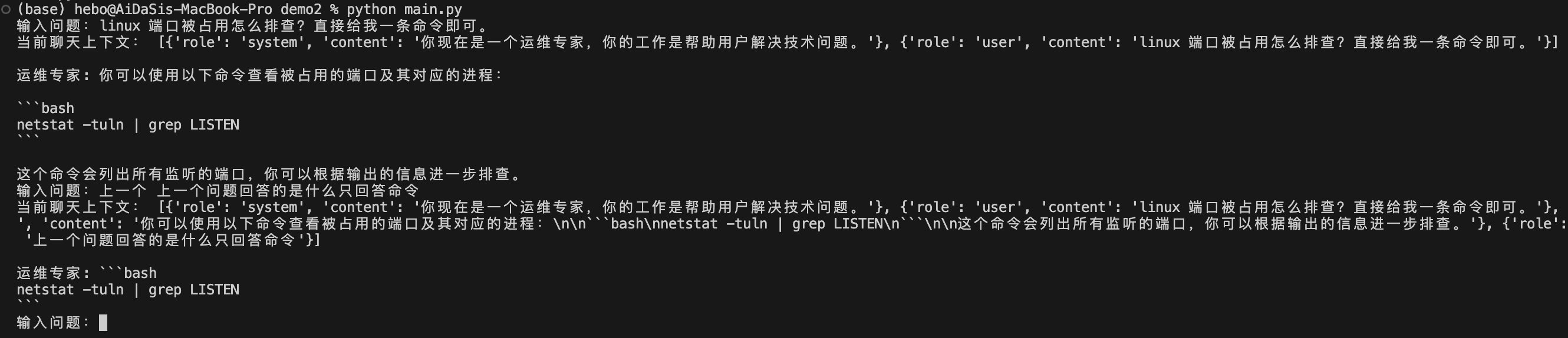 LangChain内存框架记忆存储 ------------ | **模式** | **描述** | **特点** | **适用场景** | | ---------------------------------- | ------------------------ | ---------------- | --------------- | | **ConversationBufferMemory** | 存储完整对话内容(字符串) | 无截断,token 消耗大 | 对话较短,保持完整上下文 | | **ConversationBufferWindowMemory** | 只保留最近 `k` 轮对话 | 限制窗口,防止太长 | 只关心最近交互的场景 | | **ConversationTokenBufferMemory** | 只保留最近 `N` 个 **token** | 更精细控制长度,防止超上下文限制 | 长对话,避免 token 超限 | | **ConversationSummaryMemory** | 用 LLM 生成对话摘要,替代旧历史 | 压缩长对话,token 友好 | 长对话,需保留上下文 | tn2>这里的`ConversationBufferMemory`跟我们的存储方式其实是没有什么太大区别的,我们可以尝试使用看看。 首先安装`langchain`包。 ```bash pip install langchain pip install langchain_community ``` tn2>安装好后写上如下代码: ```python from langchain.chat_models import ChatOpenAI from langchain.chains import ConversationChain from langchain.memory import ConversationBufferMemory llm = ChatOpenAI( model="gpt-4o", api_key="你的Key", max_tokens=None, timeout=None, ) memory = ConversationBufferMemory() conversation = ConversationChain( llm=llm, memory=memory, verbose=False, ) while True: user_input = input("输入问题:") reply = conversation.predict(input=user_input) print("当前聊天上下文:", conversation.memory) print(f"\n\n运维专家: {reply}") ``` tn2>运行测试如下图所示: ```python python main.py ``` 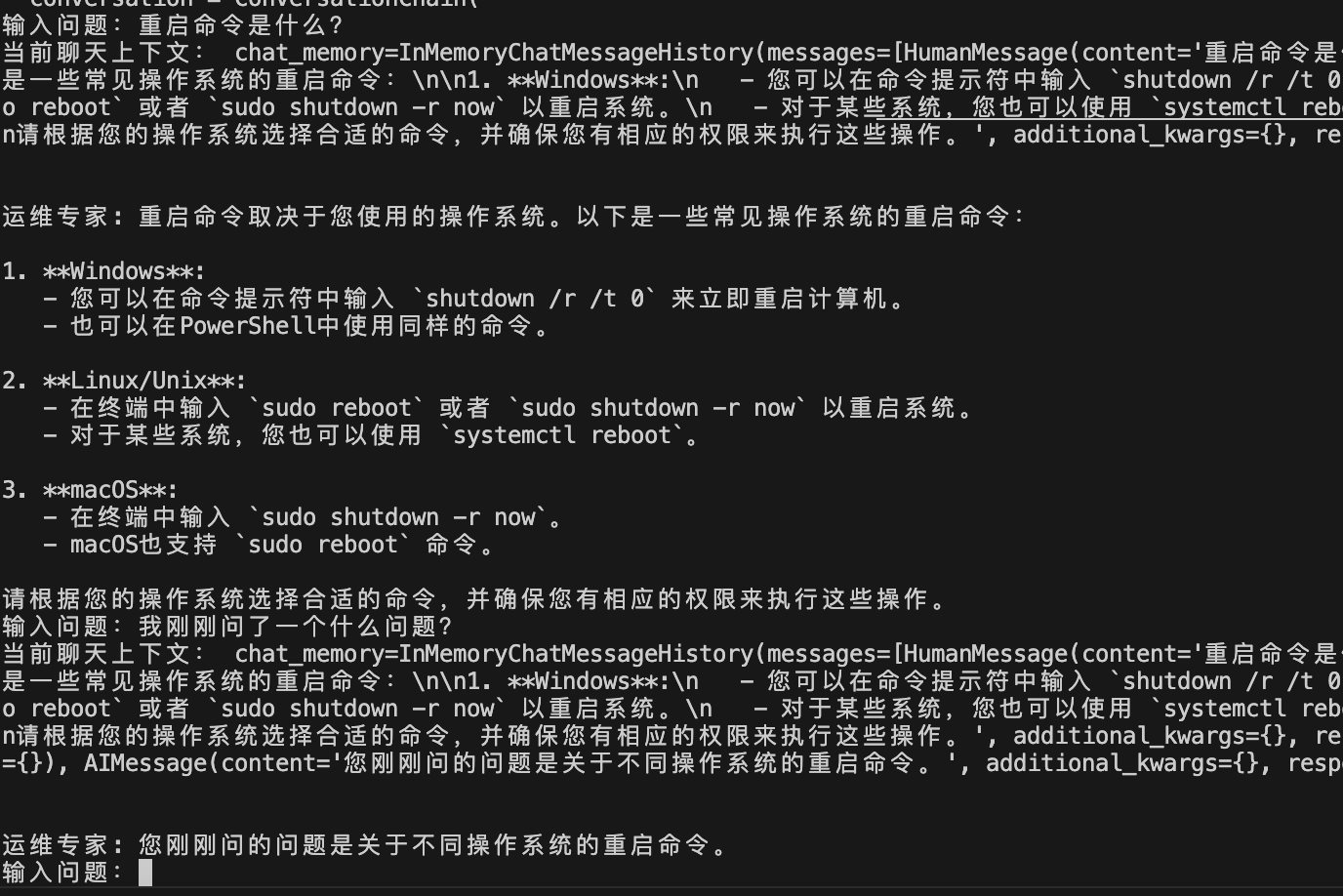 ### LangChain ConversationBufferWindowMemory示例 tn2>只记住最后 30 轮的对话 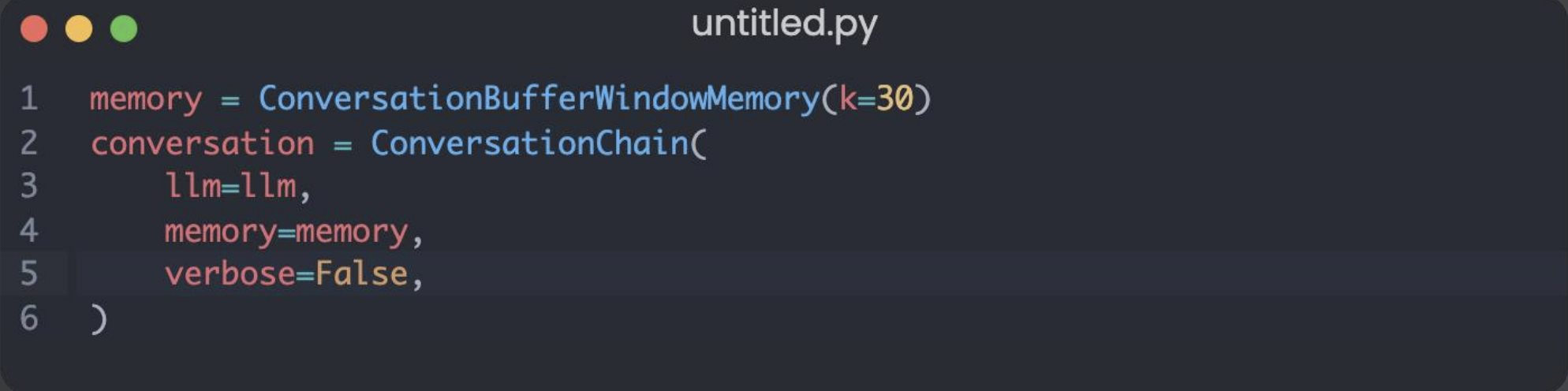 ### LangChain ConversationTokenBufferMemory示例 tn2>只记住 128k 以内 token 的对话 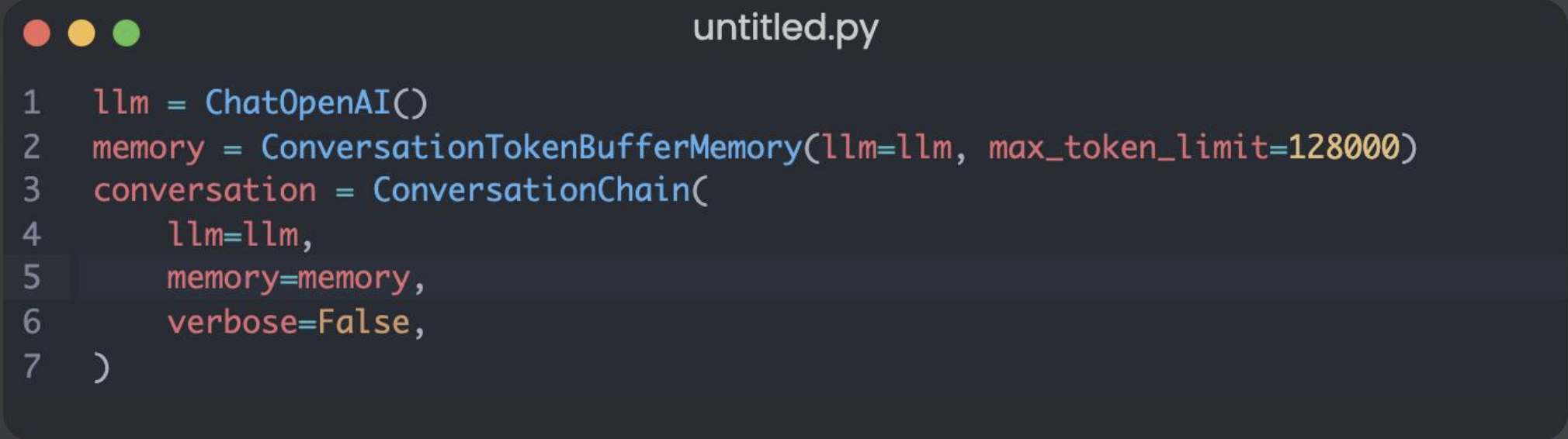 ### LangChain ConversationSummaryBufferMemory tn2>对超过 128K Token 的上下文进行总结,实现记住更多的内容 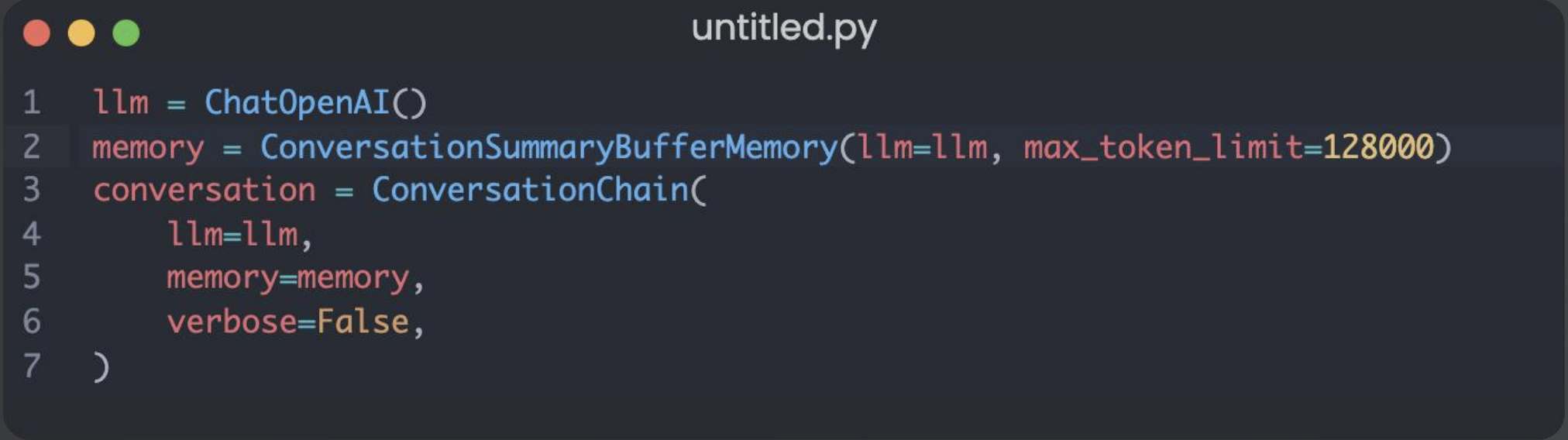 ### JSON 模式 tn2>JSON 模式:让 LLM 稳定输出 JSON 的技术 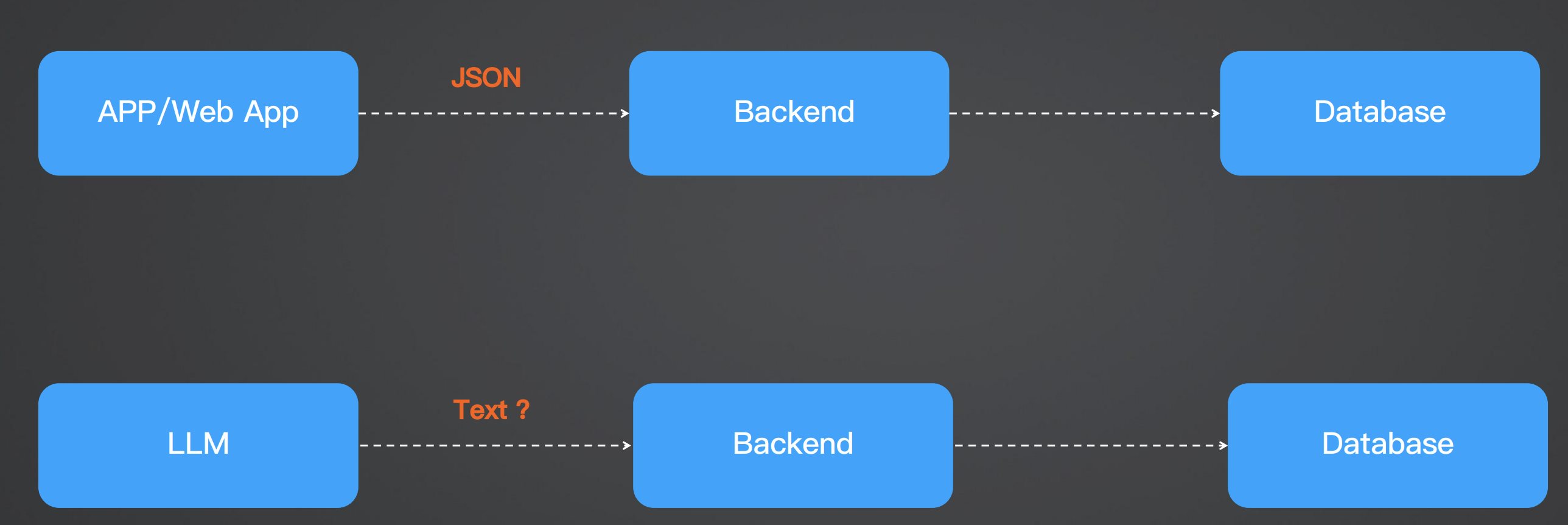 tn2>要求: 参数配置 `response_format={"type": "json_object"}` system prompt 包含JSON关键字 使用场景: 从语义化内容中提取参数,然后交由程序处理`few-shot` 表现更稳定 缺点: JSON Schema 相对固定,难以实现复杂业务逻辑 ```python from openai import OpenAI client = OpenAI( api_key="你的key", ) completion = client.chat.completions.create( model="gpt-4o-mini", response_format={"type": "json_object"}, messages=[ { "role": "system", "content": '你现在是一个 JSON 对象提取专家,请参考我的 JSON 定义输出 JSON 对象。示例:{"service_name":"","action":""},其中,action 可以是 get_log(获取日志)、restart(重启服务)、delete(删除工作负载)', }, { "role": "user", "content": "帮我重启 payment 服务。", }, ], ) print(completion.choices[0].message.content) ``` 

