Doris 物化视图(学习笔记) 电脑版发表于:2025/4/6 11:03  >#Doris 物化视图(学习笔记) [TOC] tn2>就是查询结果预先存储起来的特殊的表。 物化视图的出现主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询。 优势 ------------ tn2>1.可以复用预计算的结果来提高查询效率 ==> 空间换时间 2.自动实时的维护物化视图表中的结果数据,无需额外人工成本(自动维护会有计算资源的开销) 3.查询时,会自动选择最优物化视图 物化视图 VS Rollup ------------ tn2>明细模型表下,rollup和物化视图的差别: 物化视图:都可以实现预聚合,新增一套前缀索引 rollup:对于明细模型,新增一套前缀索引 聚合模型下,功能一致 tn>物化视图和rollup 本身特别像 在聚合模型下,功能一样,自行选择使用哪种,因为都一样。 对于明细模型来讲:rollup除了可以增加一套前缀索引之外,没有其他特别的用途。 假如你的表刚好是明细模型的表,又想使用rollup 的效果,此时可以选择使用物化视图。 创建物化视图 ------------ tn2>语法: ```bash CREATE MATERIALIZED VIEW [MV name] as [query] -- sql逻辑 --[MV name]:雾化视图的名称 --[query]:查询条件,基于base表创建雾化视图的逻辑 取消正在创建的物化视图 CANCEL ALTER MATERIALIZED VIEW FROM db_name.table_name ``` tn2>物化视图创建成功后,用户的查询不需要发生任何改变,也就是还是查询的 base 表。 Doris 会根据当前查询的语句去自动选择一个最优的物化视图,从物化视图中读取数据并计算。 用户可以通过 EXPLAIN 命令来检查当前查询是否使用了物化视图。 案例演示 ------------ tn2>创建一个 Base 表: 用户有一张销售记录明细表,存储了每个交易的交易id,销售员,售卖门店,销售时间,以及金额。 ```bash drop table sales_records; create table sales_records( record_id int, seller_id int, store_id int, sale_date date, sale_amt bigint) duplicate key (record_id,seller_id,store_id,sale_date) distributed by hash(record_id) buckets 2 properties("replication_num" = "1"); -- 插入数据 insert into sales_records values (1,1,1,'2022-02-02',100), (2,2,1,'2022-02-02',200), (3,3,2,'2022-02-02',300), (4,3,2,'2022-02-02',200), (5,2,1,'2022-02-02',100), (6,4,2,'2022-02-02',200), (7,7,3,'2022-02-02',300), (8,2,1,'2022-02-02',400), (9,9,4,'2022-02-02',100); ``` 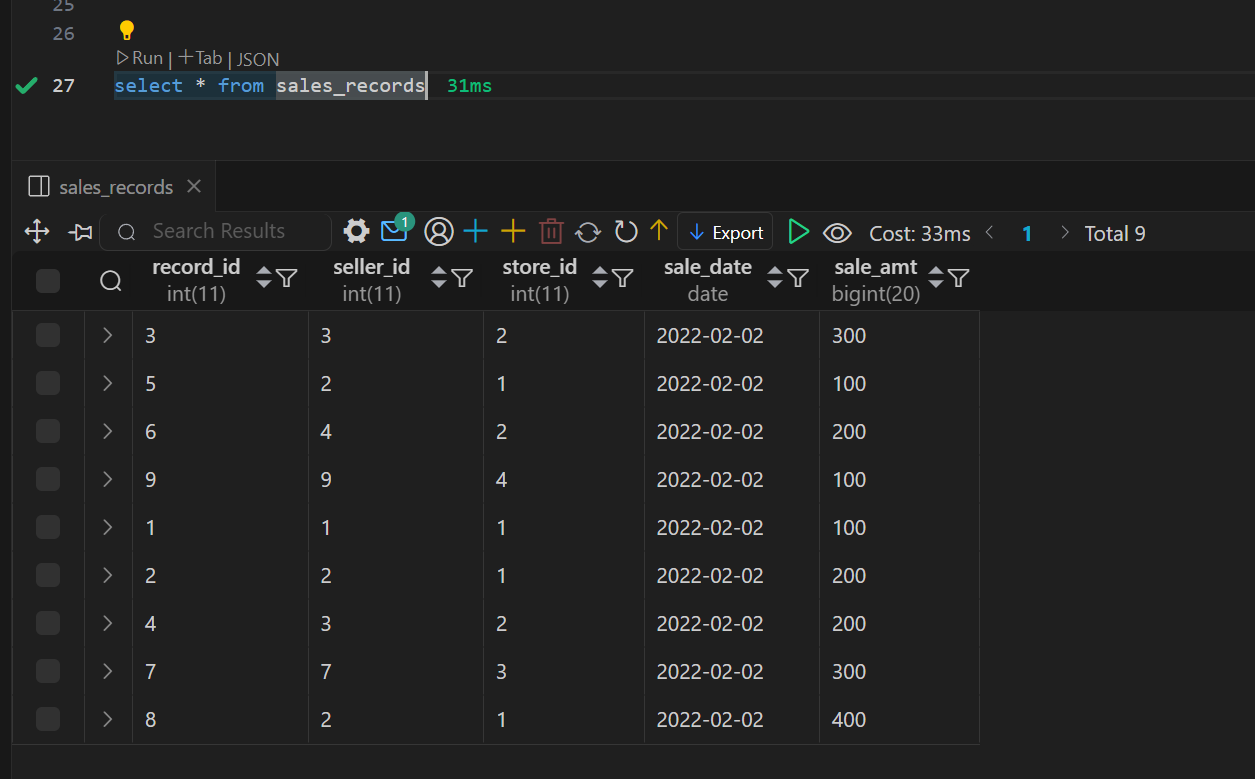 tn2>如果用户需要经常对不同门店的销售量进行统计 第一步:创建一个物化视图 ```sql -- 不同门店,看总销售额的一个场景 select store_id, sum(sale_amt) from sales_records group by store_id; --针对上述场景做一个物化视图 create materialized view store_amt as select store_id, sum(sale_amt) as sum_amount from sales_records group by store_id; ``` 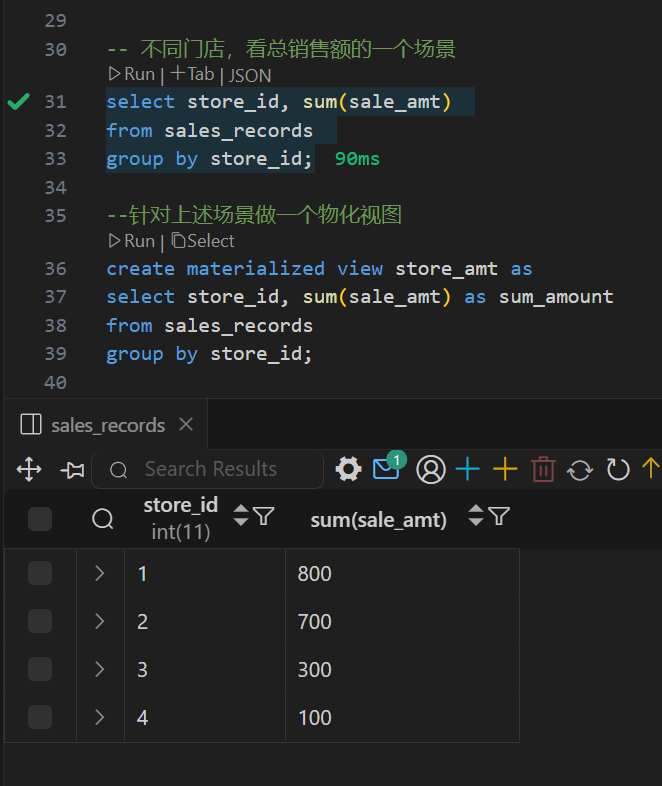 tn>创建物化视图的sql语句在datagrip 中报错,没有办法创建(将来新的版本可能会支持),需要在黑窗口执行该命令创建。 第二步:检查物化视图是否构建完成(物化视图的创建是个异步的过程) ```sql show alter table materialized view from 库名 order by CreateTime desc limit 1; show alter table materialized view from test order by CreateTime desc limit 1; ```  ```sql 查看 Base 表的所有物化视图 desc sales_records all; ``` 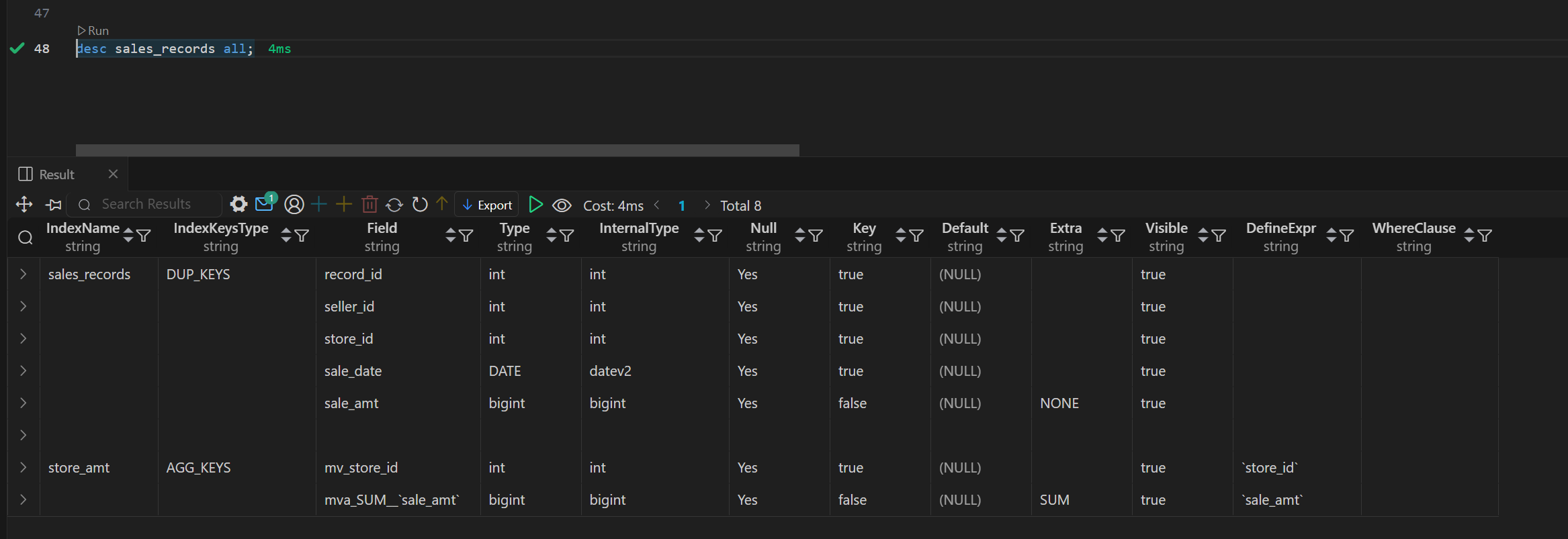 tn2>第三步:查询 看是否命中刚才我们建的物化视图 ```sql EXPLAIN SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id; ``` 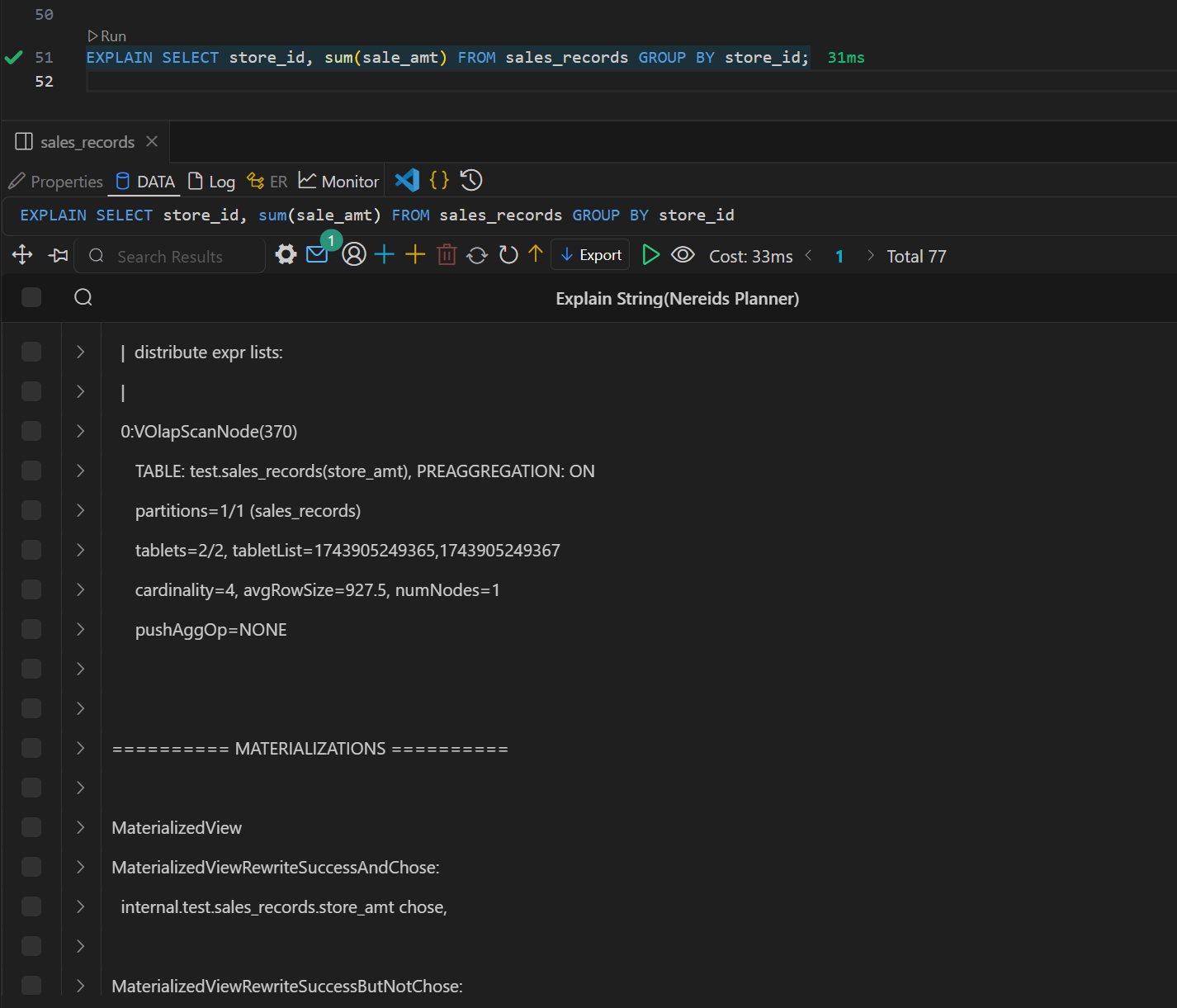 tn2>测试一下没有添加物化视图的sql: ```sql EXPLAIN select seller_id, sum(sale_amt) from sales_records group by seller_id; ``` 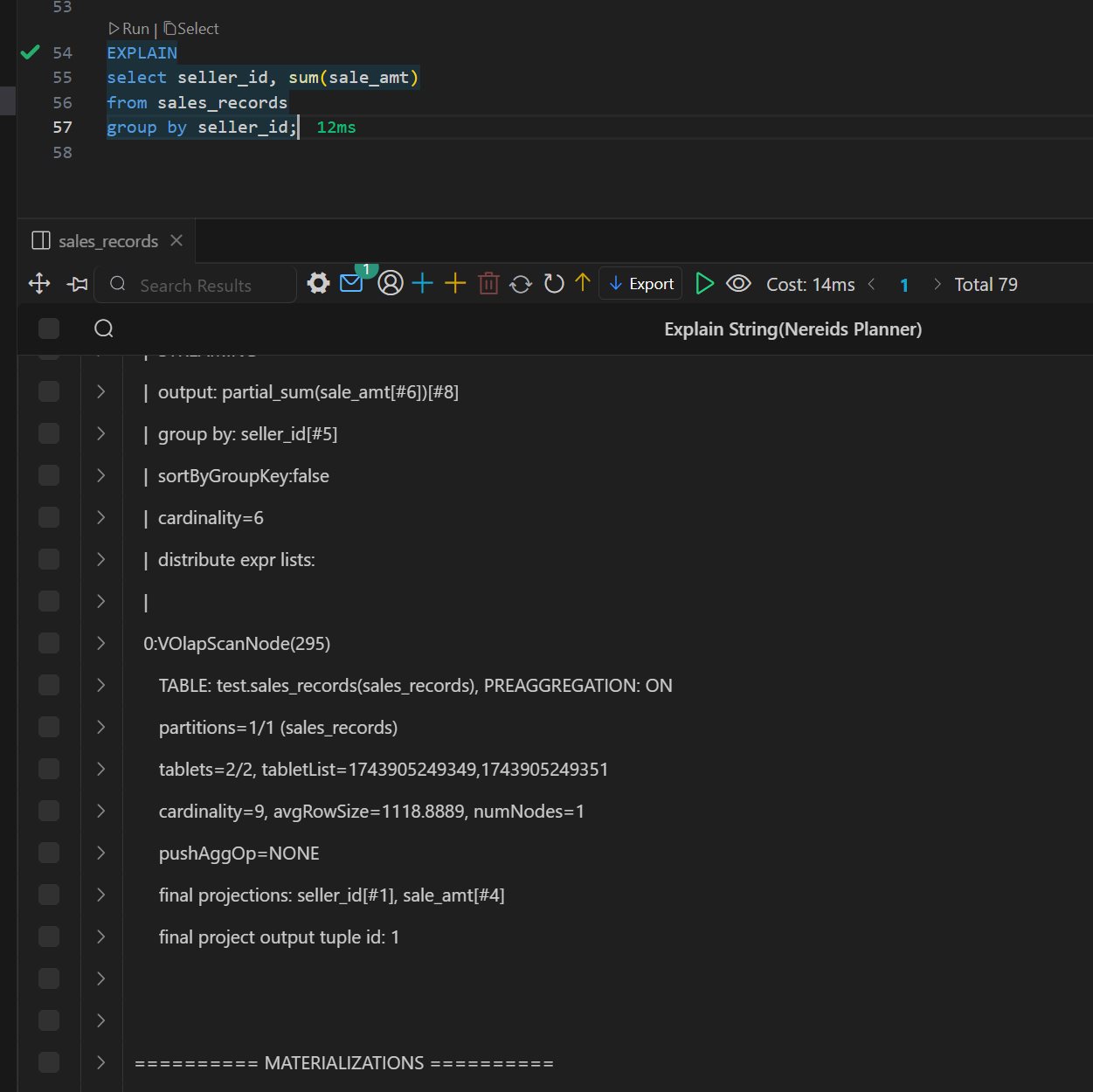 tn2>删除物化视图语法 ```sql -- 语法: DROP MATERIALIZED VIEW 物化视图名 on base_table_name; --示例: drop materialized view store_amt on sales_records; ```  案例一:计算广告的 pv、uv ------------ tn2>pv : 整个网站的网页访问量 uv: 一个网站的访问人数 tn2>用户有一张点击广告的明细数据表 需求:针对用户点击计广告明细数据的表,算每天,每个页面,每个渠道的 pv,uv `pv:page view`,页面浏览量或点击量 `uv:unique view`,通过互联网访问、浏览这个网页的自然人 ```sql drop table if exists ad_view_record; create table ad_view_record( dt date, ad_page varchar(10), channel varchar(10), refer_page varchar(10), user_id int ) distributed by hash(dt) properties("replication_num" = "1"); ``` tn2>插入数据 ```sql insert into ad_view_record values ('2020-02-02','a','app','/home',1), ('2020-02-02','a','web','/home',1), ('2020-02-02','a','app','/addbag',2), ('2020-02-02','b','app','/home',1), ('2020-02-02','b','web','/home',1), ('2020-02-02','b','app','/addbag',2), ('2020-02-02','b','app','/home',3), ('2020-02-02','b','web','/home',3), ('2020-02-02','c','app','/order',1), ('2020-02-02','c','app','/home',1), ('2020-02-03','c','web','/home',1), ('2020-02-03','c','app','/order',4), ('2020-02-03','c','app','/home',5), ('2020-02-03','c','web','/home',6), ('2020-02-03','d','app','/addbag',2), ('2020-02-03','d','app','/home',2), ('2020-02-03','d','web','/home',3), ('2020-02-03','d','app','/addbag',4), ('2020-02-03','d','app','/home',5), ('2020-02-03','d','web','/addbag',6), ('2020-02-03','d','app','/home',5), ('2020-02-03','d','web','/home',4); ``` tn2>创建物化视图 ```sql -- 怎么去计算pv,uv select dt,ad_page,channel, count(ad_page) as pv, count(distinct user_id) as uv from ad_view_record group by dt,ad_page,channel; -- 1.物化视图中,不能够使用两个相同的字段 -- 2.在增量聚合里面,不能够使用count(distinct) ==> bitmap_union -- 3.count(字段) create materialized view dpc_pv_uv as select dt,ad_page,channel, -- refer_page 没有null的情况 count(refer_page) as pv, -- doris的物化视图中,不支持count(distint) ==> bitmap_union -- count(distinct user_id) as uv bitmap_union(to_bitmap(user_id)) uv_bitmap from ad_view_record group by dt,ad_page,channel; //1. count(必须加字段名) 不能写count(1) //2.同一个字段在物化视图的sql逻辑中不能出现两次 //3. count(distinct) 不能使用。需要用bitmap_union来代替 create materialized view tpc_pv_uv as select dt,ad_page,channel, count(refer_page) as pv, -- refer_page 不能为null -- count(user_id) as pv -- count(1) as pv, bitmap_union(to_bitmap(user_id)) as uv_bitmap --count(distinct user_id) as uv from ad_view_record group by dt,ad_page,channel; --结论:在doris的物化视图中,一个字段不能用两次,并且聚合函数后面必须跟字段名称 ``` tn2>在 Doris 中,count(distinct) 聚合的结果和 bitmap_union_count 聚合的结果是完全一致的。而 bitmap_union_count 等于 bitmap_union 的结果求 count,所以如果查询中涉及到count(distinct) 则通过创建带 bitmap_union 聚合的物化视图方可加快查询。因为本身 user_id 是一个 INT 类型,所以在 Doris 中需要先将字段通过函数 to_bitmap 转换为 bitmap 类型然后才可以进行 bitmap_union 聚合。 查询自动匹配 ```sql explain select dt,ad_page,channel, count(refer_page) as pv, count(distinct user_id) as uv from ad_view_record group by dt,ad_page,channel; ``` 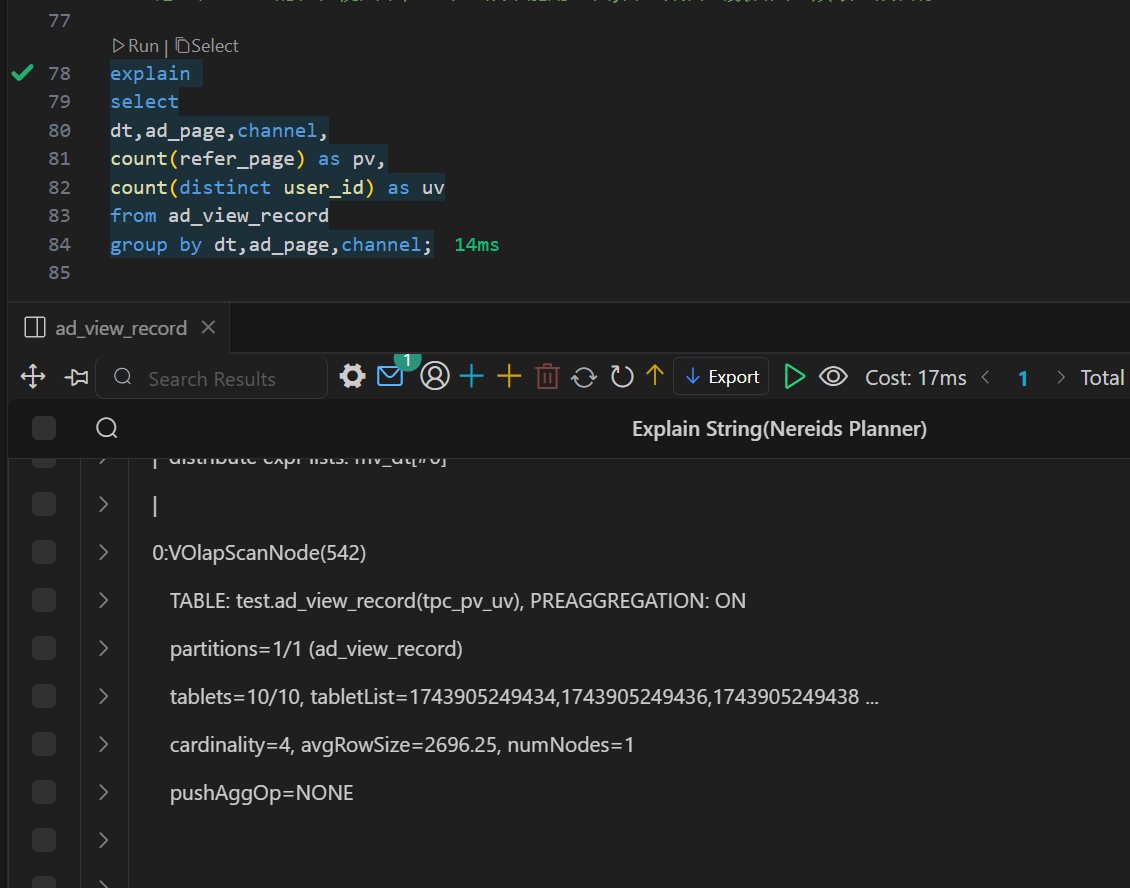 tn2>用到了物化视图 ```sql explain select dt,ad_page,channel, count(1) as pv, bitmap_union_count(to_bitmap(user_id)) as uv from ad_view_record group by dt,ad_page,channel; ``` 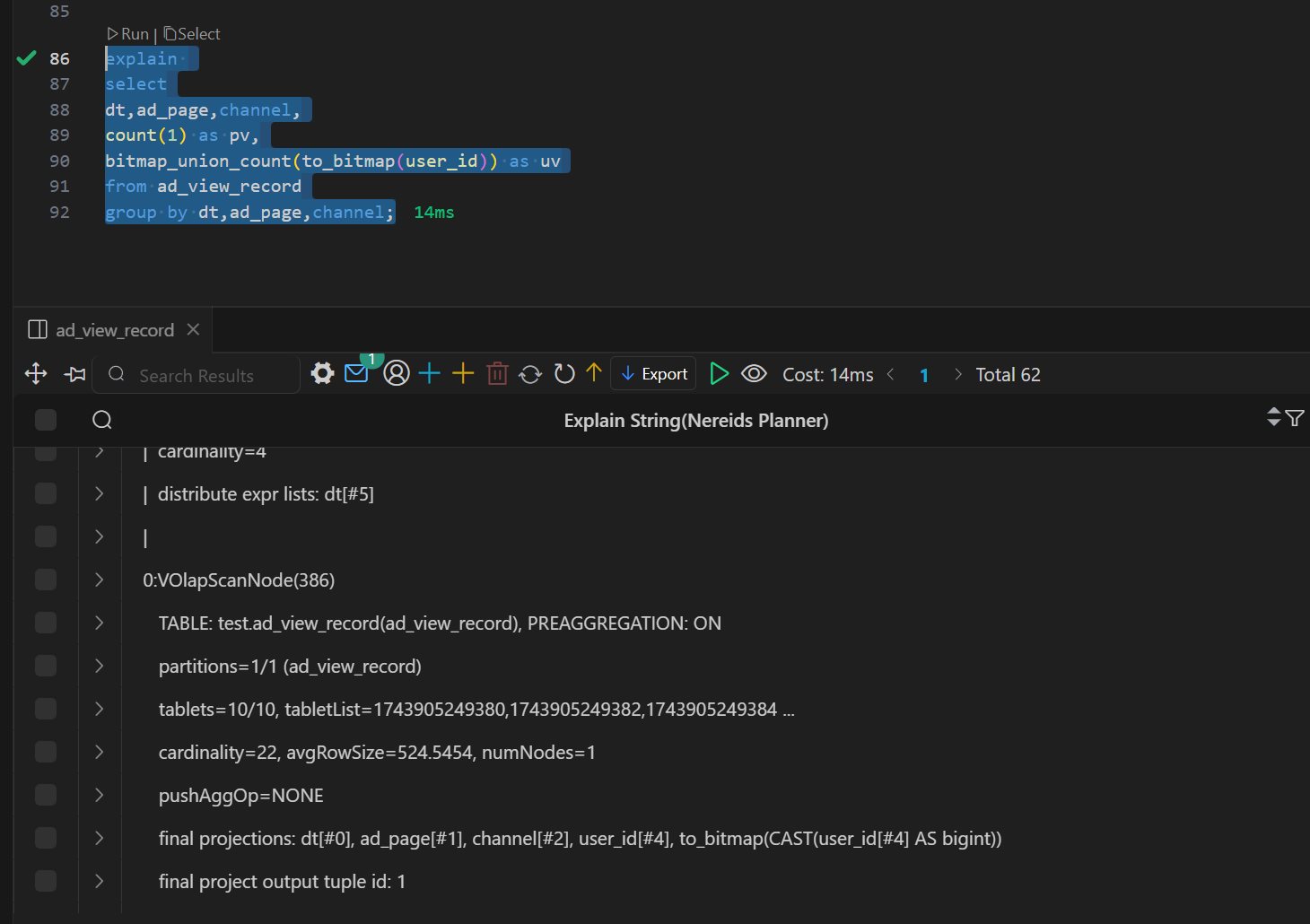 tn2>这样查询没有用到物化视图。 当然,我们还可以根据日期和页面的维度再去创建一张物化视图 ```sql create materialized view tp_pv_uv as select dt,ad_page, count(refer_page) as pv, bitmap_union(to_bitmap(user_id)) as uv from ad_view_record group by dt,ad_page; ``` tn2>再去执行上面的sql,显然命中的就是tp_pv_uv这个物化视图 ```sql explain select dt,ad_page, count(refer_page) as pv, count(distinct user_id) as uv from ad_view_record group by dt,ad_page; -- TABLE: ad_view_record_1(tp_pv_uv), PREAGGREGATION: ON explain select dt, count(refer_page) as pv, count(distinct user_id) as uv from ad_view_record group by dt; ``` 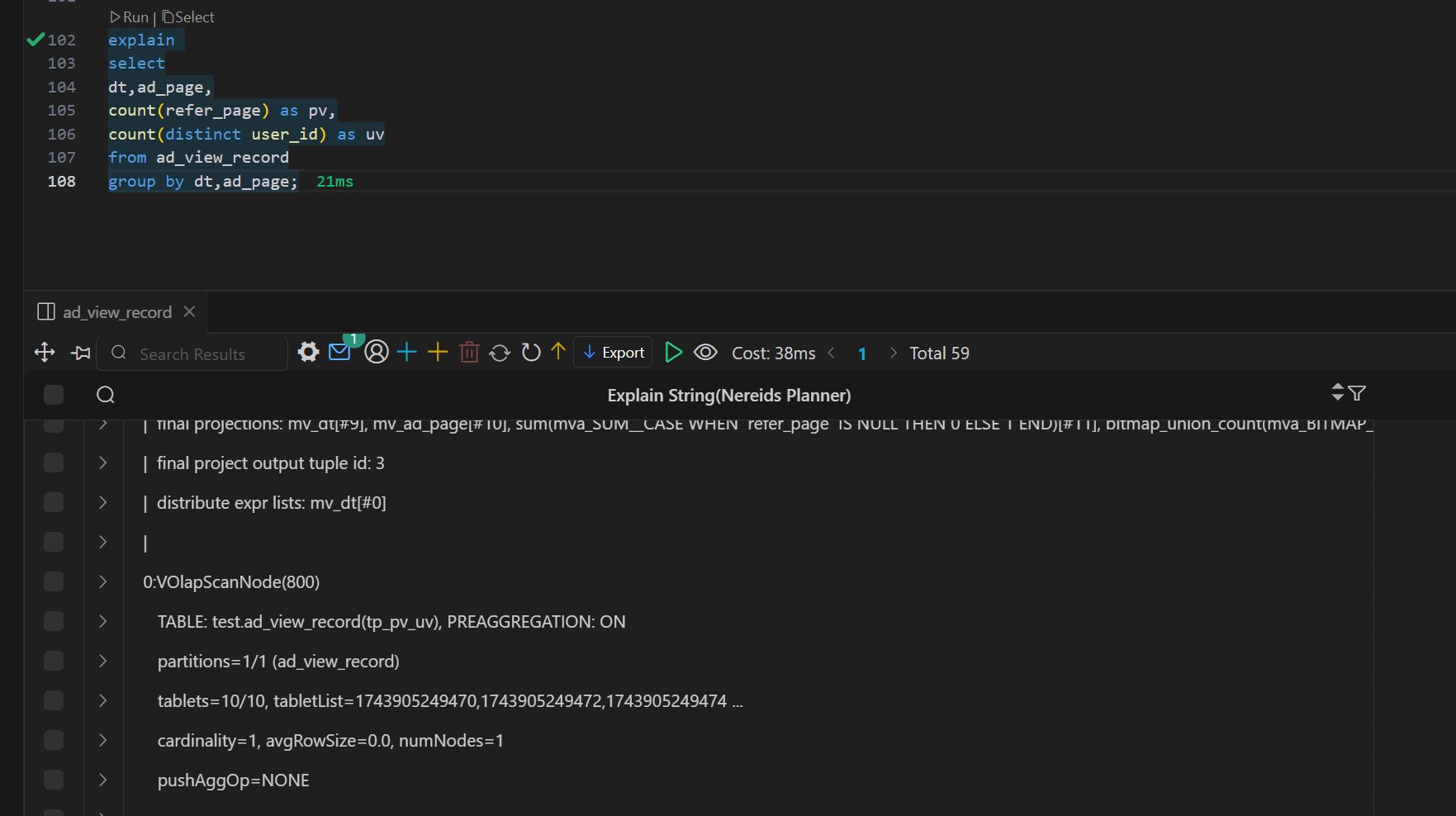 tn2>总结: 1.在创建doris的物化视图中,同一个字段不能被使用两次,并且聚合函数后面必须跟字段名称(不能使用count(1)这样的聚合逻辑) 2.doris在选择使用哪一个物化视图表的时候,按照维度上卷rollup的原则,选距离查询维度最接近,并且指标可以复用的物化视图. 3.一张基表可以创建多个物化视图(计算资源占用比较多) 案例二:调整前缀索引 ------------ tn2>场景:用户的原始表有(k1, k2, k3)三列。其中 k1, k2 为前缀索引列。 这时候如果用户查询条件中包含 where k1=1 and k2=2 就能通过索引加速查询。 但是有些情况下,用户的过滤条件无法匹配到前缀索引,比如 where k3=3。则无法通过索引提升查询速度。 解决方法: 创建以 k3 作为第一列的物化视图就可以解决这个问题。 查询 ```sql desc sales_records all; ``` 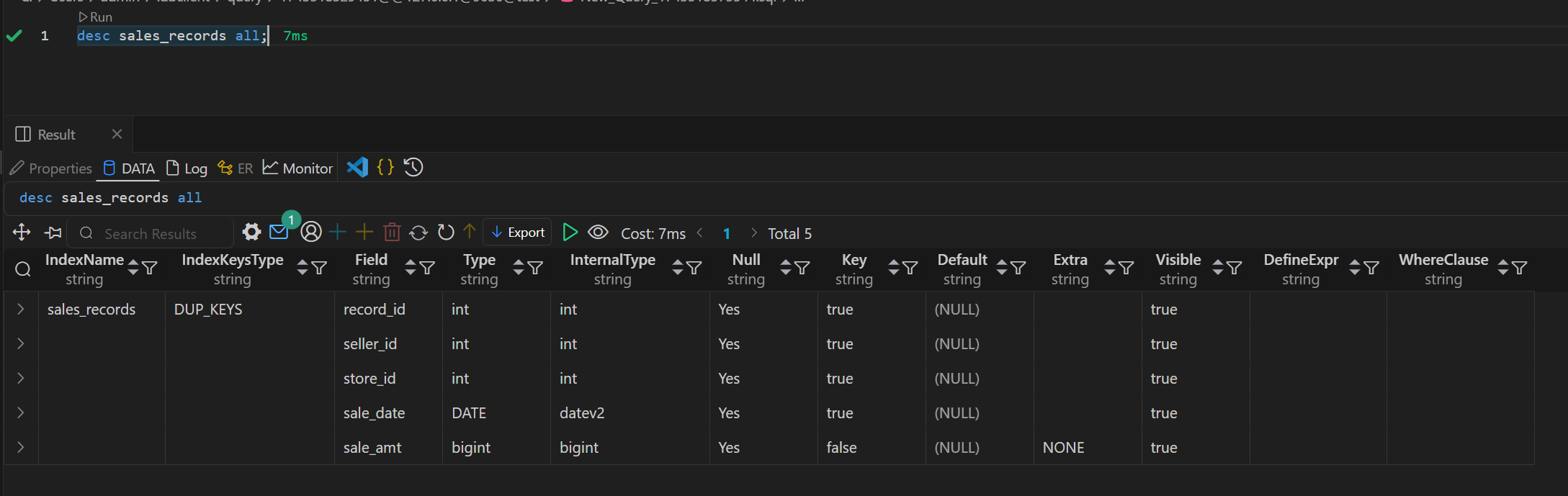 tn2>针对上面的前缀索引情况,执行下面的sql是无法利用前缀索引的 ```sql explain select record_id,seller_id,store_id from sales_records where store_id=3; ``` 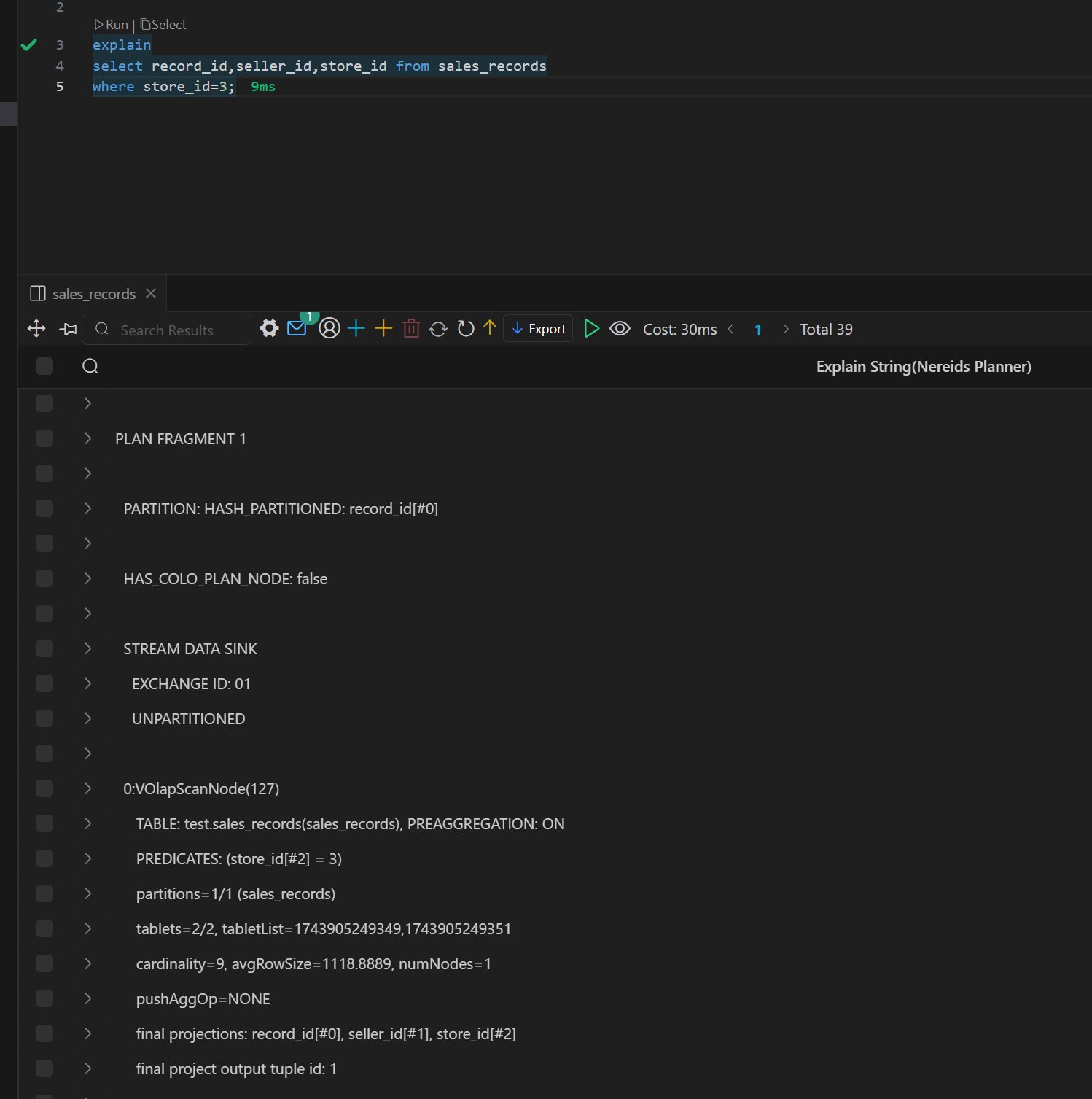 tn2>创建物化视图 ```sql create materialized view sto_rec_sell as select store_id, record_id, seller_id, sale_date, sale_amt from sales_records; ``` tn2>通过上面语法创建完成后,物化视图中既保留了完整的明细数据,且物化视图的前缀索 引为 store_id 列。 3)查看表结构 ```sql desc sales_records all; ``` 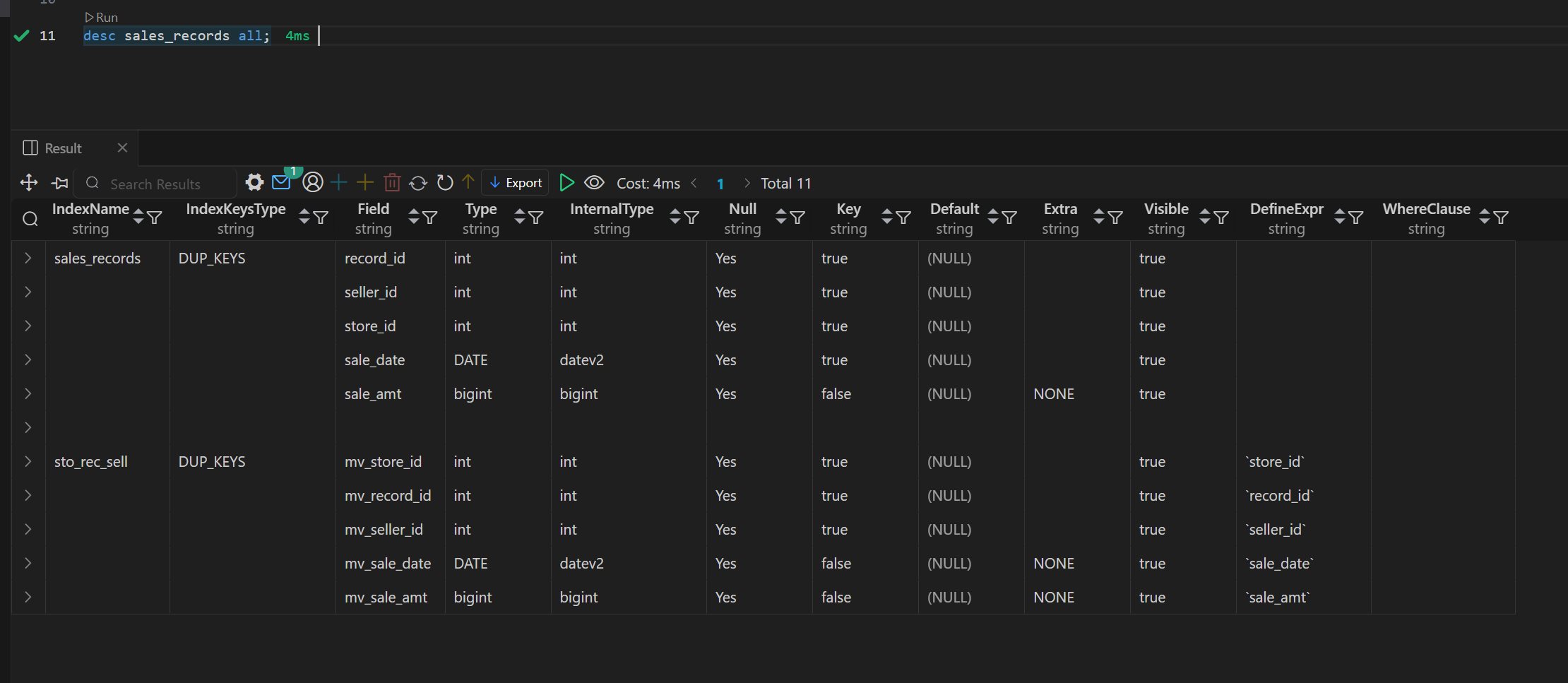 tn2>查询匹配 ```sql explain select record_id,seller_id,store_id from sales_records where store_id=3; ``` 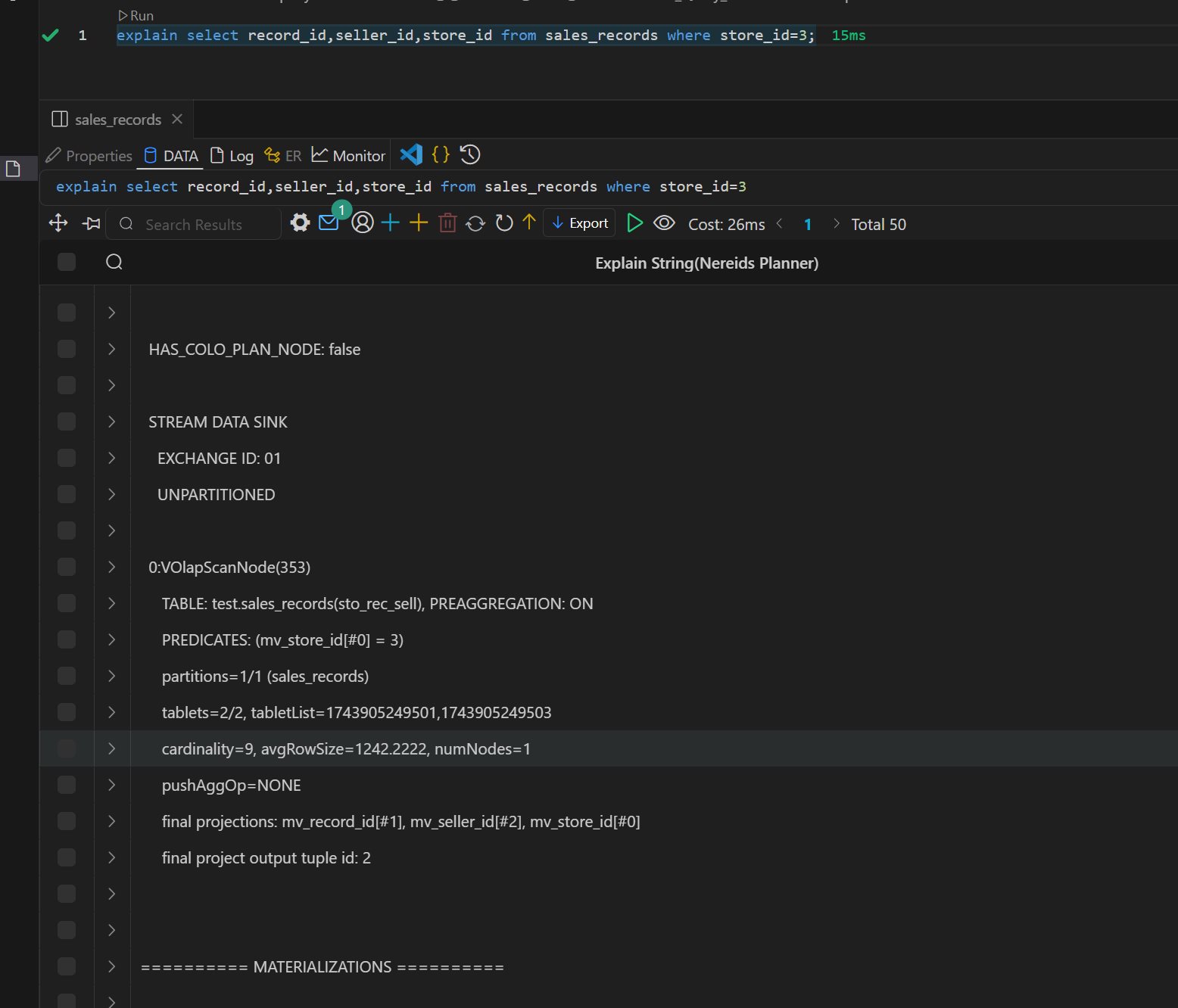 tn2>这时候查询就会直接从刚才创建的sto_rec_sell物化视图中读取数据。物化视图对 store_id是存在前缀索引的,查询效率也会提升。

