Doris 索引(学习笔记) 电脑版发表于:2025/4/2 10:40  >#Doris 索引(学习笔记) [TOC] 索引 ------------ tn2>索引用于帮助快速过滤或查找数据。 目前 Doris 主要支持两类索引: ● 内建的智能索引:包括前缀索引和 ZoneMap 索引。 ● 用户创建的二级索引:包括 Bloom Filter 索引 和 Bitmap倒排索引。 其中 ZoneMap 索引是在列存格式上,对每一列自动维护的索引信息,包括 Min/Max,Null 值个数等等。 这种索引对用户透明。 ### 前缀索引 tn2>doris中,对于前缀索引有如下约束: 1.他的索引键最大长度是36个字节 2.当他遇到了varchar数据类型的时候,即使没有超过36个字节,也会自动截断 ● 示例1:以下表中我们定义了: user_id,age,message作为表的key ; 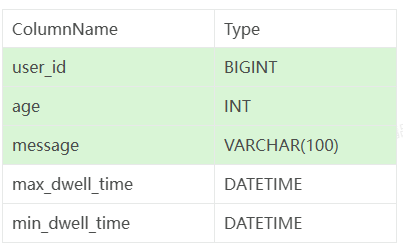 tn2>那么,doris为这个表创建前缀索引时,它生成的索引键如下: ```bash user_id(8 Bytes) + age(4 Bytes) + message(prefix 24 Bytes) ``` tn2>示例2:以下表中我们定义了:age,user_name,message作为表的key 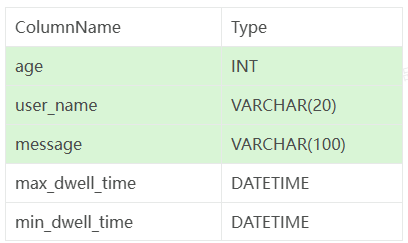 tn2>那么,doris为这个表创建前缀索引时,它生成的索引键如下: ```bash age(4 Bytes) +user_name(20 Bytes) 指定key的时候 ``` tn2>为什么是这个结果呢? 虽然还没有超过36个字节,但是已经遇到了一个varchar字段,它自动截断,不会再往后面取了 当我们的查询条件,是前缀索引的前缀时,可以极大的加快查询速度。比如在第一个例子中,我们执行如下查询: ```bash SELECT * FROM table WHERE user_id=1829239 and age=20 ``` tn2>该查询的效率会远高于以下查询: ```bash SELECT * FROM table WHERE age=20; ``` tn2>所以在建表时,正确的选择列顺序,能够极大地提高查询效率。 ### Bloom Filter 索引 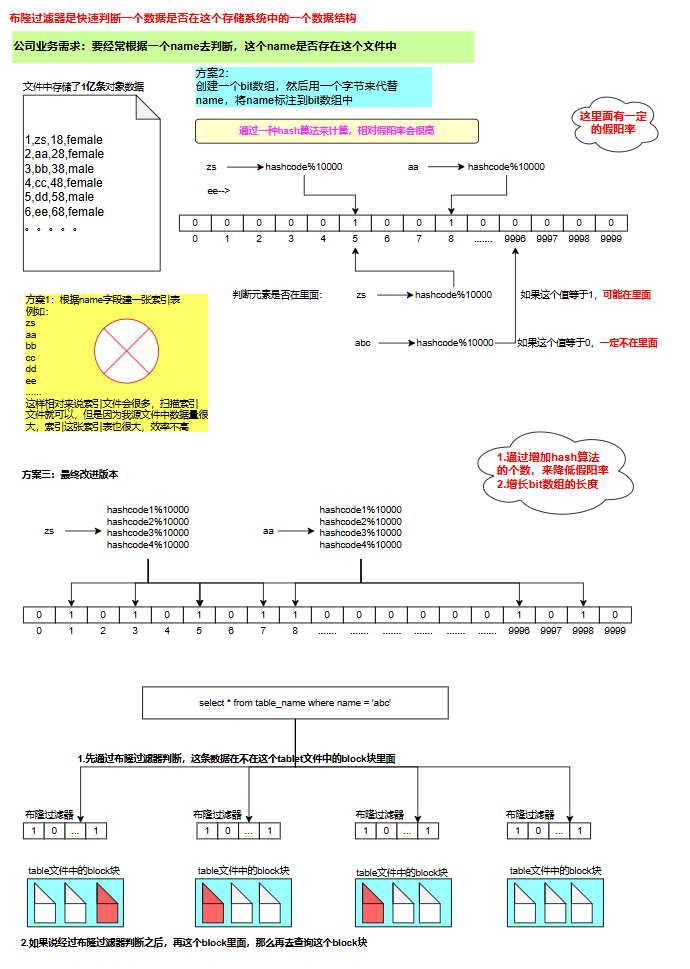 tn2>小总结: 1.Bloom Filter 本质上是一种位图结构,用于判断一个值是否存在 2.会产生小概率的误判,因为hash算法天生的碰撞 3.在doris中是以tablet为粒度创建的,给每一个tablet创建一个布隆过滤器索引 ### 如何创建BloomFilter索引? tn2>建表的时候指定 ```bash PROPERTIES ( "bloom_filter_columns"="name,age,uid" ) ``` tn2>alter修改表的时候指定 ```bash ALTER TABLE sale_detail_bloom SET ("bloom_filter_columns" = "k1,k3"); ALTER TABLE sale_detail_bloom SET ("bloom_filter_columns" = "k1,k4"); ALTER TABLE sale_detail_bloom SET ("bloom_filter_columns" = ""); -- 删除已经存在的布隆过滤器 ``` tn2>简单示例 ```bash CREATE TABLE IF NOT EXISTS sale_detail_bloom ( sale_date date NOT NULL COMMENT "销售时间", customer_id int NOT NULL COMMENT "客户编号", saler_id int NOT NULL COMMENT "销售员", sku_id int NOT NULL COMMENT "商品编号", category_id int NOT NULL COMMENT "商品分类", sale_count int NOT NULL COMMENT "销售数量", sale_price DECIMAL(12,2) NOT NULL COMMENT "单价", sale_amt DECIMAL(20,2) COMMENT "销售总金额" ) Duplicate KEY(sale_date, customer_id,saler_id,sku_id,category_id) PARTITION BY RANGE(sale_date) ( PARTITION P_202111 VALUES [('2021-11-01'), ('2021-12-01')) ) DISTRIBUTED BY HASH(saler_id) BUCKETS 1 PROPERTIES("replication_num" = "1"); ``` tn2>查看BloomFilter索引 ```bash SHOW CREATE TABLE sale_detail_bloom ``` 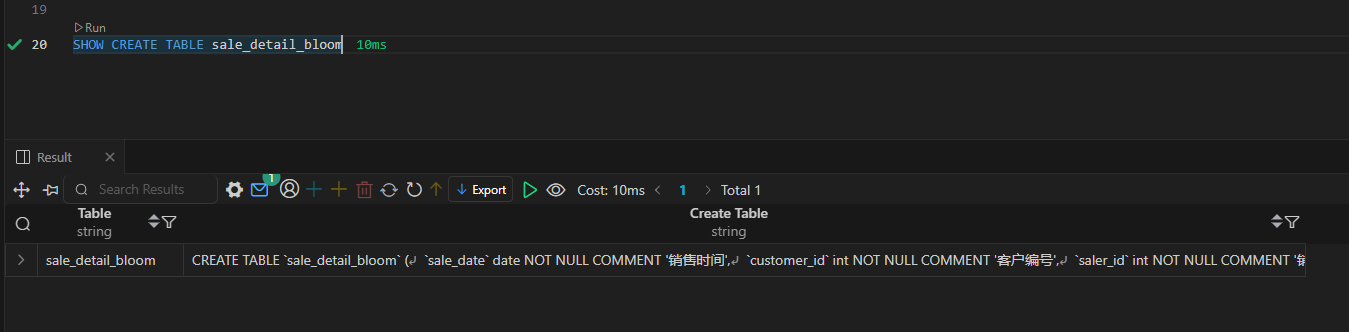 tn2>修改/删除BloomFilter索引 ```bash ALTER TABLE sale_detail_bloom SET ("bloom_filter_columns" = "customer_id,saler_id"); ```  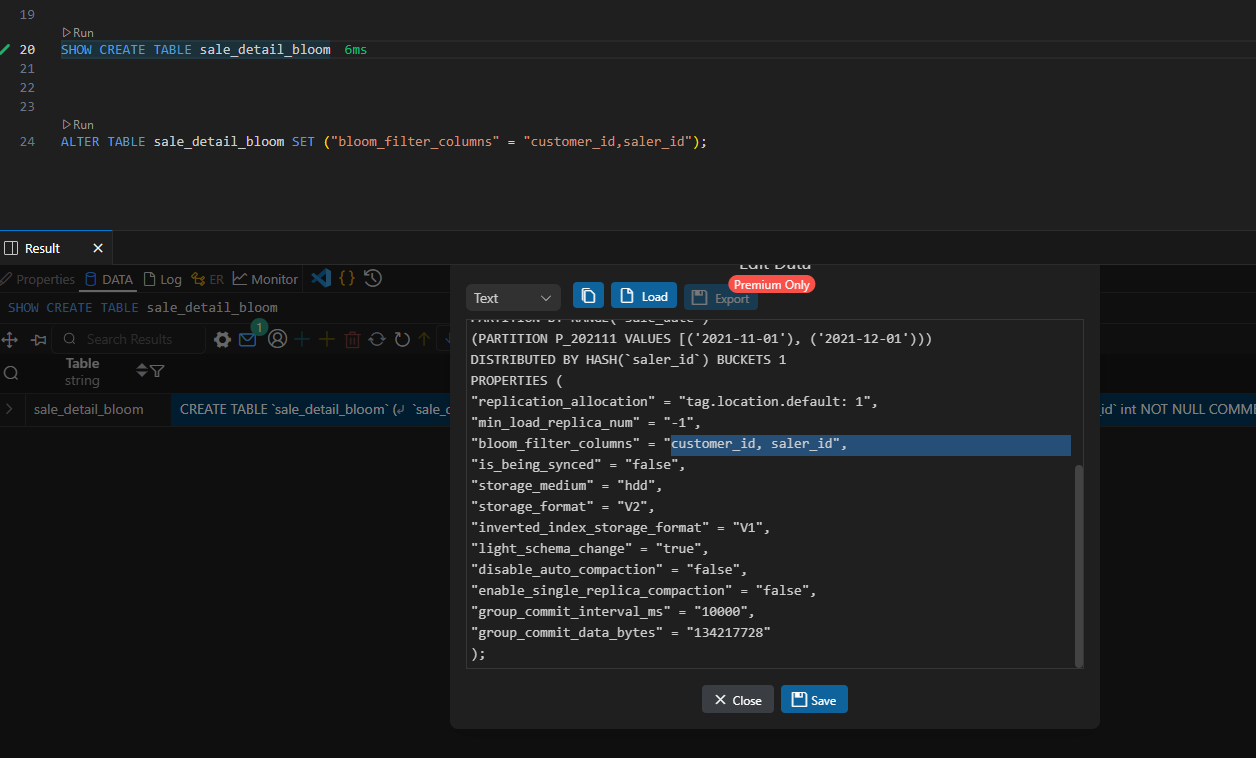 ### Doris BloomFilter适用场景 tn2>满足以下几个条件时可以考虑对某列建立Bloom Filter 索引: 1.BloomFilter是在无法利用前缀索引的查询场景中,来加快查询速度的。 2.查询会根据该列高频过滤,而且查询条件大多是 in 和 = 过滤。 3.不同于Bitmap, BloomFilter适用于高基数列。比如UserID。因为如果创建在低基数的列上,比如 “性别” 列,则每个Block几乎都会包含所有取值,导致BloomFilter索引失去意义。字段随机 tn>BloomFilter使用注意事项: 1.不支持对Tinyint、Float、Double 类型的列建Bloom Filter索引。 2.Bloom Filter索引只对 in 和 = 过滤查询有加速效果。 ### Bitmap 索引 tn2>用户可以通过创建bitmap index 加速查询 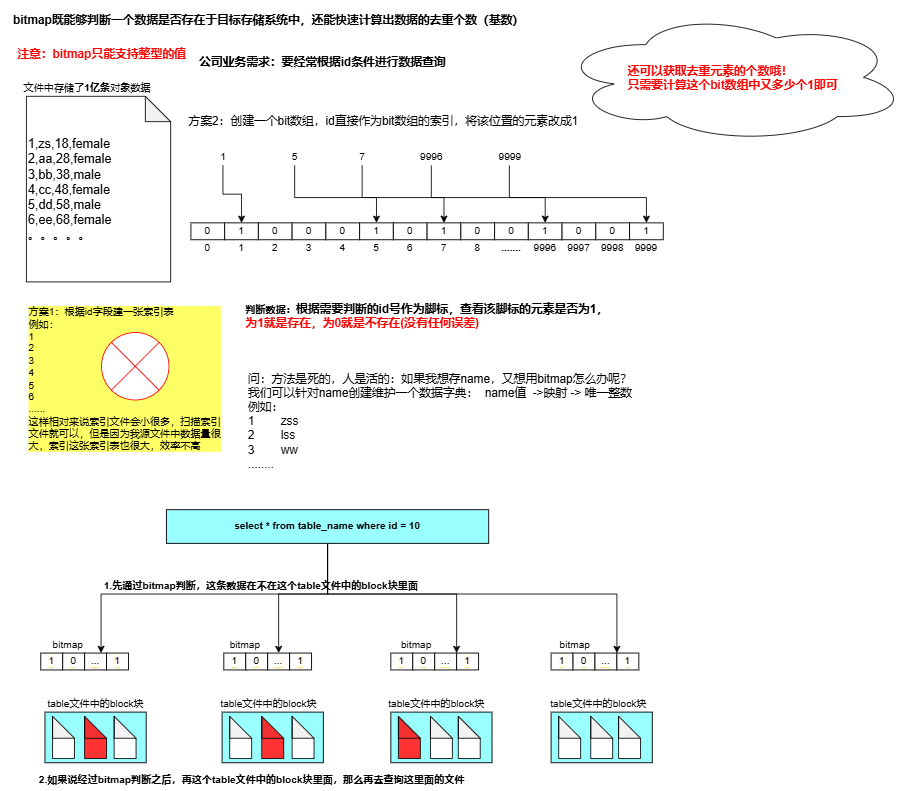 tn2>创建索引 在table1 上为siteid 创建bitmap 索引 ```bash CREATE INDEX [IF NOT EXISTS] index_name ON table1 (siteid) USING BITMAP COMMENT '注释'; create index 索引名称 on 表名(给什么字段创建bitmap索引) using bitmap COMMENT '注释'; create index user_id_bitmap on sale_detail_bloom(sku_id) USING BITMAP COMMENT '使用user_id创建的bitmap索引'; ``` 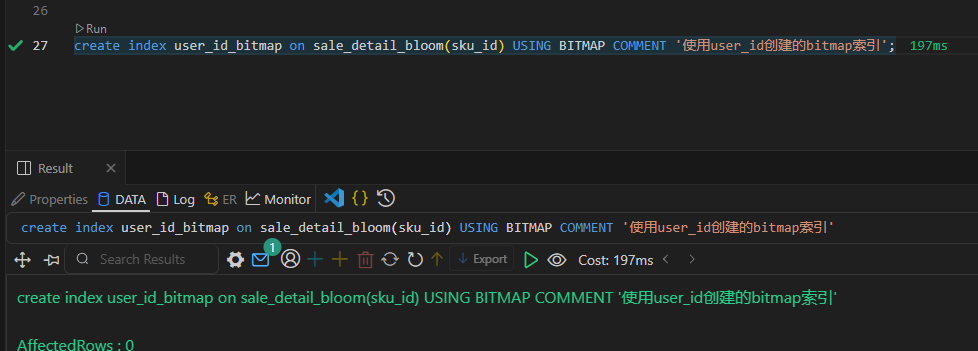 tn2>查看索引 ```bash SHOW INDEX FROM test.sale_detail_bloom; ```  tn2>删除索引 ```bash DROP INDEX [IF EXISTS] index_name ON [db_name.]table_name; ``` tn>注意事项 bitmap 索引仅在单列上创建。 bitmap 索引能够应用在 Duplicate、Uniq 数据模型的所有列和 Aggregate模型的key列上。 bitmap 索引支持的数据类型如下:(老版本只支持bitmap类型) `TINYINT,SMALLINT,INT,BIGINT,CHAR,VARCHAR,DATE,DATETIME,LARGEINT,DECIMAL,BOOL` bitmap索引仅在 Segment V2 下生效(Segment V2是升级版本的文件格式)。当创建 index 时,表的存储格式将默认转换为 V2 格式

