Doris 数据的导入导出(学习笔记) 电脑版发表于:2025/3/5 15:26  >#Doris 数据的导入导出(学习笔记) [TOC] 使用 Insert 方式同步数据 ------------ tn2>用户可以通过 MySQL 协议,使用 INSERT 语句进行数据导入。 INSERT 语句的使用方式和 MySQL 等数据库中 INSERT 语句的使用方式类似。 INSERT 语句支持以下两种语法: ```sql * INSERT INTO table SELECT ... * INSERT INTO table VALUES(...) ``` tn2>对于 Doris 来说,一个 INSERT 命令就是一个完整的导入事务。 因此不论是导入一条数据,还是多条数据,我们**都不建议在生产环境使用这种方式进行数据导入**。高频次的 INSERT 操作会导致在存储层产生大量的小文件,会严重影响系统性能。 **该方式仅用于线下简单测试或低频少量的操作。** 或者可以使用以下方式进行批量的插入操作: ```sql INSERT INTO example_tbl VALUES (1000, "baidu1", 3.25) (2000, "baidu2", 4.25) (3000, "baidu3", 5.25); ``` 导入本地数据 ------------ tn2>Stream Load 用于将本地文件导入到doris中。Stream Load 是通过 HTTP 协议与 Doris 进行连接交互的。 该方式中涉及 HOST:PORT 都是对应的HTTP 协议端口。 BE 的 HTTP 协议端口,默认为 8040。 FE 的 HTTP 协议端口,默认为 8030。<br/> **但须保证客户端所在机器网络能够联通FE, BE 所在机器。** 基本原理:  tn2>1. 创建一张表 建表语句: ```sql drop table if exists load_local_file_test; CREATE TABLE IF NOT EXISTS test.load_local_file_test ( id INT, name VARCHAR(50), age TINYINT ) unique key(id) DISTRIBUTED BY HASH(id) BUCKETS 3 PROPERTIES ( "replication_num" = "1" ); ``` 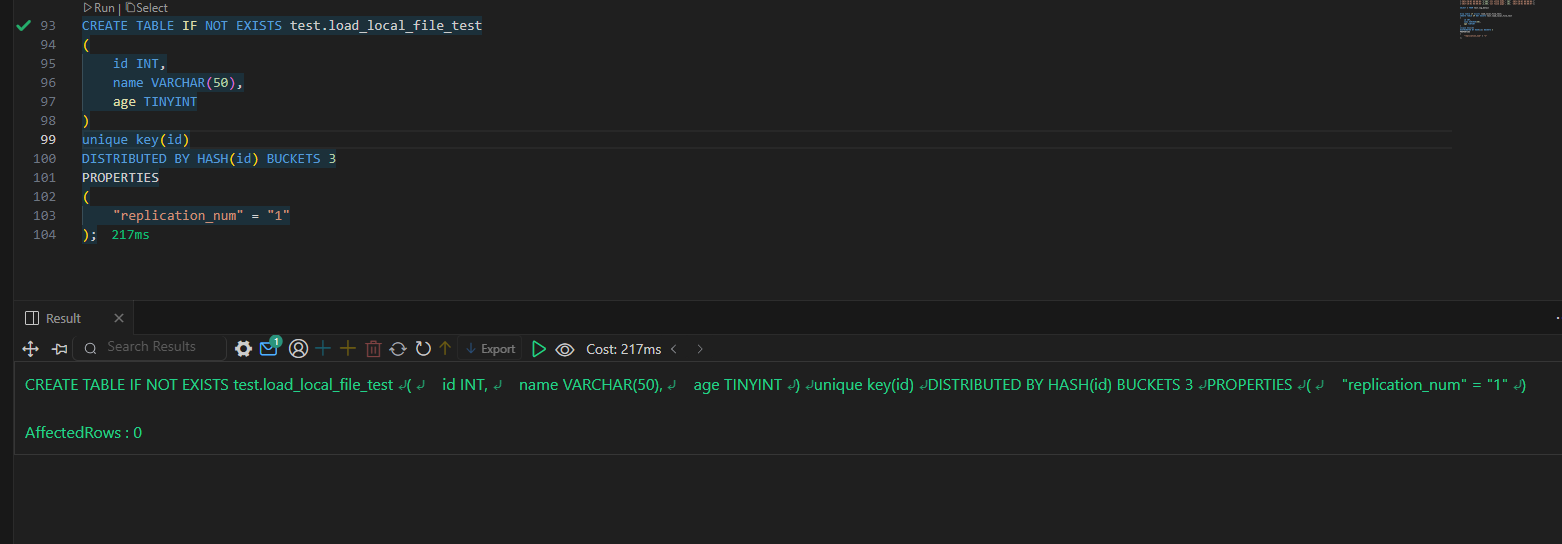 tn2>创建一个`loadfile.txt`的记事本文件,写入如下数据: ```sql 1,zss,28 2,lss,28 3,ww,88 ``` tn2>导入数据 执行 curl 命令导入本地文件: ```bash # 语法示例 curl \ -u user:passwd \ # 账号密码 -H "label:load_local_file_test" \ # 本次任务的唯一标识 -T 文件地址 \ http://主机名:端口号/api/库名/表名/_stream_load curl -u root: -H "label:load_local_file" -H "column_separator:," -T "C:\Users\bob.he\OneDrive - Oerlikon Group\Desktop\project\Doris\loadfile.txt" http://127.0.0.1:8040/api/test/load_local_file_test/_stream_load ``` | 参数 | 描述 | | ------------ | ------------ | | `user:passwd` | 为在 Doris 中创建的用户。初始用户为 root,密码初始状态下为空,[如果有设置以实际为准]。 | | `host:port` | 为 BE 的 HTTP 协议端口,默认是 8040,可以在 Doris 集群 WEB UI页面查看。 | | `label` | 可以在 Header 中指定 Label 唯一标识这个导入任务 | 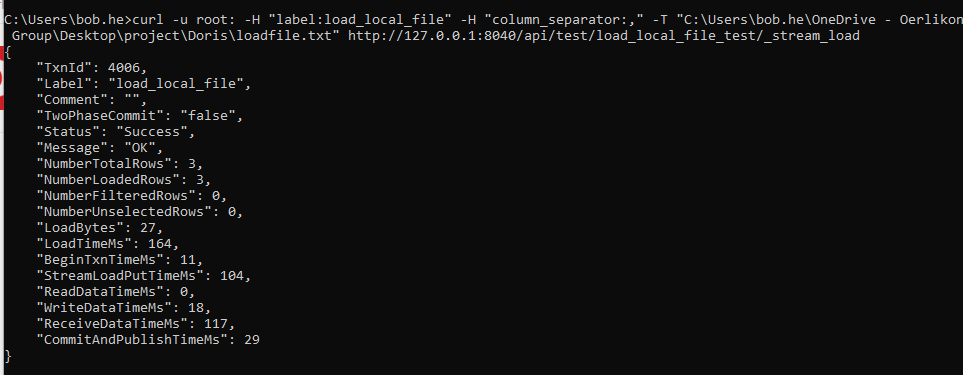 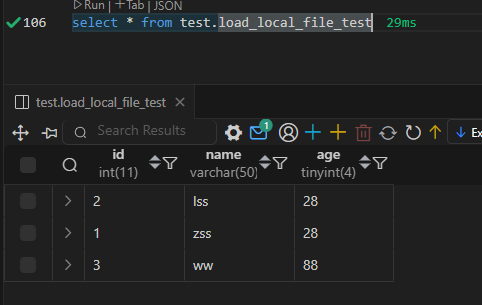 curl的一些可配置的参数 ------------ | 参数 | 描述 | | ------------ | ------------ | | `label` | 导入任务的标签,相同标签的数据无法多次导入。(标签默认保留30分钟) | | `column_separator` | 用于指定导入文件中的列分隔符,默认为\t。 | | `line_delimiter` | 用于指定导入文件中的换行符,默认为\n。 | | `columns` | 用于指定文件中的列和table中列的对应关系,默认一一对应<br/>例1: 表中有3个列`c1, c2, c3`,源文件中的三个列一次对应的是`c3,c2,c1`; 那么需要指定`-H "columns: c3, c2, c1"`<br/> 例2: 表中有3个列`c1, c2, c3`, 源文件中前三列依次对应,但是有多余1列;那么需要指定`-H "columns: c1, c2, c3, xxx"`;最后一个列随意指定个名称占位即可<br/>例3: 表中有3个列`year,month,day`三个列,源文件中只有一个时间列,为`2018-06-01 01:02:03`格式;那么可以指定`-H "columns: col, year = year(col), month=month(col), day=day(col)"`完成导入 | | `where` | 用来过滤导入文件中的数据<br/>例1: 只导入大于k1列等于20180601的数据,那么可以在导入时候指定`-H "where: k1 = 20180601"` | | `max_filter_ratio` | 最大容忍可过滤(数据不规范等原因)的数据比例。默认零容忍。数据不规范不包括通过 where 条件过滤掉的行。举例:`0.1`就是`10%`被过滤掉的数据不能超过总数据的10% | | `partitions` | 用于指定这次导入所设计的partition。如果用户能够确定数据对应的partition,推荐指定该项。不满足这些分区的数据将被过滤掉。<br/>比如指定导入到p1, p2分区,`-H "partitions: p1, p2"` | | `timeout` | 指定导入的超时时间。单位秒。默认是 600 秒。可设置范围为 1 秒 ~ 259200 秒 | | `timezone` | 指定本次导入所使用的时区。默认为东八区。该参数会影响所有导入涉及的和时区有关的函数结果 | | `exec_mem_limit` | 导入内存限制。默认为 2GB。单位为字节。 | | `format` | 指定导入数据格式,默认是csv,支持json格式。 | | `read_json_by_line` | 布尔类型,为true表示支持每行读取一个json对象,默认值为false。 | | `merge_type` | 数据的合并类型,一共支持三种类型`APPEND`、`DELETE`、`MERGE` 其中,<br/>`APPEND`是默认值,表示这批数据全部需要追加到现有数据中。<br/>`DELETE` 表示删除与这批数据key相同的所有行。<br/>`MERGE` 语义 需要与delete 条件联合使用,表示满足delete 条件的数据按照DELETE 语义处理其余的按照APPEND语义处理,示例:`-H "merge_type: MERGE" -H "delete: flag=1"` | | `delete` | 仅在 MERGE下有意义, 表示数据的删除条件 `function_column.sequence_col`: 只适用于UNIQUE_KEYS,相同key列下,保证value列按照source_sequence列进行REPLACE, source_sequence可以是数据源中的列,也可以是表结构中的一列。 | tn2>这里我们做个简单的示范,首先创建一个`json.txt`的json数据,数据如下: ```bash {"id":1,"name":"zs","age":18} {"id":2,"name":"lisi","age":18} {"id":3,"name":"ww","age":18} {"id":4,"name":"zl","age":18} {"id":5,"name":"tq","age":18} ``` tn2>然后我们举个例子,使用 root 用户和空密码,将本地 JSON 文件(`json.txt`)导入到 Doris 数据库中,设置了任务标签为 load_local_file_json_20221126,列名为 id、name、age,允许最多 10% 的数据被过滤,超时时间为 1000 秒,只导入 id 大于 1 的数据,数据格式为 JSON,逐行读取 JSON 文件,并在导入时删除旧数据。 ```bash curl -u root: -H "label:load_local_file_json_20221126" -H "columns:id,name,age" -H "max_filter_ratio:0.1" -H "timeout:1000" -H "where:id>1" -H "format:json" -H "read_json_by_line:true" -H "merge_type:delete" -T "C:\Users\bob.he\OneDrive - Oerlikon Group\Desktop\project\Doris\json.txt" http://127.0.0.1:8040/api/test/load_local_file_test/_stream_load ``` 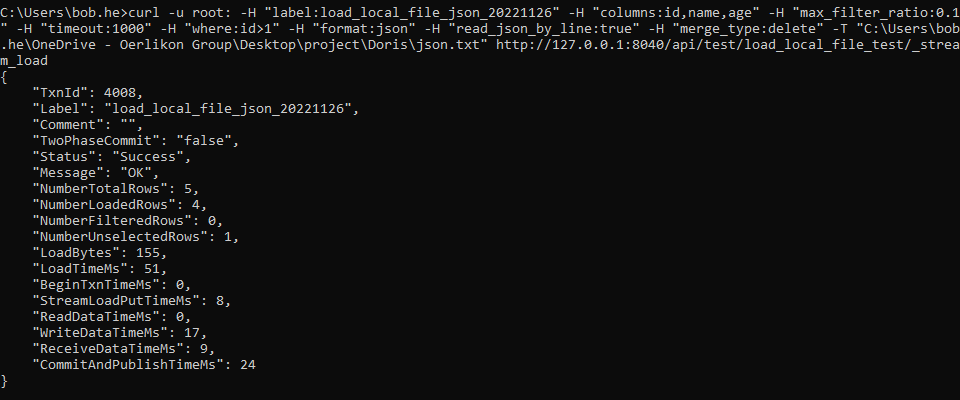 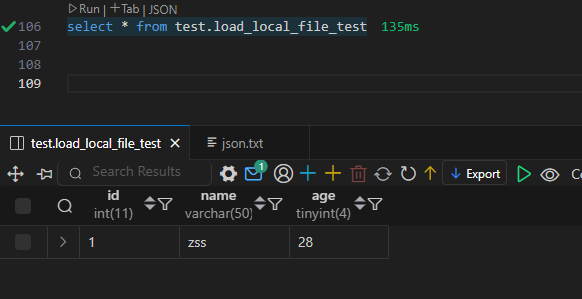 tn2>我们发现只有1条数据了,原因是我们导入的数据id大于1的数据,所以id为1的在原来的数据中不受影响。 但是在2和3本身就存在数据了所以由于冲突直接删除数据,4和5数据并没有添加。 如果我们希望添加就直接将`merge_type`改成`append`,当冲突时会进行追加的,然后将`label`改成改一下: ```bash curl -u root: -H "label:load_local_file_json_20221128" -H "columns:id,name,age" -H "max_filter_ratio:0.1" -H "timeout:1000" -H "where:id>1" -H "format:json" -H "read_json_by_line:true" -H "merge_type:append" -T "C:\Users\bob.he\OneDrive - Oerlikon Group\Desktop\project\Doris\json.txt" http://127.0.0.1:8040/api/test/load_local_file_test/_stream_load ``` 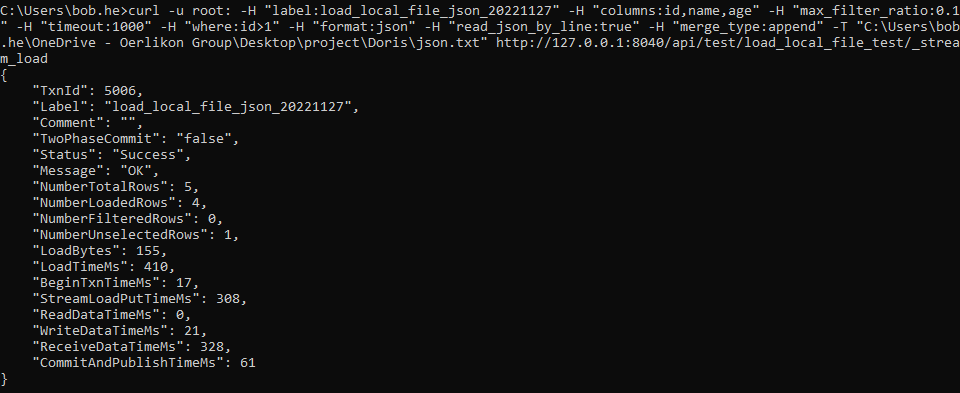 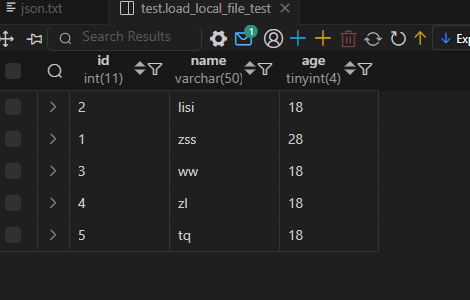 tn>由于我们这里的表结构是`unique`所以如果再次添加由于key相同的关系会覆盖。 我们将`json`中的文本数据改改: ```json {"id":1,"name":"zs","age":18} {"id":2,"name":"lisi","age":18} {"id":3,"name":"ww","age":19} {"id":4,"name":"zl","age":19} {"id":5,"name":"tq","age":19} ``` tn2>然后我们使用`MERGE`的类型,并且当冲突时删除`id=3`的数据。 执行命令如下: ```bash curl -u root: -H "label:load_local_file_json_20221129" -H "columns:id,name,age" -H "max_filter_ratio:0.1" -H "timeout:1000" -H "where:id>1" -H "format:json" -H "read_json_by_line:true" -H "merge_type:MERGE" -H "delete:id=3" -T "C:\Users\bob.he\OneDrive - Oerlikon Group\Desktop\project\Doris\json.txt" http://127.0.0.1:8040/api/test/load_local_file_test/_stream_load ``` 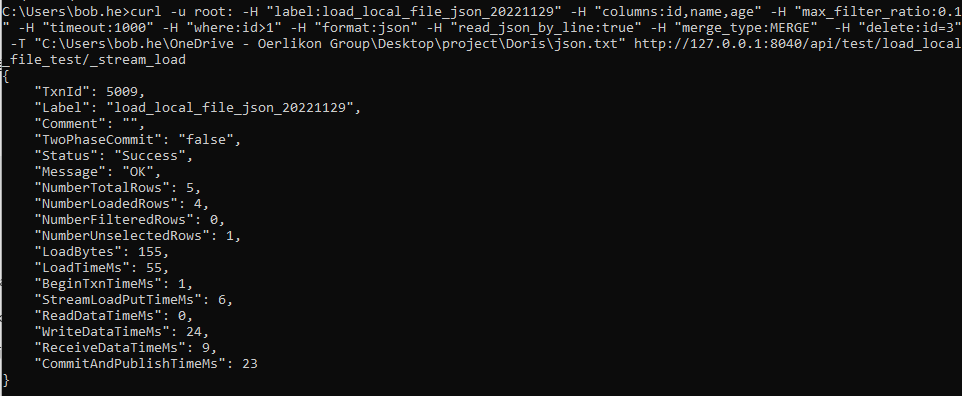 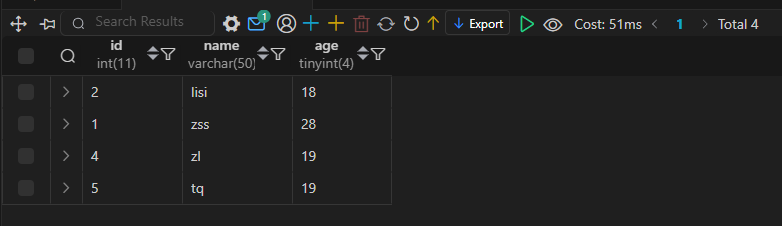 tn>导入建议 ● Stream Load 只能导入本地文件。 ● 建议一个导入请求的数据量控制在 1 - 2 GB 以内。如果有大量本地文件,可以分批并发提交。

