Whisper AI提词处理器 电脑版发表于:2024/8/13 21:38  <meta name='impact-site-verification' value='fa1aa124-2a1a-4ce4-a855-7d566efb6468'> >#Whisper AI提词处理器 [TOC] Whisper简介 ------------ tn2>Whisper 是一种通用语音识别模型。 它基于大量多样化音频数据集进行训练,同时也是一种可以执行多语言语音识别、语音翻译和语言识别的多任务模型。 安装与应用Whisper ------------ tn2>安装前提需要安装`ffmpeg`。 ```bash choco install ffmpeg ``` tn2>开始安装Whisper ```bash pip install -U openai-whisper ``` tn2>最好在安装之前开启代理进行安装。 ```bash set HTTP_PROXY=socks5://127.0.0.1:10808 set HTTPS_PROXY=socks5://127.0.0.1:10808 ``` tn2>安装完成后我们可以通过`whisper --help`命令查看帮助。 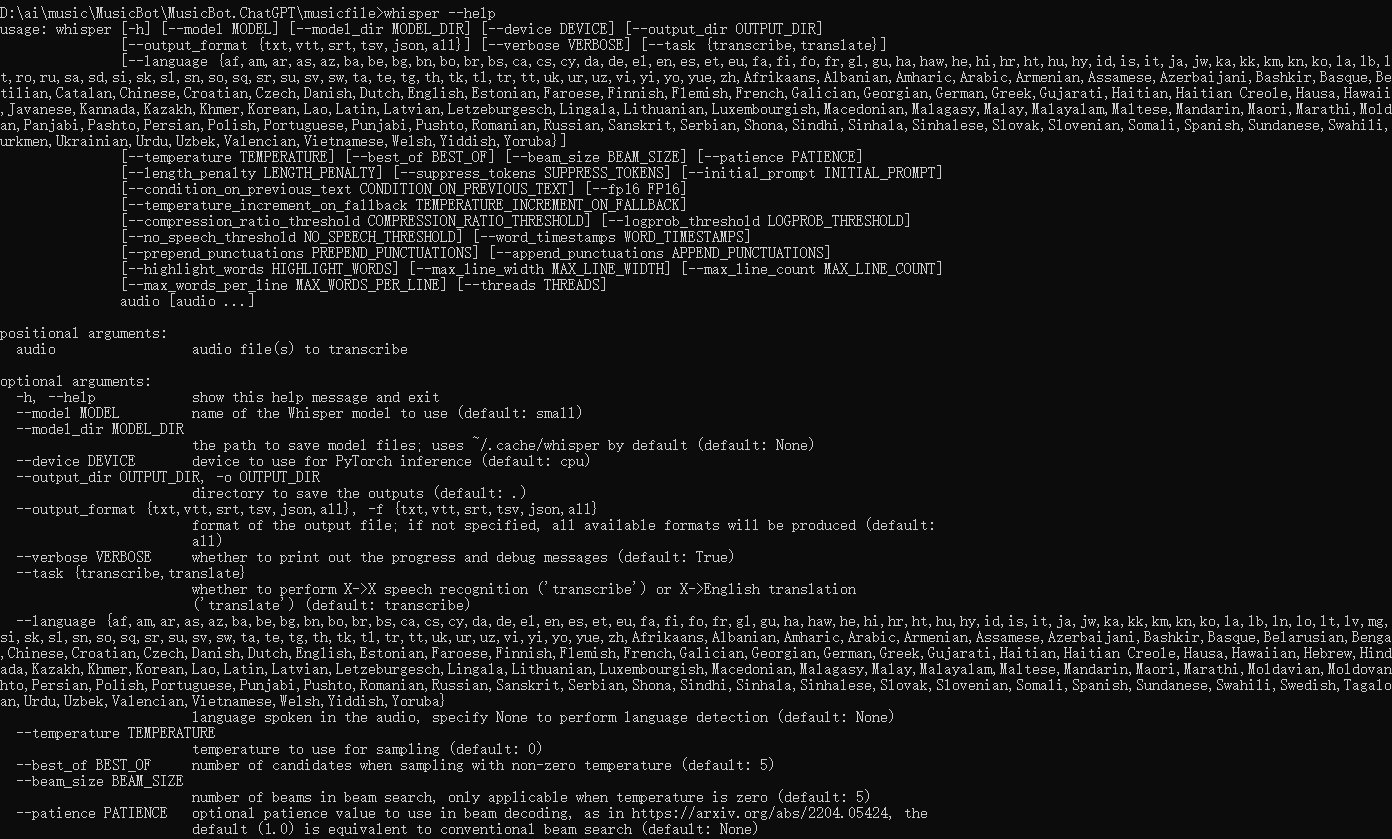 tn2>这里的参数有很多,我们只需要使用到几个。 我这里以`389479.mp3`为例子。 ```bash # 提取389479.mp3中的歌词,使用的是 small.en模型 whisper 389479.mp3 --model small.en ``` 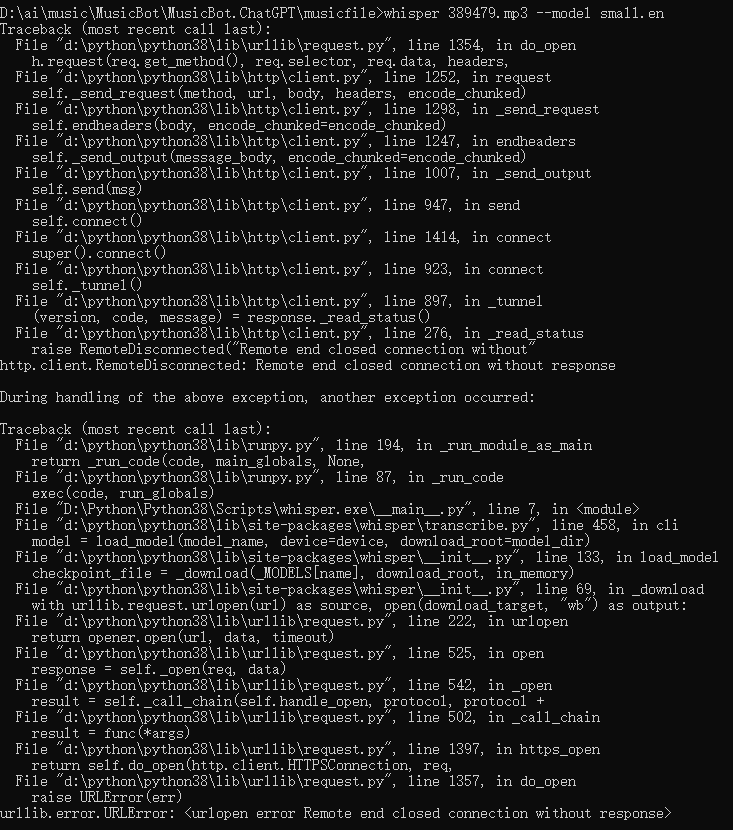 tn2>我们发现会报错。 我在官网找到[Colab 示例],点进去。 https://github.com/openai/whisper  tn2>然后我们执行一下这一个 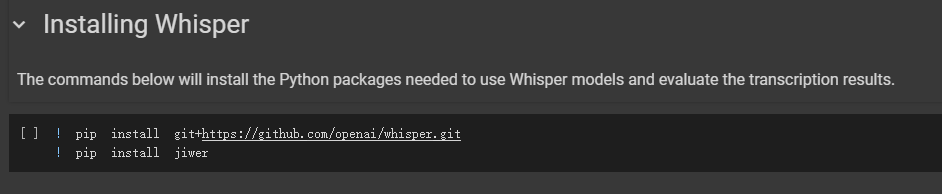 tn2>然后将我们的mp3文件进行上传。 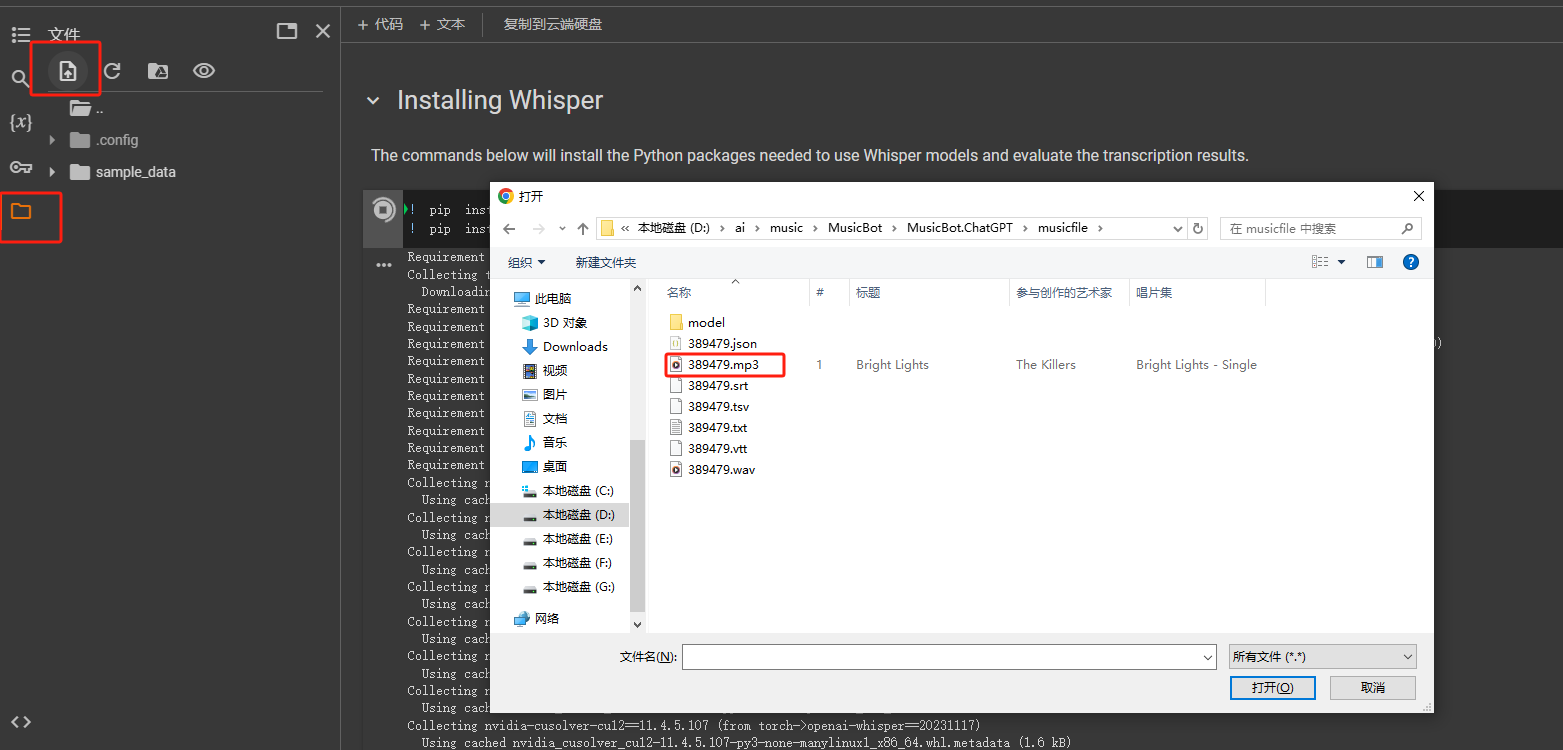 tn2>添加我们的代码进行执行。 ```bash !whisper 389479.mp3 --model small.en ``` 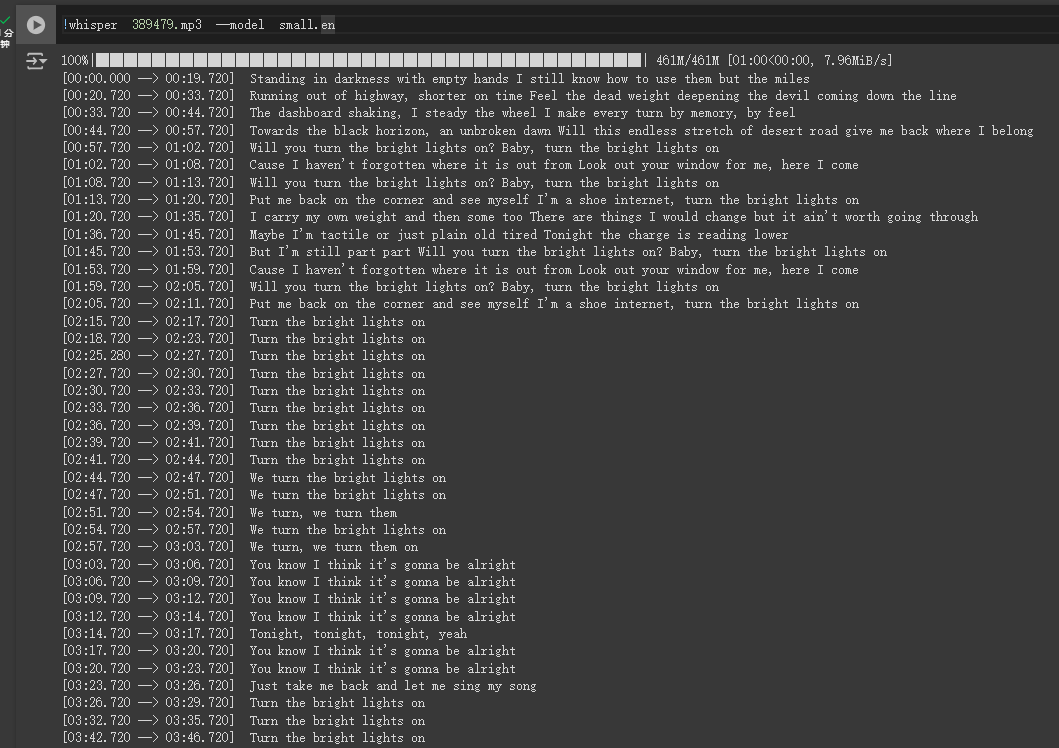  tn2>我们可以看到转换成功了,将每一句歌词都分析了出来,并且保存为各种模式的文本文件。 tn>但问题是它有下载模型,它的模型在哪儿呢? 它的模型在`~/.cache/whisper/`,我们将它复制到当前目录。 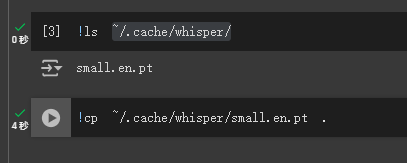 tn2>然后我们把模型进行下载。  tn2>保存到一个指定的目录中,然后在本地通过`--model_dir`参数指定模型路径。 再次执行,同样可以在本地进行题词了。 ```bash whisper 389479.mp3 --model_dir D:\ai\music\MusicBot\MusicBot.ChatGPT\musicfile\model --model small.en ``` 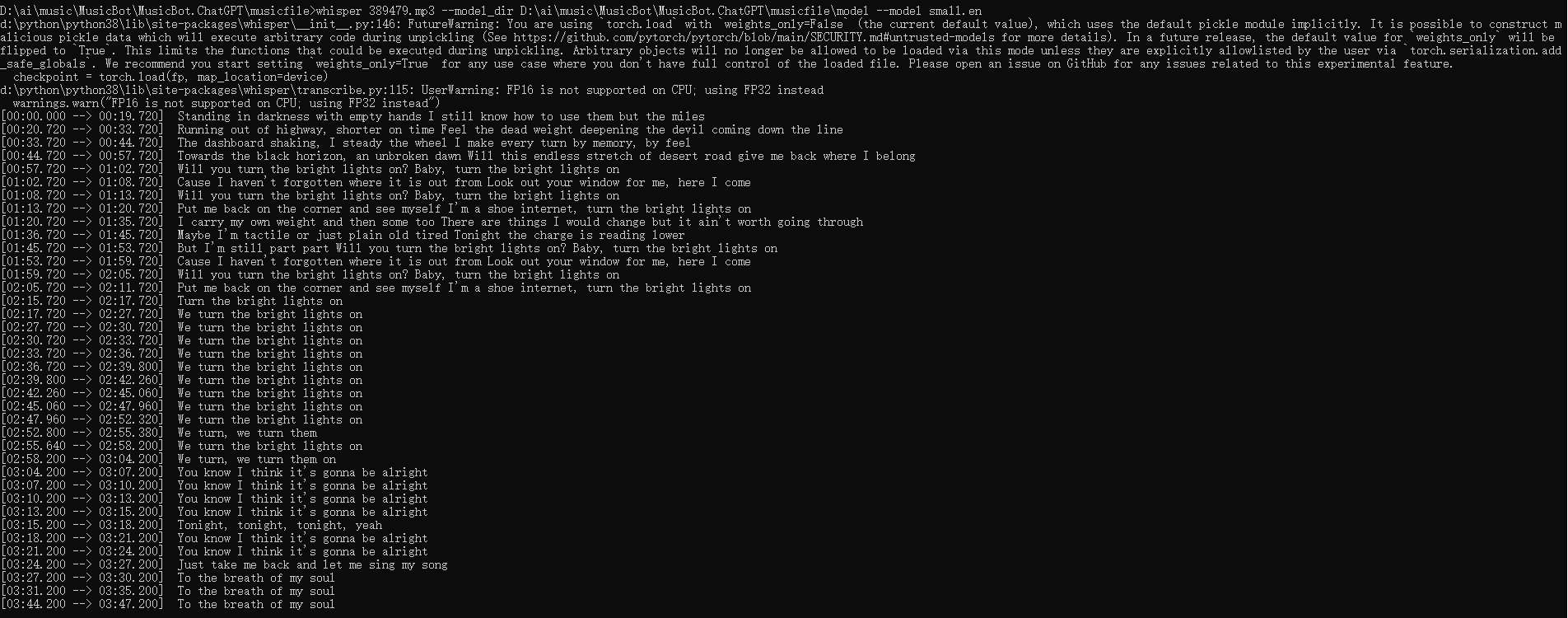 Whisper的模型列表 ------------ 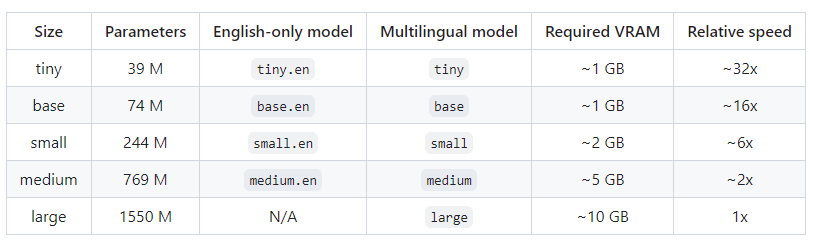 tn2>请根据自己的电脑配置进行选择,然后在`https://huggingface.co/`进行选择

