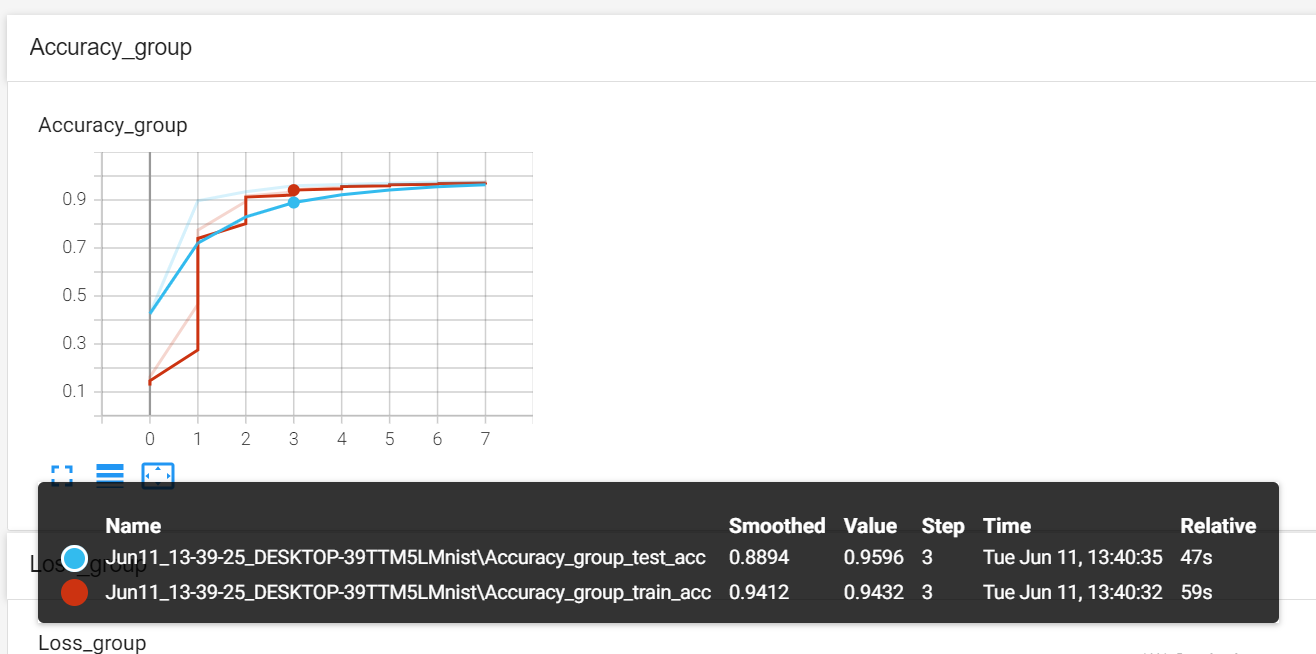
Pytorch TensorBoard运用(易化学习笔记六) 电脑版发表于:2024/6/11 13:42  >#Pytorch TensorBoard运用(易化学习笔记六) [TOC] TensorBoard简介 ------------ tn2>TensorBoard是TensorFlow的可视化工具包,旨在帮助研究人员和工程师理解、调试和优化他们的机器学习模型。 它提供了一系列强大的可视化功能,使用户能够追踪和展示训练过程中各种指标的变化,如损失函数和准确率。 此外,TensorBoard还允许用户查看模型的结构、权重和偏差的直方图,以及嵌入的投影。 TensorBoard简单实践 ------------ tn2>安装TensorBoard。 ```python %pip install tb-nightly ```  tn2>写一个简单的示范。 ```python from torch.utils.tensorboard import SummaryWriter # 创建日志的写入对象 # 无参时,会自动在当前目录下创建日志的文件夹runs writer = SummaryWriter() x = range(100) for i in x: # 写入数据到日志的标量图'y=2x' 中 writer.add_scalar('y=2x', i * 2, i) # 写入完成后,要关闭对象,避免资源占用 writer.close() ``` 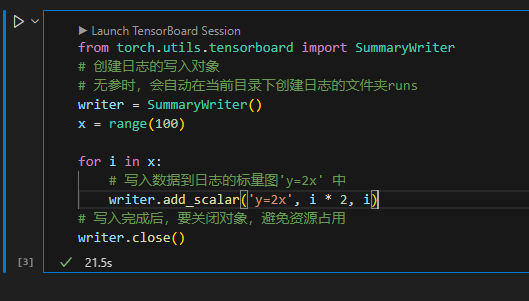 tn2>接下来打开命令窗口,执行`tensorboard --logdir=runs`命令。  tn2>打开`http://localhost:6006/#timeseries`网页,查看我们的记录的标量图。 可以看到已经很好的记录了`y=2x`。 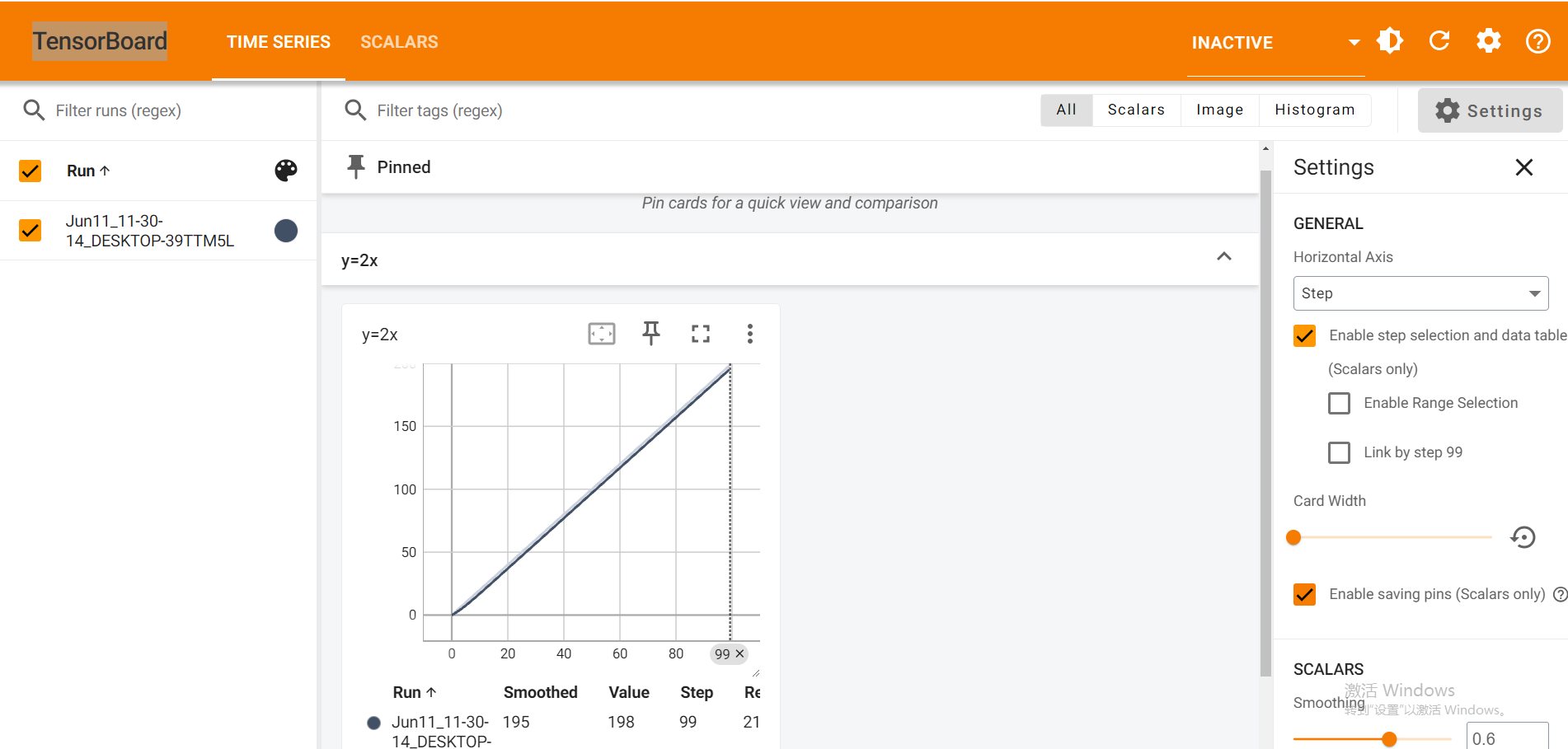 tn2>我们再做一点小小的改动,并再次执行,然后在TensorBoard刷新并查看。 ```python writer.add_scalar('y=2x', i * 10, i) ``` 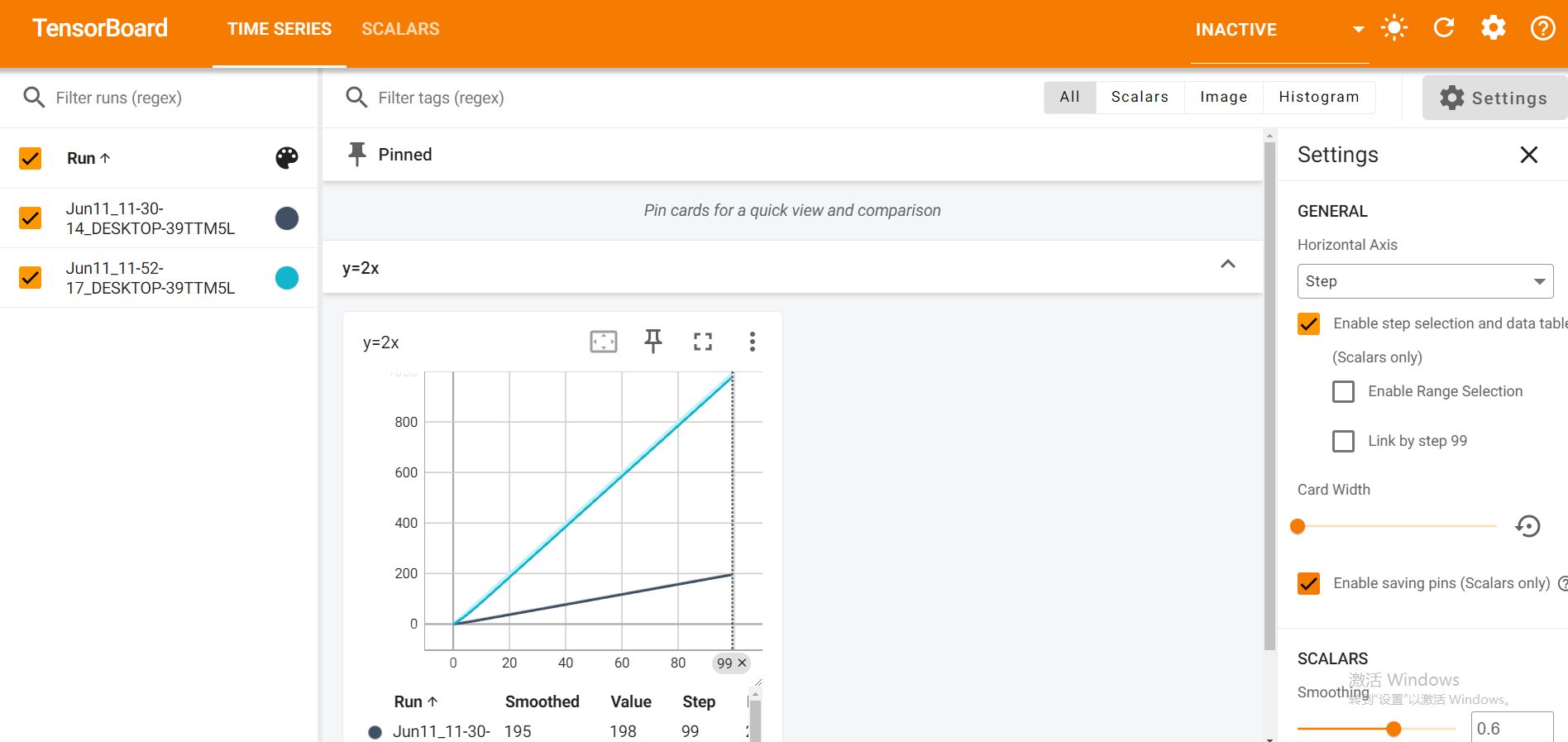 tn2>我们发现它会保留历史的数据,tensorboard读取的runs目录下的日志文件。  TenanBoard 跟踪模型和LOSS曲线 ------------ tn2>创建`-1`到`1`的随机点,然后进行训练并通过TenanBoard进行记录损失。 ```python # 1.导入数据集 import torch import matplotlib.pyplot as plt from torch import nn from torch.utils.tensorboard import SummaryWriter writer = SummaryWriter(comment='Linear') # 制造满足某规律(y=3*x+10)的样本点集,通过训练,找出权重w,使得该直线拟合样本点 # 创建在-1 到1 间均分100个点的一维数组 x = torch.linspace(-1, 1, 100) # 在1号位置,增加维数为1的维度,变成100行1列 的2维矩阵 x = x.unsqueeze(1) #print(x.shape) #//torch.Size([100, 1] # 加上torch.rand()函数制造噪音 y = 3 * x + 10 + torch.rand(x.size()) # 2.构建模型 # 设置内置的线性回归, 输入:1w维 输出:1维 model = nn.Linear(1,1) # 使用均值损失函数 criterion = nn.MSELoss() # 使用SGD优化器 optimizer = torch.optim.SGD(model.parameters(), lr=1e-2) # 3.训练评估 num_epochs = 1000 for epoch in range(num_epochs): # 向前传播 out = model(x) loss = criterion(out, y) # 向后传播 # 注意每次迭代都需要清零 optimizer.zero_grad() loss.backward() optimizer.step() # 保存loss与epoch 变化关系 writer.add_scalar('Train', loss, epoch) # 每200个batch打印一次cost值,显示一下图像拟合效果 if epoch % 100 == 0: print('Epoch[{}/{}], loss:{:.6f}'.format(epoch + 1, num_epochs, loss.item())) # 将model记录到graph中(graph是神经网络的数据流图) writer.add_graph(model, x) # 写入完成后,要关闭对象,避免资源占用 writer.close() model.eval() predict = model(x) predict = predict.data.numpy() plt.plot(x.numpy(), y.numpy(), 'ro', label='样本点集') plt.plot(x.numpy(), predict, label='拟合后的直线') plt.show() ``` 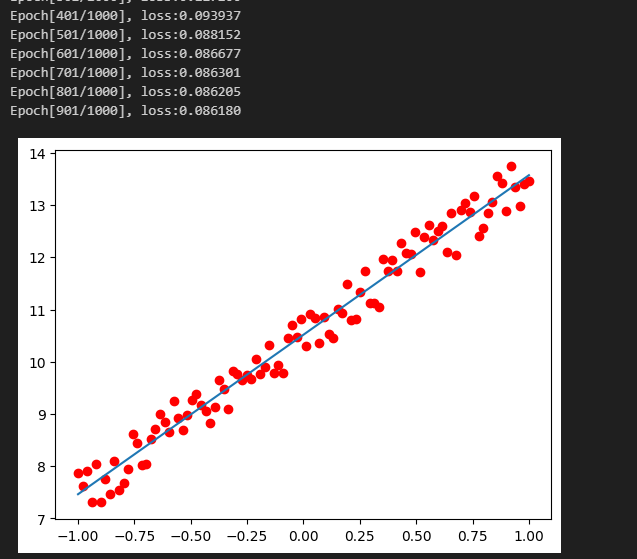  分析曲线图 ------------ ```python import torch import torchvision import torch.nn as nn import os ## 导入自定义的日志库 from my_log import Outer,run_time # 指定日志的文件名(会自动加后缀为.log) out = Outer(os.path.basename("TensorBordeasy.ipynb")); ## 超参数设置 MAX_EPOCH = 8 # 遍历数据集次数 BATCH_SIZE = 64 # 批处理尺寸(每批用64个图片) LR = 0.001 # 学习率 ## 数据载入 trans = torchvision.transforms.ToTensor() # 定义数据预处理方式 train_data = torchvision.datasets.MNIST( # 获取手写数字的训练集(其中都是28*28的图片) root="./data", # 设置数据集的根目录 train=True, # 是训练集 transform=trans, # 设置转换函数 download=True # 下载数据集(只是第一次下载) ) test_data = torchvision.datasets.MNIST( # 获取手写数字的测试集 root="./data/", train=False, # 是测试集 transform=trans, download=True # 下载数据集(只是第一次下载) ) train_loader = torch.utils.data.DataLoader( # 载入训练集 dataset=train_data, # 指定数据集载入 batch_size=BATCH_SIZE, # 每批数目(每个包中的图片数) shuffle=True) # 乱序打包 test_loader = torch.utils.data.DataLoader( # 载入测试集 dataset=test_data, batch_size=BATCH_SIZE, shuffle=True) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 没有gpu则使用cpu # 建立模型 class LeNet(nn.Module): # 定义网络结构 def __init__(self): super(LeNet, self).__init__() self.conv1 = nn.Sequential( # 卷积层: 由下面3层添加到顺序容器Sequential中而成 nn.Conv2d(1, 6, 5, 1, 2), # /*2维卷积层: input_size=(1*28*28) -> 特征过滤(降维) # 当输入nn.Conv2d() 应该有对应参数提示信息或参考API函数, Ctrl+B 看声明 , Ctrl+Alt+B 查看实现代码 # 参数未输入的将采用默认值 # 如 class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True) # 输入通道: 1张灰度图 input_size=(1*28*28),图片需是28*28的(如是32*32 需公式来O=(I-F+2P)/S+1调整 变为Conv2d(1, 6, 5)) # 输出通道: 6张特征图 (从不同角度看,得到不同特征图,如从轮廓,明暗效果,纹理等,可定义许多个) # 卷积核大小: 5x5 高宽相等可只写一个 # 滑动步长: 1步 # 填充: 2 -> 图边用2圈0填充(卷积后尺寸会变小,图边可用零填充,保证尺寸相同) # 注:为维持输出图片尺寸不变 由公式 O=(I-F+2P)/S+1=(28-5+2*2)/1+1 = 28 # */ nn.ReLU(), # 激活层: input_size=(6*28*28) -> 引入非线性(可挑选信息) nn.MaxPool2d(kernel_size=2, stride=2), # /*池化层(最值):output_size=(6*14*14) -> 舍去非显著特征,减少参数,缓解过拟合 # O=(I-F+2P)/S+1 = (28-2+2*0)/2 + 1 = 14 # */ ) self.conv2 = nn.Sequential( nn.Conv2d(6, 16, 5), # input_size=(6*14*14) O=(I-F+2P)/S+1=(14-5+2*0)/1+1 = 10 nn.ReLU(), # input_size=(16*10*10) nn.MaxPool2d(2, 2) # output_size=(16*5*5) O=(I-F+2P)/S+1=(10-2+2*0)/2+1 = 5 ) self.fc1 = nn.Sequential( # 全连接层 (in:16*5*5 out:120) nn.Linear(16 * 5 * 5, 120), nn.ReLU() ) self.fc2 = nn.Sequential( nn.Linear(120, 84), nn.ReLU() ) self.fc3 = nn.Linear(84, 10) def forward(self, x): # 前向传播函数: 一旦构建前向传播网络成功,反向传播函数也会自动生成(autograd) x = self.conv1(x) x = self.conv2(x) # print(x.shape) torch.Size([64, 16, 5, 5]) 每批64张图片 输出16张 5*5的特征图 x = x.view(x.shape[0], -1) # 扁平化:行64张 列-1自动推导,把16张 5*5的特征图压平为一维的点 -> 方便对接全连接层 x = self.fc1(x) x = self.fc2(x) x = self.fc3(x) return x net = LeNet().to(device) # 新建模型 criterion = nn.CrossEntropyLoss() # 使用交叉熵损失函数(通常用于多分类问题上) optimizer = torch.optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择SGD的优化器 out.info("model creat ok,start training") ## 训练模型 from torch.utils.tensorboard import SummaryWriter writer = SummaryWriter(comment='Mnist') for epoch in range(MAX_EPOCH): sum_loss = 0.0 # 记录一个epoch的loss之和 correct = 0.0 total = 0.0 # 数据读取 for i, data in enumerate(train_loader): # enumerate 遍历列表对象,加上序号i inputs, labels = data # inputs:手写数字图片 labels:图片对应的数字标签 inputs, labels = inputs.to(device), labels.to(device) optimizer.zero_grad() # 梯度清零: 每次迭代都需梯度清零,因pytorch默认会累积梯度 # 向前传播 preds = net(inputs) # 模型对输入进行预测 loss = criterion(preds, labels) # 计算损失 # 向后传播 loss.backward() # 反向传播,计算梯度 optimizer.step() # 按学习率减去少量梯度来调整权重 # 统计预测信息 _, predicted = torch.max(preds.data, 1) total += labels.size(0) correct += (predicted == labels).sum() sum_loss += loss.item() # 每训练100个batch打印一次平均loss if i % 100 == 99: loss_avg = sum_loss / 100 sum_loss = 0.0 # 输出: 训练的轮数, 迭代的样本数 平均损失值, 正确率 out.info("Training: Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%} ".format( epoch + 1, MAX_EPOCH, i + 1, len(train_loader), loss_avg, correct / total)) writer.add_scalars('Loss_group', {'train_loss': loss_avg}, epoch) # 记录训练loss到标量图scalar中 writer.add_scalars('Accuracy_group', {'train_acc': correct / total}, epoch) # 记录Accuracy到标量图scalar中 # 验证模型 with torch.no_grad():# 每跑完一次epoch测试一下准确率 correct = 0 total = 0 for data in test_loader: images, labels = data images, labels = images.to(device), labels.to(device) outputs = net(images) # 取得分最高的那个类 _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum() out.info('验证第%d个epoch的识别的准确率为:%d%%' % (epoch + 1, (100 * correct / total))) writer.add_scalars('Accuracy_group', {'test_acc': correct / total}, epoch) # 记录Accuracy到标量图scalar中 out.info('Finished Training') writer.close() out.info(run_time()) ``` 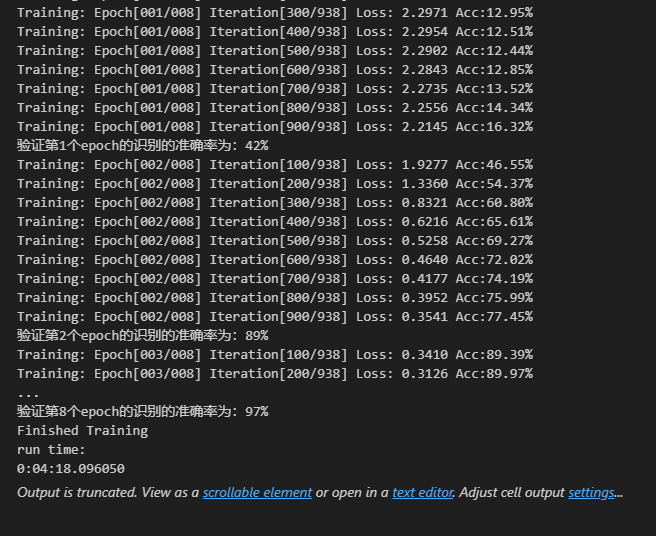 tn2>损失下降的图如下 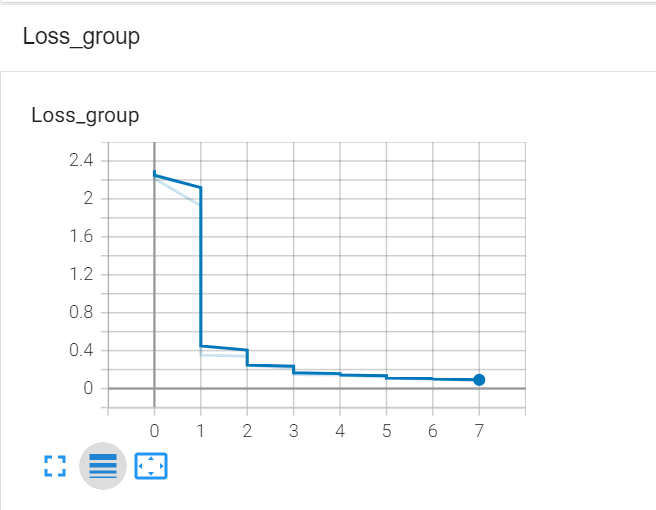 tn2>Accuracy_group记录了训练集和测试集的正确率。