Pytorch cifar10识别普适物体(易化学习笔记四) 电脑版发表于:2024/6/10 13:47  >#Pytorch cifar10识别普适物体(易化学习笔记四) [TOC] CIFAR-10简介 ------------ tn2>CIFAR-10(Canadian Institute For Advanced Research)是一个广泛用于机器学习和计算机视觉研究的标准数据集,主要用于图像识别任务。它由Alex Krizhevsky、Vinod Nair和Geoffrey Hinton在2009年创建,包含10个不同类别的普适物体。每个类别有6000张`32x32`彩色图像,总共有60000张图像,其中50000张用于训练,10000张用于测试。这些类别包括飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。 代码实践 ------------ ### 数据处理 ```python import torch import torchvision import torchvision.transforms as transforms # 转换的集合 transform = transforms.Compose( [transforms.ToTensor(), # 归一化,转为[0,1.0] shape[C,H,W]的张量 # 正则化:前(0.5, 0.5, 0.5)是RGB通道均值,后(0.5, 0.5,0.5)是RGB通道标准差 -> 减少泛化误差(防过拟合) transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # 每批取的图片数(这里取4张) batch_size = 4 # 获取训练集 trainset = torchvision.datasets.CIFAR10( root='./data', # 设置数据集的根目录 train=True, # 是训练集 download=True, # 如本地无,则从网络下载 transform=transform) # 设置转换函数 # 载入训练集 trainloader = torch.utils.data.DataLoader( trainset, # 指定载入训练集 batch_size=batch_size, # 每批取的数目 shuffle=True, # 乱序打包 num_workers=2) # 设置多线程数(加num_workers 有的设备可能报错 ) # 获取测试集 testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) # 载入测试集 testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') ```  tn2>从训练集中查看一张图片。 ```python import matplotlib.pyplot as plt import numpy as np # 显示图像 def imshow(img): img = img / 2 + 0.5 npimg = img.numpy() # 把(channel,height,weight) 转为Matplotlib能识别的 (height,weight,channel) show_img = np.transpose(npimg, (1, 2, 0)) # (36, 138, 3) 合并后的图片高36宽138,3个通道(rgb) print(show_img.shape) plt.imshow(show_img) plt.show() # 随机获取一批图像样本 dataiter = iter(trainloader) images, labels = next(dataiter) # torch.Size([4, 3, 32, 32]) 4张 3通道(RGB) 的32*32的图片 print(images.shape) # tensor([6, 6, 3, 7]) 4张图片分别对应的类别字典的索引(位置) print(labels) # 拼成一幅图像显示: 把4维 (batch_size,channel,height,weight) 变为3维 (channel,height,weight) imshow(torchvision.utils.make_grid(images)) print(' '.join('%5s' % classes[labels[j]] for j in range(batch_size))) # 根据索引值查找类别名 # 如 frog frog cat horse (图像对应的类别名) ```  ### 构建模型 ```python import torch.nn as nn import torch.nn.functional as F import torch.optim as optim # 定义网络模型 class Net(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(3, 6, 5) # 卷积1: 输入3个RGB通道32*32的图片,输出6张特征图, 用5x5的卷积核 self.pool = nn.MaxPool2d(2, 2) # 最大值池化: 2*2的卷积核, 步长2 self.conv2 = nn.Conv2d(6, 16, 5) # 卷积2: 输入6,输出16,5*5的卷积核 self.fc1 = nn.Linear(16 * 5 * 5, 120) # 线性回归 (in:16*5*5 out:120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) # 前向传播 def forward(self, x): x = self.pool(F.relu(self.conv1(x))) # 构建卷积层1(Conv2d->relu->MaxPool2d) x = self.pool(F.relu(self.conv2(x))) # 构建卷积层2(Conv2d->relu->MaxPool2d) x = torch.flatten(x, 1) # 扁平化所有维度,除了batch外 -> 方便对接全连接层 # 替代老式做法 x = x.view(-1, 16 * 5 * 5) 扁平化:行-1自动推导 列未16*5*5, 把16张 5*5的特征图压平为一维的点 x = F.relu(self.fc1(x)) # 构建全连接层1( Linear->relu) x = F.relu(self.fc2(x)) x = self.fc3(x) return x net = Net() # 新建模型 criterion = nn.CrossEntropyLoss() # 损失函数用交叉熵 optimizer = optim.Adam(net.parameters(), lr=0.001) ``` ### 训练评估 ```python # 训练8轮(注 for epoch in range(8): running_loss = 0.0 for i, data in enumerate(trainloader, 0): inputs, labels = data # 获取 [inputs:输入图片 labels:图片对应的数字标签] optimizer.zero_grad() # 梯度清零: 每次迭代都需梯度清零,因pytorch默认会累积梯度 # 前向传播 outputs = net(inputs) # 用模型对输入进行预测 loss = criterion(outputs, labels) # 计算损失(误差) # 反向传播 loss.backward() # 反向传播,计算梯度 optimizer.step() # 优化一步(梯度下降) running_loss += loss.item() if i % 2000 == 1999: # 每2000批,打印一次统计 # 打印如 [2, 10000] loss: 1.274 第2轮训练 训练样本10000 损失为1.274 print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000)) running_loss = 0.0 print('Finished Training') ``` 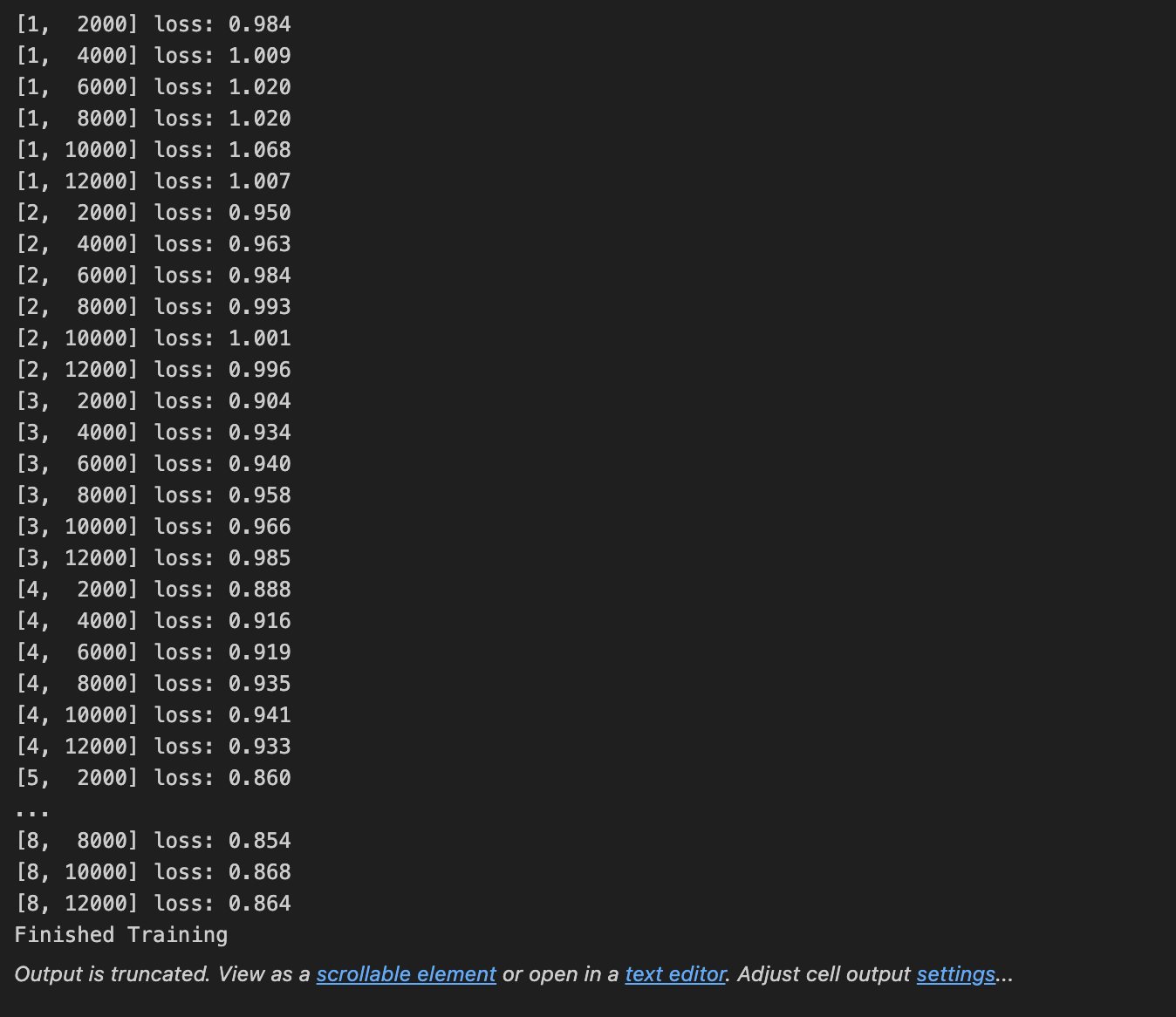 tn2>评估1:用1000个测试图片预测,正确率是多少 ```python correct = 0 total = 0 # 因为我们没有训练,所以我们不需要计算输出的梯度 with torch.no_grad(): for data in testloader: images, labels = data # 用模型对输入进行预测 outputs = net(images) # 取概率最大做预测值(字典里的索引位置) _, predicted = torch.max(outputs.data, 1) # 预测总数 total += labels.size(0) # 预测正确的次数 correct += (predicted == labels).sum().item() # 输出1000个测试图片中,正确率(精度: 正确率= 正确的次数/总数)是多少 print('Accuracy of the network on the 10000 test images: %d %%' % ( 100 * correct / total)) # 如 Accuracy of the network on the 10000 test images: 54 % ```  tn2>评估:对10个类别预测,那一类的正确率更高 ```python class_correct = list(0. for i in range(10)) class_total = list(0. for i in range(10)) with torch.no_grad(): for data in testloader: images, labels = data outputs = net(images) _, predicted = torch.max(outputs, 1) c = (predicted == labels).squeeze() for i in range(4): label = labels[i] class_correct[label] += c[i].item() class_total[label] += 1 for i in range(10): print('Accuracy of %5s : %2d %%' % ( classes[i], 100 * class_correct[i] / class_total[i])) ``` 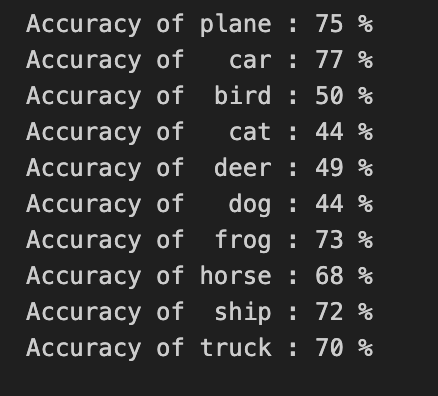 tn2>保存模型 ```python PATH = './cifar_net.pth' torch.save(net.state_dict(), PATH) # 保存模型的参数 ``` ### 从测试集中随机取一批图像,看预测效果 ```python # 从测试集中随机取一批图像 images, labels = next(iter(testloader)) # 查看图像 imshow(torchvision.utils.make_grid(images)) # 查看标签 print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4))) # 新建模型,用于测试评估(必须与训练时的模型一致) net = Net() # 载入已训练好的模型参数 net.load_state_dict(torch.load(PATH)) # 预测:用模型识别图像 outputs = net(images) # 取概率最大做预测值(字典里的索引位置) _, predicted = torch.max(outputs, 1) # 打印预测的图像的类别(如cat horse dog bird) print('Predicted: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4))) ``` 

