Pytorch 识别手写数字(易化学习笔记三) 电脑版发表于:2024/6/9 20:11  >#Pytorch 识别手写数字(易化学习笔记三) [TOC] 识别手写数字 ------------ ### LeNet-5 tn2>手写数字识别的非常高效的卷积神经网络。 高效原因: 1.用卷积核(局部连接,共享权重,平移不变性) -> 提取关键特征,参数大幅减少 2.不断降维后,仍能保留关键特征(识别成功) `64*28*28 -> 6*28*28 -> 6*14*14 -> 16*10*10 -> 16*5*5 -> 120 -> 84 -> 10` 用卷积 减少图片张数(64 -> 6) 用池化减少图片大小(28->14 -> 10 -> 5 -> 1) 用全连接层 把三维的矩阵降为 一维 (16*5*5 ->120) 两层全连接层,是借鉴 softmax 取10个中做大概率的。  ### 训练模型 tn2>创建一个`q1.py`的文件。 ```python import torch import torchvision import torch.nn as nn # 超参数设置 # 训练轮数 EPOCH = 8 # 批处理尺寸(每批用64个图片) BATCH_SIZE = 64 # 学习率 LR = 0.001 ## 数据载入 # 归一化,转为[0,1.0] shape[C,H,W]的张量 # trans = torchvision.transforms.ToTensor() #(优化方式) 3.正则化 -> 加弹性余量 # 在输入数据的预处理里,加入正则化Normalize trans = torchvision.transforms.Compose( # 转换的集合 [ torchvision.transforms.ToTensor(), # 归一化,转为[0,1.0] shape[C,H,W]的张量 torchvision.transforms.Normalize([0.5], [0.5]) # 正则化(均值=0.5,标准差=0.5) ] ) # 获取手写数字的训练集(pytorch已整理好的,其中都是28*28的图片) train_data = torchvision.datasets.MNIST( root="./data", # 设置数据集的所在目录 train=True, # 是训练集 transform=trans, # 设置转换函数 download=True # True:无则下载数据集 ) # 获取手写数字的测试集 test_data = torchvision.datasets.MNIST( root="./data/", train=False, # 是测试集 transform=trans, download=True ) # 载入训练集 train_loader = torch.utils.data.DataLoader( dataset=train_data, # 指定数据集载入 batch_size=BATCH_SIZE, # 每批数目(每次从数据集中取出 送入模型的训练的样本数) shuffle=True) # 乱序(取样本时) # 载入测试集 test_loader = torch.utils.data.DataLoader( dataset=test_data, batch_size=BATCH_SIZE, shuffle=True) ## 构建模型 # 定义网络结构 class LeNet(nn.Module): def __init__(self): super(LeNet, self).__init__() # 卷积层: 由下面3层添加到顺序容器Sequential中而成 self.conv1 = nn.Sequential( nn.Conv2d(1, 6, 5, 1, 2), # /*2维卷积层: input_size=(1*28*28) -> 特征过滤(降维) # 右键可查看API,参数未输入的将采用默认值 # 如 class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True) # 输入通道: 1张灰度图 input_size=(1*28*28),图片需是28*28的 # 输出通道: 6张特征图 (从不同角度看,得到不同特征图,如从轮廓,明暗效果,纹理等,可定义许多个) # 一个卷积核 ,过滤出一张特征图,输出6张特征图,就对应6个卷积核 # 卷积核大小: 5x5 高宽相等可只写一个 # 滑动步长: 1步 # 填充: 2 -> 图边用2圈0填充(卷积后尺寸会变小,图边可用零填充,保证尺寸相同) # 注:为维持输出图片尺寸不变 由公式 O=(I-F+2P)/S+1=(28-5+2*2)/1+1 = 28 # 如是32*32图片 需公式来O=(I-F+2P)/S+1调整 变为Conv2d(1, 6, 5) # */ nn.ReLU(), # 激活层: input_size=(6*28*28) -> 引入非线性(可挑选信息) nn.MaxPool2d(kernel_size=2, stride=2),#/*池化层(最值): # output_size=(6*14*14) -> 舍去非显著特征,减少参数,缓解过拟合 # O=(I-F+2P)/S+1 = (28-2+2*0)/2 + 1 = 14 #*/ ) self.conv2 = nn.Sequential( nn.Conv2d(6, 16, 5), # input_size=(6*14*14) O=(I-F+2P)/S+1=(14-5+2*0)/1+1 = 10 nn.ReLU(), # input_size=(16*10*10) nn.MaxPool2d(2, 2) # output_size=(16*5*5) O=(I-F+2P)/S+1=(10-2+2*0)/2+1 = 5 ) # 全连接层 (in:16*5*5 out:120) self.fc1 = nn.Sequential( nn.Linear(16 * 5 * 5, 120), # (优化方案)2.加入dropout 随机断开 -> 增加随机性(防过拟合) nn.Dropout(0.5), # 随机50%的断开 nn.ReLU() ) self.fc2 = nn.Sequential( nn.Linear(120, 84), nn.ReLU() ) self.fc3 = nn.Linear(84, 10) # 前向传播函数: 一旦构建前向传播网络成功,反向传播函数也会自动生成(autograd) def forward(self, x): x = self.conv1(x) x = self.conv2(x) # print(x.shape) torch.Size([64, 16, 5, 5]) 每批64张图片 输出16张 5*5的特征图 # 扁平化:行64张 列-1自动推导,把16张 5*5的特征图压平为一维的点 -> 方便对接全连接层 x = x.view(x.shape[0], -1) x = self.fc1(x) x = self.fc2(x) x = self.fc3(x) return x # 没有gpu则使用cpu device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 新建模型到设备上(gpu/cpu) net = LeNet().to(device) # 使用交叉熵损失函数(通常用于多分类问题上) criterion = nn.CrossEntropyLoss() # 采用SGD的优化器 # 在优化器中加L2正则化(weight_decay=0.01 指权重衰减 惩罚%1) optimizer = torch.optim.Adam(net.parameters(), lr=LR) ## 训练评估 for epoch in range(EPOCH): sum_loss = 0.0 # enumerate 遍历列表对象,加上序号i for i, data in enumerate(train_loader): # 准备 # inputs:手写数字图片 labels:图片对应的数字标签 inputs, labels = data # 把数据传入设备中(如GPU) inputs, labels = inputs.to(device), labels.to(device) # 梯度清零: 每次迭代都需梯度清零,因pytorch默认会累积梯度 optimizer.zero_grad() # 向前传播 # 模型对输入进行预测 preds = net(inputs) # 计算损失 loss = criterion(preds, labels) # 向后传播 # 反向传播,计算梯度 loss.backward() # 按学习率减去少量梯度来调整权重 optimizer.step() # 每训练100个batch打印一次平均loss sum_loss += loss.item() if i % 100 == 99: print('[%d, %d] loss: %.03f'%(epoch + 1, i + 1, sum_loss / 100)) sum_loss = 0.0 # 每跑完一次epoch测试一下准确率 with torch.no_grad(): correct = 0 total = 0 for data in test_loader: images, labels = data images, labels = images.to(device), labels.to(device) outputs = net(images) # 取得分最高的那个类 _, predicted = torch.max(outputs.data, 1) # 标签总数: 累加每批取的标签数 total += labels.size(0) # 预测正确的样本数 correct += (predicted == labels).sum() # 统计正确率 print('第%d个epoch的识别准确率为:%d%%' % (epoch + 1, (100 * correct / total))) torch.save(net.state_dict(), "mnist_2d.pth") # 保存模型参数(推荐) # 优点: 速度快,占空间少, # 缺点: 重加载时需自定义model,且参数需与保存的模型的一致, # 可以只是部分网络,相对灵活,便于对网络进行修改 # torch.save(net, 'net_model.pth') # 可直接保存模型(不建议),这里略过 ``` 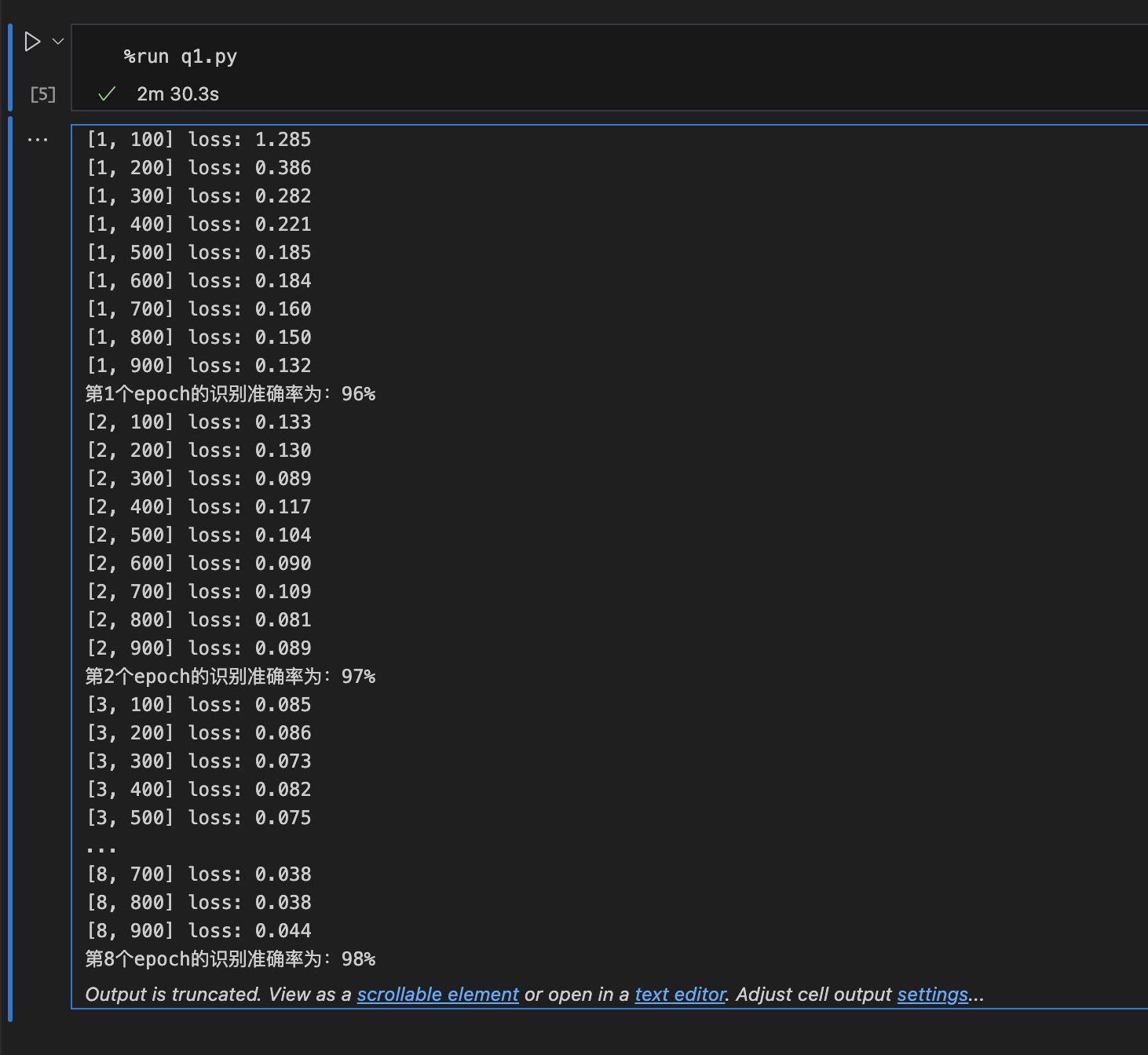 ### 数据预处理 tn2>从网上找一张图片,然后编写`q2.py`文件。  ```python ## 数据预处理 import cv2 # 导入opencv库 import matplotlib.pyplot as plt #pic ='8.bmp' # 待识别的图片名 pic ='4.jpeg' img = cv2.imread(pic) # 读取图片 # 数据预处理(转换为与训练集相同的格式) img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 彩色图片转为灰度图片 img = 255 - img # 黑白反转(官方mnist集合里黑白是反的) img = cv2.resize(img,(28,28),interpolation = cv2.INTER_AREA) # 转换为与训练集图片相同的尺寸 img = img.reshape(1,28,28) # 转换为与训练集相同格式 1个 28*28像素的 测试图像 img =img/255.0 # 除以255为了归一化,加.0 转为浮点数 ->避免数据溢出 # 查看图片数据 print(img.shape) for i in range(28): for j in range(28): print(format(img[0][i][j],'.1f'),end="") # 0:0号图 i:图的行号 j:图的列号 end=""不换行 # .1f: 限制float小数点后的显示位数为1位 print('E') # 显示图片 plt.imshow(img[0], cmap=plt.get_cmap('gray')) # cmap: 颜色图谱 gray:黑白色 plt.show() ```  ### 预测数据 tn2>接着我们刚刚的代码添加如下代码进行预测数据。 ```python ## 载入模型参数 # 定义网络结构 class LeNet(nn.Module): def __init__(self): super(LeNet, self).__init__() self.conv1 = nn.Sequential( nn.Conv2d(1, 6, 5, 1, 2), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2), ) self.conv2 = nn.Sequential( nn.Conv2d(6, 16, 5), nn.ReLU(), nn.MaxPool2d(2, 2) ) self.fc1 = nn.Sequential( nn.Linear(16 * 5 * 5, 120), nn.Dropout(0.5), nn.ReLU() ) self.fc2 = nn.Sequential( nn.Linear(120, 84), nn.ReLU() ) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.conv1(x) x = self.conv2(x) x = x.view(x.shape[0], -1) x = self.fc1(x) x = self.fc2(x) x = self.fc3(x) return x # 没有gpu则使用cpu device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 新建模型到设备上(gpu/cpu) model = LeNet().to(device) # 加载已训练好的模型参数 model.load_state_dict(torch.load('mnist_2d.pth')) # 可用载入模型torch.load('模型名'),一般不推荐使用,略过 ## 预测评估 # 评估模式 model.eval() # 转为torch 的张量格式 img = torch.tensor(img) # 升维为 torch.Size([1, 1, 28, 28]) -> 满足model对输入格式要求 img = img.unsqueeze(0) # 需与模型的元素类型匹配 images =img.to(torch.float32) images = images.to(device) print("image shap=",images.shape) print("image dtype=",images.dtype) outputs = model(images) # 用模型预测, # 注:输入数据要求是4维,如 torch.Size([64, 1, 28, 28]) # 输出10个数字的概率 print(outputs) # 取概率最高的 _, predicted = torch.max(outputs.data, 1) # 预测值 print(predicted) ``` 

