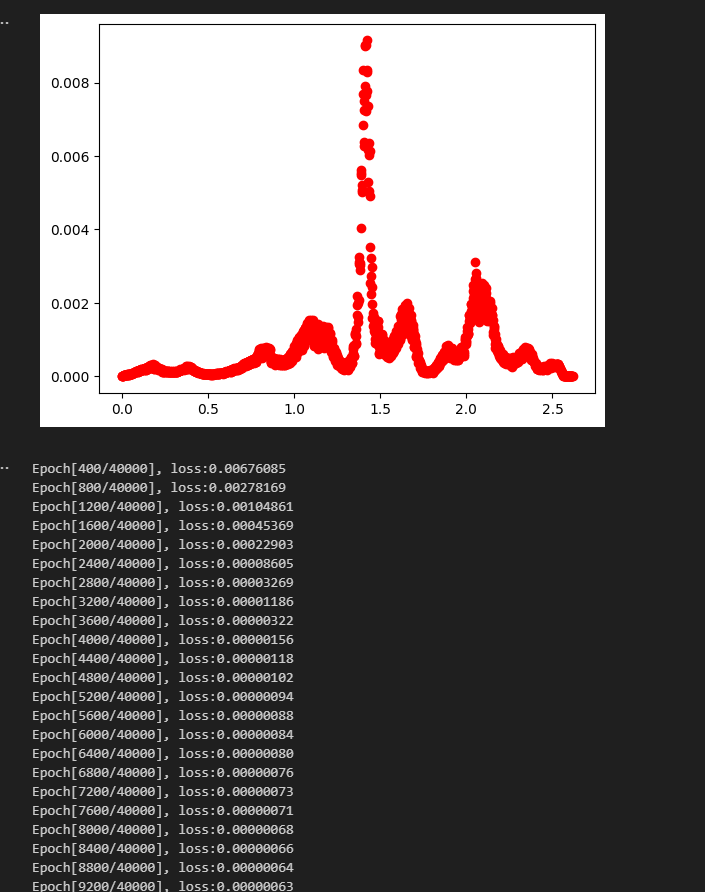
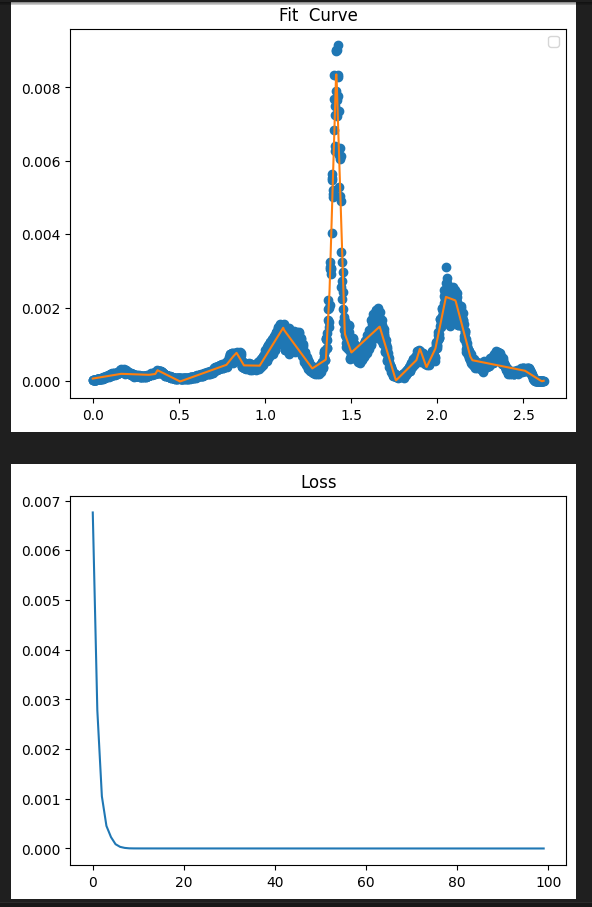
Pytorch 曲线拟合(易化学习笔记二) 电脑版发表于:2024/6/5 13:43  >#Pytorch 曲线拟合(易化学习笔记二) [TOC] ## 感染与天数预测 ```python import matplotlib.pyplot as plt import torch import torch.nn as nn # 天数 x=[1.,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30] # 感染人数 y=[4.,18,32,175,398,540,273,195,229,666,482,725,739,1075,1011,960,1313,1505,1551,1658,1946,2557,2492,3105,3489,3555,3784,4480,4989,5176] plt.plot(x, y, 'o') plt.show() # 转换为torch的张量类型,才能用它的AI模型 x = torch.tensor(x) # 升维 x = x.unsqueeze(1) print("x shape=",x.shape) # 转换为torch的张量类型,才能用它的AI模型 y = torch.tensor(y) x=x/30 y=y/5176 # 升维 y = y.unsqueeze(1) print("y shape=",y.shape) ## 构建模型(用线性拟合) # 设置内置的线性回归, 输入:1w维 输出:1维 model = nn.Linear(1,1) # 使用均值损失函数 criterion = nn.MSELoss() # 设置优化器为SGD(随机梯度下降,学习速率为10^-5) optimizer = torch.optim.SGD(model.parameters(), lr=1e-5) ## 训练评估 # 轮询次数13000次 num_epochs = 13000 for epoch in range(num_epochs): # 向前传播 out = model(x) loss = criterion(out, y) # 向后传播 # 注意每次迭代都需要清零 optimizer.zero_grad() loss.backward() optimizer.step() # 每1000个batch打印一次cost值,显示一下图像拟合效果 if epoch % 1000 == 0: print('Epoch[{}/{}], loss:{:.6f}'.format(epoch + 1, num_epochs, loss.item())) #//中途,图形显示拟合效果 #predict = model(x) #predict = predict.data.numpy() #plt.plot(x.numpy(), y.numpy(), 'ro', label='样本点集') #plt.plot(x.numpy(), predict, label='拟合后的直线') #plt.show() model.eval() predict = model(x) predict = predict.data.numpy() # o:圆点显示 plt.plot(x.numpy(), y.numpy(), 'o', label='样本点集') # r-: 红色的直线 plt.plot(x.numpy(), predict, 'r-',label='拟合后的直线') plt.show() ```  tn2>我们发现通过一维进行训练,效果很差。 接下来我们添加一层,并添加16个神经元。 ## 曲线拟合(较好的一种) ```python import torch import torch.nn as nn from torch.autograd import Variable import numpy as np import matplotlib.pyplot as plt ## 数据处理 # 天数 x=[1.,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30] # 感染人数 y=[4.,18,32,175,398,540,273,195,229,666,482,725,739,1075,1011,960,1313,1505,1551,1658,1946,2557,2492,3105,3489,3555,3784,4480,4989,5176] # 先转成张量,再转成变量, x = Variable(torch.Tensor(x)) # 只有变量,才可以装载梯度信息,动态计算图,在GPU上加速运算 y = Variable(torch.Tensor(y)) x = x.unsqueeze(1) y = y.unsqueeze(1) # 归一化到1以内的比例时,避免loss值太大时 梯度爆炸 x=x/30 y=y/5176 print("x shape=",x.shape) print("y shape=",y.shape) # 图示 样本点数据 plt.scatter(x.numpy(), y.numpy()) plt.show() ## 构建模型(用多层感知机) # 构建序列容器(逐层叠加,上一层输出是下一层输入) model = nn.Sequential( nn.Linear(1, 16),# 隐藏层(输入维度:1,输出维度16) nn.ReLU(), # 激活函数: 采用ReLU,只提取正值 nn.Linear(16, 1), # 输出层(输入维度:16,输出维度1) ) # 均值损失函数 criterion = nn.MSELoss() # 优化器为SGD(随机梯度下降),学习速率为10^-2 optimizer = torch.optim.SGD(model.parameters(), lr=1e-1) ## 训练评估 y_loss = [] # 训练轮数 num_epochs = 50000 for epoch in range(num_epochs): # 向前传播 # 模型对输入进行预测 preds = model(x) # 计算损失(预测值与 标签值比较) loss = criterion(preds, y) # 向后传播 # 每次迭代都需把,梯度清零(因pytorch默认会累积梯度) optimizer.zero_grad() # 反向传播,计算梯度 loss.backward() # 按学习率减去少量梯度来调整权重 optimizer.step() # 每训练400次,查看一次loss, loss越小,preds值越接近targets if (epoch + 1) % 400 == 0: print('Epoch[{}/{}], loss:{:.8f}'.format(epoch + 1, num_epochs, loss.item())) # 每200次,记录一次损失值 y_loss.append(float(loss.data.numpy())) # 绘制拟合曲线的效果图 y_pre = model(x) plt.title("Fit Curve") plt.plot(x.data.numpy(),y.data.numpy(),'o') plt.plot(x.data.numpy(),y_pre.data.numpy()) plt.legend("y","y_pre") plt.show() # 绘制 loss 值变化曲线图 x_loss = np.arange(0,len(y_loss),1) #print(y_loss) plt.title("Loss") plt.plot(x_loss,y_loss) plt.show() ``` 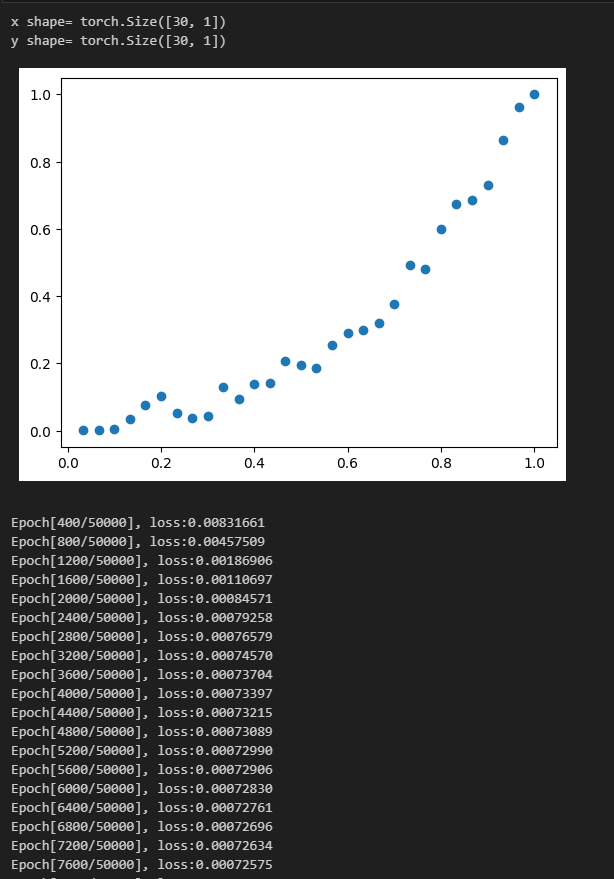 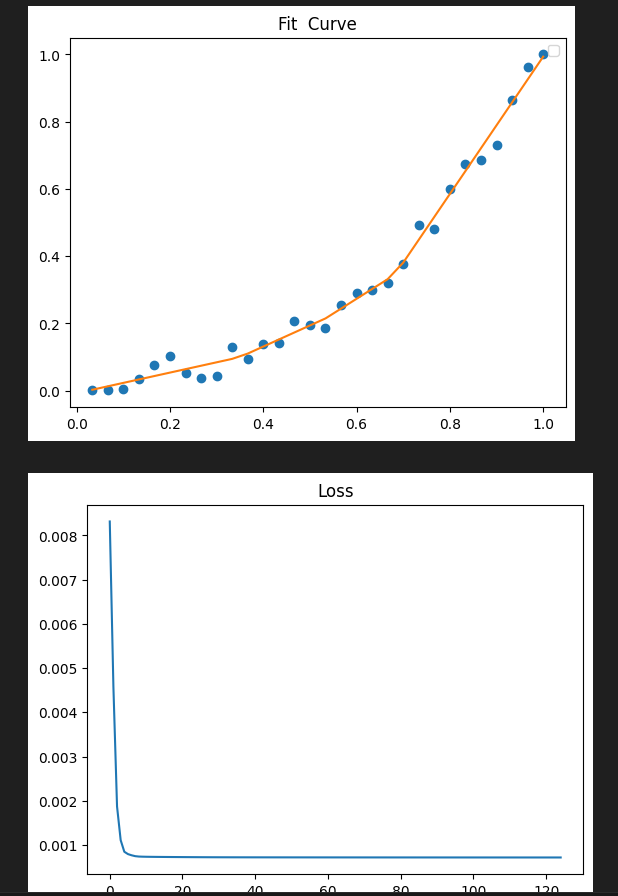 疫情扩散的预测 ------------ ```python import matplotlib.pyplot as plt import pandas as pd import numpy as np import torch import torch.nn as nn from torch.autograd import Variable data = pd.read_csv('usdata.csv',usecols=[0,1,2,3,4]) #//print(data['总确诊']) # 疫情确诊人数(曲线简单) y = np.array(data['累计确诊']) # 可分别查看 新增 治愈 死亡的曲线图。 # 其中新增的曲线较复杂,其它几个曲线简单且类似 x = np.arange(0,len(y)) # 天数 #print(x) #print(y) # 以红色点显示 感染人数 plt.plot(x, y, 'ro', label='ill pepple') plt.show() # 先转成张量,再转成变量,只有变量,才可以装载梯度信息,动态计算图,在GPU上加速运算 x = Variable(torch.Tensor(x)) y = Variable(torch.Tensor(y)) x = x.unsqueeze(1) y = y.unsqueeze(1) # 归一化 x=x/580 y=y/100000000 print("x shape=",x.shape) print("y shape=",y.shape) ## 构建模型 # 用多层感知机 model = nn.Sequential( # 构建序列容器(逐层叠加,上一层输出是下一层输入) nn.Linear(1, 32),# 隐藏层(输入维度:1,输出维度16) nn.ReLU(), # 激活函数: 采用ReLU,只提取正值 nn.Linear(32, 1),# 输出层(输入维度:16,输出维度1) ) # 均值损失函数 criterion = nn.MSELoss() # 优化器为SGD(随机梯度下降),学习速率为10^-1 optimizer = torch.optim.SGD(model.parameters(), lr=1e-1) ## 训练评估 y_loss = [] # 训练轮数 num_epochs = 40000 for epoch in range(num_epochs): # 向前传播 # 模型对输入进行预测 preds = model(x) # 计算损失(预测值与 标签值比较) loss = criterion(preds, y) # 向后传播 # 每次迭代都需把,梯度清零(因pytorch默认会累积梯度) optimizer.zero_grad() # 反向传播,计算梯度 loss.backward() # 按学习率减去少量梯度来调整权重 optimizer.step() # 每训练400次,查看一次loss, loss越小,preds值越接近targets if (epoch + 1) % 400 == 0: print('Epoch[{}/{}], loss:{:.8f}'.format(epoch + 1, num_epochs, loss.item())) # 每400次,记录一次损失值 y_loss.append(float(loss.data.numpy())) # 绘制拟合曲线的效果图 y_pre = model(x) plt.title("Fit Curve") plt.plot(x.data.numpy(),y.data.numpy(),'o') plt.plot(x.data.numpy(),y_pre.data.numpy()) plt.legend("y","y_pre") plt.show() # 绘制 loss 值变化曲线图 x_loss = np.arange(0,len(y_loss),1) #print(y_loss) plt.title("Loss") plt.plot(x_loss,y_loss) plt.show() ```  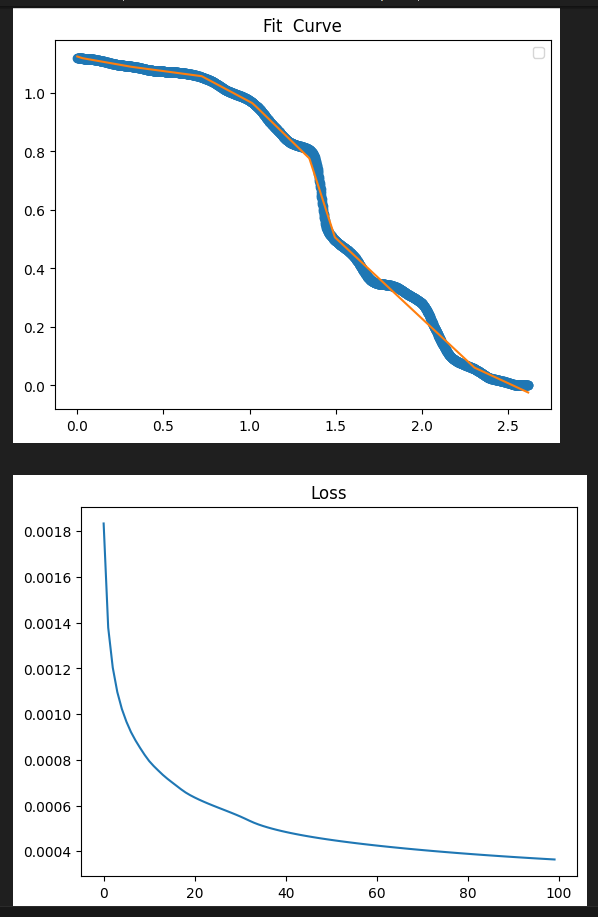 预测新增病例 ------------ ```python import matplotlib.pyplot as plt import pandas as pd import numpy as np import torch import torch.nn as nn from torch.autograd import Variable data = pd.read_csv('usdata.csv',usecols=[0,1,2,3,4]) # 疫情确诊人数(曲线简单) y = np.array(data['新增病例']) # 新增病例 x = np.arange(0,len(y)) # 天数 y = np.nan_to_num(y, nan=0.0) #print(x) #print(y) # 先转成张量,再转成变量,只有变量,才可以装载梯度信息,动态计算图,在GPU上加速运算 x = Variable(torch.Tensor(x)) y = Variable(torch.Tensor(y)) x = x.unsqueeze(1) y = y.unsqueeze(1) print("x shape=",x.shape,x) print("y shape=",y.shape,y) # 归一化 x = x / 580 y = y / 100000000 plt.plot(x, y, 'ro', label='ill pepple') plt.show() #y=y/111820082 ## 构建模型 # 用多层感知机 model = nn.Sequential( # 构建序列容器(逐层叠加,上一层输出是下一层输入) nn.Linear(1, 16),# 隐藏层(输入维度:1,输出维度16) nn.ReLU(), # 激活函数: 采用ReLU,只提取正值 nn.Linear(16, 24),# 输出层(输入维度:16,输出维度1) nn.ReLU(), # 激活函数: 采用ReLU,只提取正值 nn.Linear(24, 32),# 输出层(输入维度:16,输出维度1) nn.ReLU(), # 激活函数: 采用ReLU,只提取正值 nn.Linear(32, 16),# 输出层(输入维度:16,输出维度1) nn.ReLU(), # 激活函数: 采用ReLU,只提取正值 nn.Linear(16, 1),# 输出层(输入维度:16,输出维度1) ) # 均值损失函数 criterion = nn.MSELoss() # 优化器为SGD(随机梯度下降),学习速率为10^-1 optimizer = torch.optim.Adam(model.parameters(), lr=1e-5) #optimizer = torch.optim.SGD(model.parameters(), lr=1e-5) ## 训练评估 y_loss = [] # 训练轮数 num_epochs = 40000 for epoch in range(num_epochs): # 向前传播 # 模型对输入进行预测 preds = model(x) # 计算损失(预测值与 标签值比较) loss = criterion(preds, y) # 向后传播 # 每次迭代都需把,梯度清零(因pytorch默认会累积梯度) optimizer.zero_grad() # 反向传播,计算梯度 loss.backward() # 按学习率减去少量梯度来调整权重 optimizer.step() # 每训练400次,查看一次loss, loss越小,preds值越接近targets if (epoch + 1) % 400 == 0: print('Epoch[{}/{}], loss:{:.8f}'.format(epoch + 1, num_epochs, loss.item())) y_loss.append(float(loss.data.numpy())) #//每400次,记录一次损失值 # 绘制拟合曲线的效果图 y_pre = model(x) plt.title("Fit Curve") plt.plot(x.data.numpy(),y.data.numpy(),'o') plt.plot(x.data.numpy(),y_pre.data.numpy()) plt.legend("y","y_pre") plt.show() # 绘制 loss 值变化曲线图 x_loss = np.arange(0,len(y_loss),1) #print(y_loss) plt.title("Loss") plt.plot(x_loss,y_loss) plt.show() ```