JetBot 自主避障 电脑版发表于:2024/5/23 11:33  >#JetBot 自主避障 [TOC] 数据采集 ------------ tn2>要实现自主避障首先我们需要采集数据,所以我们需要一个采集障碍物和非障碍物的图片。 工作目录在`code`文件夹下面,这个目录我们需要自己创建。 ### 控制界面采集 tn2>创建一个`dataset`的文件夹,并定义一个`getdata.py`的文件,通过采集界面进行采集图片。 ```python import ipywidgets.widgets as widgets from IPython.display import display from jetbot import camera, image image = widgets.Image(format='jpeg',width=224,height=224) display(image) # 创建摄像头 from jetbot import Camera camera = Camera.instance(width=224,height=224) # 关联摄像头和画布 import traitlets from jetbot import bgr8_to_jpeg camera_link = traitlets.dlink((camera, 'value'), (image, 'value'), transform=bgr8_to_jpeg) # 添加释放资源按钮 rb = widgets.Button(description='release carmera') def release_camera(x): camera_link.unlink() camera.stop() print("release camera ok") rb.on_click(release_camera) display(rb) # 创建存储目录 import os blocked_dir = 'dataset/blocked' free_dir = 'dataset/free' try: os.makedirs(free_dir) os.makedirs(blocked_dir) except FileExistsError: print('Dir not create') # 创建采集界面 btn_Layout = widgets.Layout(width='128px',height='64px') free_btn = widgets.Button(description='add free',button_style='success',layout=btn_Layout) block_btn = widgets.Button(description='add block',button_style='danger',layout=btn_Layout) free_count = widgets.IntText(value=len(os.listdir(free_dir))) block_count = widgets.IntText(value=len(os.listdir(blocked_dir))) display(widgets.HBox([free_count,free_btn])) display(widgets.HBox([block_count,block_btn])) # 生成随机ID号 from uuid import uuid1 # 保存文件 def save_snapshot(directory): # 生产文件路径名 image_path = os.path.join(directory,str(uuid1())+'.jpg') with open(image_path, 'wb') as f: f.write(image.value) # 保存无主档的图片 def save_free(): global free_dir, free_count save_snapshot(free_dir) free_count.value = len(os.listdir(free_dir)) # 统计图片的数目 def save_blocked(): global blocked_dir, block_count save_snapshot(blocked_dir) block_count.value = len(os.listdir(blocked_dir)) # 设置free按钮点击时回调函数为save_free free_btn.on_click(lambda x:save_free()) # 设置block按钮点击时回调函数为save_blocked block_btn.on_click(lambda x:save_blocked()) ``` tn2>在同一个目录下又创建一个`ExecGetData.ipynb`执行`getdata.py`文件。 ```python %run getdata.py ``` 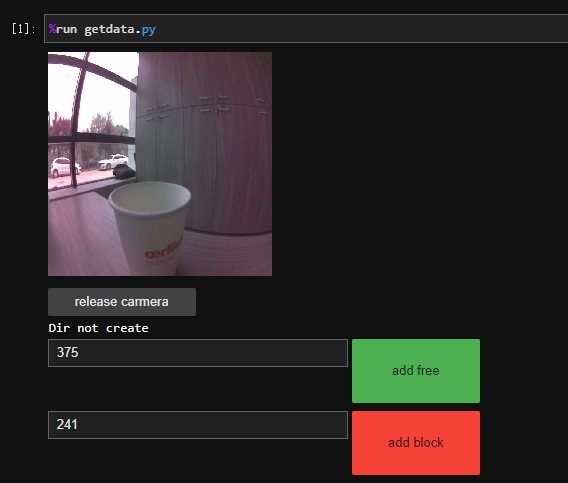 tn2>然后通过不同的角度去拍摄不同的图片,将图片通过点击add free和add block按钮分别添加图片到`dataset/free`和`dataset/blocked`文件夹中。(add free收集没有障碍物的,add block 收集有障碍物的)<br/> 拍摄完成后点击`release carmera`进行释放。<br/> 在收集图片的时候最好都多收集些,至少几百张。 tn>当你收集一段时间后就会发现,每次都需要切换角度太麻烦了。所以我改用了使用手柄进行采集。 ### 手柄采集 tn2>我这里直接贴代码了,如果不知道如何对接手柄的可以参考我这篇文章(https://www.tnblog.net/hb/article/details/8376)。 贴部分代码,完整代码在`jetbot/notebooks/teleoperation`,只修改了最后几段的代码。 ```python import uuid #import subprocess #subprocess.call(['mkdir', '-p', 'snapshots']) snapshot_image = widgets.Image(format='jpeg', width=300, height=300) def save_free_snapshot(change): if change['new']: file_path = '../code/dataset/free/' + str(uuid.uuid1()) + '.jpg' with open(file_path, 'wb') as f: f.write(image.value) snapshot_image.value = image.value def save_block_snapshot(change): if change['new']: file_path = '../code/dataset/blocked/' + str(uuid.uuid1()) + '.jpg' with open(file_path, 'wb') as f: f.write(image.value) snapshot_image.value = image.value controller.buttons[4].observe(save_free_snapshot, names='value') controller.buttons[5].observe(save_block_snapshot, names='value') display(widgets.HBox([image, snapshot_image])) display(controller) ```  tn2>左边`L`第一个按钮就是拍照采集空白的图片(对应的按钮下标是`4`),右边`R`第一个按钮就是采集有障碍物的图片(对应的按钮下标是`5`)。 然后我们通过摇杆移动小车就可以不断的采集了。 下面两行代码进行查询文件夹的数量 ```python import os block_count = len(os.listdir('../code/dataset/blocked/')) block_count ``` ```python block_count = len(os.listdir('../code/dataset/free/')) block_count ```  AI训练模型 ------------ tn2>采集的图片后,我们通过`alexnet`模型进行训练,并在训练完成的时候保存最好的模型记录(`best_model.pth`)。 创建一个`train.ipynb`添加如下代码进行跑模型。 (由于在训练模型中遇到了一些代码错误,所以我拉到本地的`jupyter-notebook`跑了一下,当然`dataset`也拉到本地中了) ```python import torch # 导入视觉库 import torchvision # 导入数据集类 import torchvision.datasets as datasets # 导入视觉库里的转换类 import torchvision.transforms as transforms # 导入视觉库 import torchvision.models as models # 导入torch库里的神经网络类里的functional函数 import torch.nn.functional as F # 采用迁移学习:在已训练好的模型上(已识别大部分特征),再训练(用较少的数据训练,识别新的个性特征) ``` ```python # 数据预处理和增强 transform = transforms.Compose([ transforms.ColorJitter(0.1, 0.1, 0.1, 0.1), transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) # 自定义数据集加载器,跳过无法识别的图像并打印出错路径 class CustomImageFolder(datasets.ImageFolder): def __getitem__(self, index): path, target = self.samples[index] try: sample = self.loader(path) #print(f'path {path}') if self.transform is not None: sample = self.transform(sample) return sample, target except UnidentifiedImageError: print(f"UnidentifiedImageError: Skipping file at path {path}") return None # 加载数据集 dataset = CustomImageFolder('dataset', transform=transform) # 把数据集划分为训练集和测试集 train_dataset, test_dataset = torch.utils.data.random_split(dataset,[len(dataset) - 50,50]) # 设置训练集加载方式 预加载数据集,每批加载图片个数,混洗,不启动并行加载 train_loader = torch.utils.data.DataLoader( train_dataset, batch_size=8, shuffle=True, num_workers=0 ) # 测试集 test_loader = torch.utils.data.DataLoader( test_dataset, batch_size=8, shuffle=True, num_workers=0 ) ``` ```python # AI 训练 第二个 # 导入已训练好的模型alexnet # 自动下载alexnet模型 model = models.alexnet(pretrained=True) # 针对1000个类别标签的数据集进行训练,而这里只有两类(阻挡和不阻挡) model.classifier[6] = torch.nn.Linear(model.classifier[6].in_features,2) # 把模型传输到 GPU上执行 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = model.to(device) ``` ```python # 导入torch库里的优化器类 import torch.optim as optim # 设置训练的轮数 NUM_EPOCHS = 30 # 训练好后输出的模型名 BEST_MODEL_PATH = 'bast_model.pth' base_accuracy = 0.0 # 优化器采用随机梯度下降法(SGD) optimizer = optim.SGD(model.parameters(),lr=0.001,momentum=0.9) # 多轮训练 for epoch in range(NUM_EPOCHS): model.train() # 训练模式 for images, labels in iter(train_loader): images = images.to(device) #print(f'images.shape {images.shape}') labels = labels.to(device) optimizer.zero_grad() outputs = model(images) loss = F.cross_entropy(outputs, labels) # 采用交叉熵做损失函数 loss.backward() optimizer.step() #print(f'train labels {labels} loss: {loss} preds {outputs.argmax(1)}') model.eval() # 评估模式 test_error_count = 0.0 for images, labels in iter(test_loader): images = images.to(device) labels = labels.to(device) outputs = model(images) #print(f'test images.shape {images.shape} outputs shape{outputs.shape}') preds = outputs.argmax(1) print(f'test labels {labels} preds: {preds} sum {torch.abs(labels - preds)}') test_error_count += float(torch.sum(torch.abs(labels - preds))) # 计算误差时,仅考虑实际有效的样本数量 #batch_error_count = torch.sum(labels != preds) #test_error_count += batch_error_count.item() print(f'test_error_count {test_error_count}') test_accuracy = 1.0 - float(test_error_count) / float(len(test_dataset)) # 输出测试的准确率 print('%d: %f' % (epoch, test_accuracy)) # 当本轮的精度比上一轮的高,才保存模型的参数(权重值) if test_accuracy > base_accuracy: torch.save(model.state_dict(),BEST_MODEL_PATH) best_accuracy = test_accuracy ```  tn2>训练好模型后我们就可以开始部署代码了。 对了,这里我是以一个杯子为障碍物。 AI部署 ------------ tn2>创建一个`AIDeploy.ipynb`文件,写我们的AI部署代码。 ### 载入模型 ```python import torch import torchvision # 构建alexnet模型 model = torchvision.models.alexnet(pretrained=False) # 修改最后一层的输出特征数设为2 model.classifier[6] = torch.nn.Linear(model.classifier[6].in_features, 2) # 导入已训练好模型的权重值 model.load_state_dict(torch.load('bast_model.pth')) # 把模型从cpu中,传输到gpu中 device = torch.device('cuda') model = model.to(device) ``` ### 预处理: 将图像从相机格式 转换为 神经网络输入格式 ```python import cv2 import numpy as np mean = 255.0 * np.array([0.485, 0.456, 0.406]) stdev = 255.0 * np.array([0.229, 0.224, 0.225]) # 归一化 normalize = torchvision.transforms.Normalize(mean, stdev) def preprocess(camera_value): global device, normalize x = camera_value # 把相机BGR 转换为 模型需要的 RGB格式 x = cv2.cvtColor(x, cv2.COLOR_BGR2RGB) # 从HWC布局转为 模型需要的 CHW 布局 (C:通道数 H:高度 W:宽度) x = x.transpose((2, 0, 1)) x = torch.from_numpy(x).float() # 数据归一化处理,都变成0~1间的数据分布 x = normalize(x) # 将数据从 CPU 内存传输到 GPU 内存 x = x.to(device) # 添加批次维度 x = x[None, ...] return x ``` ### 监控界面 ```python import traitlets from IPython.display import display import ipywidgets.widgets as widgets from jetbot import Camera, bgr8_to_jpeg camera = Camera.instance(width=224, height=224) image = widgets.Image(format='jpeg', width=224, height=224) #//滑块控制 阻挡的概率 blocked_slider = widgets.FloatSlider(description='blocked', min=0.0, max=1.0, orientation='vertical') #//滑块控制 小车速度 speed_slider = widgets.FloatSlider(description='speed', min=0.0, max=0.5, value=0.0, step=0.01, orientation='horizontal') camera_link = traitlets.dlink((camera, 'value'), (image, 'value'), transform=bgr8_to_jpeg) display(widgets.VBox([widgets.HBox([image, blocked_slider]), speed_slider])) ``` 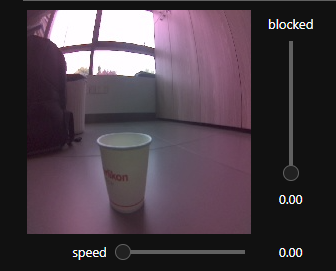 ### 绕过障碍物: 不断监听相机值,阻挡概率小于0.5则直行,否则原地左转 ```python from jetbot import Robot robot = Robot() import torch.nn.functional as F import time def update(change): global blocked_slider, robot x = change['new'] x = preprocess(x) y = model(x) # 归一化,输出0~1范围,方便用于计算阻挡的概率 y = F.softmax(y, dim=1) prob_blocked = float(y.flatten()[0]) blocked_slider.value = prob_blocked # 阻挡概率小于50%,则直行 if prob_blocked < 0.5: robot.forward(speed_slider.value) else: #//否则,原地左转 robot.left(speed_slider.value) time.sleep(0.001) # 我们调用一词函数来进行初始化 update({'new': camera.value}) # 监听相机值的变化 camera.observe(update, names='value') ``` ### 退出:释放资源 ```python import time release_btn = widgets.Button(description='release resource') def release_resource(x): camera.unobserve(update, names='value') #//取消监听相机 time.sleep(0.1) #//添加小的sleep 以确保帧图像传输完成 robot.stop() #//停止小车 camera_link.unlink() #//取消相机连接 -> 不再把视频流 传输到 浏览器 camera.stop() #//停止相机 print("release resource go") release_btn.on_click(release_resource) display(release_btn) ``` ### 进行测试 tn2>我们拖动`speed`到`0.1`左右,小车会自动前进。 识别到障碍物会向左拐,旁边`blocked`检测是否遇到障碍物。  tn2>这里是视频:https://www.bilibili.com/video/BV12y411a7ZT/?spm_id_from=333.999.0.0&vd_source=0a9564bfc7982839767a99fe6bf60155

