Pytorch Mnist分类任务 电脑版发表于:2023/12/25 17:56  >#Pytorch Mnist分类任务 [TOC] <a href="https://colab.research.google.com/drive/1t3a1nrACES1HO0RCzZbBMnP06wdY49An?usp=sharing" target="_blank"> <img alt="Google Colab" src="https://img.shields.io/badge/Open_the_colab-%23e87109?logo=https%3A%2F%2Fssl.gstatic.com%2Fcolaboratory-static%2Fcommon%2Facc37fa50857cc16c7a72c9c57f423f6%2Fimg%2Ffavicon.ico&link=https%3A%2F%2Fcolab.research.google.com%2Fdrive%2F1t3a1nrACES1HO0RCzZbBMnP06wdY49An%3Fusp%3Dsharing"> </a> ## Mnist分类任务 ### 了解目标 tn2>——网络基本构建与训练方法,常用函数解析 ——torch.nn.functional模块 ——nn.Module模块 ## 读取Mnist数据集 tn2>执行下面点代码会自动进行下载。 或者从我的github中去下载data文件夹<a href="https://github.com/AiDaShi/learningpytorch/tree/main/010_015%EF%BC%9A%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%E5%AE%9E%E6%88%98%E5%88%86%E7%B1%BB%E4%B8%8E%E5%9B%9E%E5%BD%92%E4%BB%BB%E5%8A%A1/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%E5%AE%9E%E6%88%98%E5%88%86%E7%B1%BB%E4%B8%8E%E5%9B%9E%E5%BD%92%E4%BB%BB%E5%8A%A1" target="_blank">下载</a>的内容 ```python %matplotlib inline ``` ```python from pathlib import Path import requests DATA_PATH = Path("data") PATH = DATA_PATH / "mnist" PATH.mkdir(parents=True, exist_ok=True) URL = "http://deeplearning.net/data/mnist/" FILENAME = "mnist.pkl.gz" if not (PATH / FILENAME).exists(): content = requests.get(URL + FILENAME).content (PATH / FILENAME).open("wb").write(content) ``` ```python import pickle import gzip # 解压包 with gzip.open((PATH / FILENAME).as_posix(), "rb") as f: print(f) ((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1") ``` ><gzip _io.BufferedReader name='data/mnist/mnist.pkl.gz' 0x7a05301f7400> ```python x_train.shape ``` >(50000, 784) 50000个数据。<br/> 784是mnist数据集每个样本的像素点个数(`28*28*1`)<br/> 将 `x_train` 数组中的第一个图像(已经被重新塑形为 28x28 像素的二维数组)显示为一个灰度图像。 ```python from matplotlib import pyplot import numpy as np # imshow 函数来显示图像 pyplot.imshow(x_train[0].reshape((28, 28)), cmap="gray") print(x_train.shape) ``` >(50000, 784) 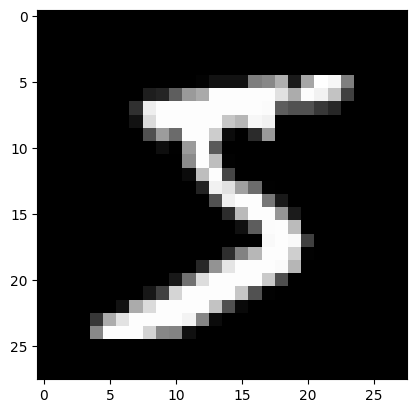   tn2>注意数据需转换成tensor才能参与后续建模训练 ```python import torch # 将这些类型转换成torch.tensor类型 x_train, y_train, x_valid, y_valid = map( torch.tensor, (x_train, y_train, x_valid, y_valid) ) n, c = x_train.shape x_train, x_train.shape, y_train.min(), y_train.max() print(x_train, y_train) print(x_train.shape) print(y_train.min(), y_train.max()) ``` >tensor([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) tensor([5, 0, 4, ..., 8, 4, 8]) torch.Size([50000, 784]) tensor(0) tensor(9) ## torch.nn.functional 很多层和函数在这里都会见到 torch.nn.functional中有很多功能,后续会常用的。那什么时候使用nn.Module,什么时候使用nn.functional呢?一般情况下,如果模型有可学习的参数,最好用nn.Module,其他情况nn.functional相对更简单一些 ```python import torch.nn.functional as F # 这里定义了损失函数 loss_func 为交叉熵损失(Cross Entropy Loss),它是一种常用于多类分类问题的损失函数。 loss_func = F.cross_entropy # 在这个函数内部,输入 xb 通过矩阵乘法(mm)与 weights 相乘,并加上偏置 bias。 # 这是一个非常基础的线性层(也称为全连接层或密集层)的实现。 def model(xb): return xb.mm(weights) + bias ``` ```python torch.randn([784, 10], dtype = torch.float, requires_grad = True).shape ``` >torch.Size([784, 10]) 接下来做一个简单的测试 ```python bs = 64 # 取出它们的64个样本标签 xb = x_train[0:bs] # a mini-batch from x yb = y_train[0:bs] # 随机获取784个数据和10个维度 weights = torch.randn([784, 10], dtype = torch.float, requires_grad = True) bs = 64 # 设置一个偏执b bias = torch.zeros(10, requires_grad=True) # 调用交叉熵损失函数,传入模型输出和对应的真实标签 yb,计算这个小批量数据上的损失值 print(loss_func(model(xb), yb)) ``` >tensor(14.8633, grad_fn=`<NllLossBackward0>`) ## 创建一个model来更简化代码 tn2>——必须继承nn.Module且在其构造函数中需调用nn.Module的构造函数 ——无需写反向传播函数,nn.Module能够利用autograd自动实现反向传播 ——Module中的可学习参数可以通过named_parameters()或者parameters()返回迭代器 ```python from torch import nn # 定义一个全连接的类继承 nn.Module class Mnist_NN(nn.Module): def __init__(self): super().__init__() # 第一层隐藏层784条数据点,输出128个像素点 self.hidden1 = nn.Linear(784, 128) # 第二层隐藏层128条数据点,输出256个像素点 self.hidden2 = nn.Linear(128, 256) # 输出10个 self.out = nn.Linear(256, 10) # 这里按照50%杀死这个东西 self.dropout = nn.Dropout(0.5) # 前向传播 # x: batch 特征 def forward(self, x): x = F.relu(self.hidden1(x)) x = self.dropout(x) x = F.relu(self.hidden2(x)) x = self.dropout(x) x = self.out(x) return x ``` tn>过拟合:就是稍微超出的意料以外的事情就解决不了了。 tn2>Dropout是一种用来防止神经网络过拟合的技术。 Dropout 就像是在团队做项目时,为了确保每个人都能独立解决问题,随机让一些成员休息,让剩下的成员完成任务。 ```python net = Mnist_NN() print(net) ``` >Mnist_NN( (hidden1): Linear(in_features=784, out_features=128, bias=True) (hidden2): Linear(in_features=128, out_features=256, bias=True) (out): Linear(in_features=256, out_features=10, bias=True) (dropout): Dropout(p=0.5, inplace=False) ) tn2>权重参数pytorch已经自动去做了,可以打印我们定义好名字里的权重和偏置项 ```python for name, parameter in net.named_parameters(): print(name, parameter,parameter.size()) ``` >hidden1.weight Parameter containing: tensor([[-0.0328, -0.0041, -0.0332, ..., 0.0327, -0.0128, -0.0318], [ 0.0217, 0.0024, -0.0190, ..., 0.0107, 0.0091, 0.0025], [-0.0261, -0.0255, 0.0267, ..., 0.0205, 0.0028, 0.0088], ..., [-0.0247, 0.0210, 0.0056, ..., 0.0177, 0.0318, -0.0213], [-0.0099, -0.0090, 0.0282, ..., 0.0173, 0.0075, 0.0203], [ 0.0192, -0.0161, 0.0318, ..., 0.0018, -0.0307, -0.0248]], requires_grad=True) torch.Size([128, 784]) hidden1.bias Parameter containing: tensor([ 0.0075, -0.0238, 0.0057, 0.0296, 0.0087, 0.0049, -0.0153, -0.0183, 0.0347, 0.0344, 0.0060, -0.0176, -0.0225, 0.0215, -0.0233, -0.0063, 0.0161, 0.0226, -0.0232, 0.0285, 0.0304, 0.0317, 0.0339, 0.0270, 0.0333, 0.0028, 0.0089, 0.0266, -0.0273, 0.0142, -0.0010, 0.0252, 0.0191, 0.0050, 0.0018, 0.0161, -0.0268, -0.0108, -0.0090, -0.0190, -0.0178, 0.0268, -0.0154, -0.0314, -0.0038, -0.0188, -0.0339, -0.0073, -0.0079, -0.0311, -0.0124, 0.0114, -0.0226, -0.0096, -0.0026, 0.0343, 0.0335, -0.0203, 0.0045, 0.0063, 0.0241, 0.0263, -0.0321, 0.0307, 0.0016, 0.0280, 0.0122, 0.0261, 0.0068, -0.0249, -0.0237, -0.0185, -0.0329, -0.0004, -0.0172, 0.0108, -0.0113, 0.0064, -0.0283, 0.0295, -0.0295, -0.0127, -0.0013, -0.0268, -0.0066, 0.0285, -0.0191, 0.0210, 0.0338, -0.0249, 0.0155, 0.0321, -0.0040, 0.0180, 0.0344, -0.0347, 0.0165, 0.0023, 0.0074, 0.0228, -0.0304, 0.0181, 0.0220, 0.0356, -0.0170, 0.0337, 0.0106, -0.0328, 0.0177, -0.0061, -0.0331, 0.0149, -0.0258, 0.0126, -0.0142, 0.0208, 0.0303, -0.0050, -0.0346, 0.0241, -0.0100, 0.0196, 0.0199, 0.0307, -0.0347, -0.0335, -0.0148, -0.0116], requires_grad=True) torch.Size([128]) hidden2.weight Parameter containing: tensor([[-0.0415, 0.0363, -0.0117, ..., -0.0717, -0.0825, 0.0568], [-0.0881, -0.0485, -0.0498, ..., 0.0801, -0.0196, 0.0175], [ 0.0238, -0.0028, -0.0533, ..., -0.0325, -0.0531, 0.0269], ..., [-0.0340, 0.0684, 0.0152, ..., 0.0156, -0.0137, 0.0137], [ 0.0845, 0.0142, 0.0351, ..., 0.0205, 0.0393, -0.0280], [-0.0203, 0.0234, -0.0095, ..., -0.0314, 0.0578, 0.0760]], requires_grad=True) torch.Size([256, 128]) hidden2.bias Parameter containing: tensor([-0.0750, -0.0227, -0.0355, 0.0107, 0.0372, -0.0180, 0.0054, 0.0144, 0.0727, -0.0014, 0.0665, -0.0815, 0.0204, -0.0269, -0.0394, -0.0101, 0.0557, -0.0071, 0.0093, -0.0189, 0.0421, -0.0420, 0.0730, 0.0306, -0.0621, 0.0205, -0.0373, -0.0240, 0.0746, -0.0010, 0.0851, 0.0295, 0.0746, -0.0051, -0.0161, -0.0319, -0.0825, -0.0688, -0.0355, 0.0300, 0.0171, 0.0704, 0.0313, 0.0128, -0.0405, 0.0451, 0.0620, 0.0013, 0.0743, -0.0847, -0.0519, -0.0186, 0.0130, 0.0066, -0.0200, 0.0855, -0.0672, -0.0728, 0.0399, -0.0502, -0.0539, 0.0660, 0.0005, 0.0883, -0.0112, -0.0837, -0.0266, 0.0834, 0.0293, 0.0764, -0.0463, -0.0436, -0.0745, -0.0036, 0.0383, 0.0211, 0.0819, -0.0782, -0.0388, -0.0278, 0.0705, -0.0281, -0.0024, -0.0602, -0.0862, 0.0425, -0.0171, -0.0202, -0.0751, -0.0566, -0.0656, -0.0211, -0.0436, 0.0478, 0.0520, -0.0748, 0.0009, -0.0453, 0.0438, -0.0104, -0.0213, 0.0543, 0.0329, -0.0256, -0.0528, -0.0052, -0.0642, 0.0775, 0.0754, -0.0148, -0.0383, 0.0835, 0.0339, -0.0145, 0.0117, 0.0666, 0.0399, 0.0688, 0.0444, -0.0127, -0.0684, 0.0625, 0.0570, -0.0473, 0.0485, 0.0330, 0.0301, -0.0028, 0.0111, -0.0041, 0.0812, -0.0294, -0.0300, -0.0594, -0.0459, -0.0716, -0.0739, -0.0753, -0.0818, 0.0646, 0.0025, 0.0087, 0.0172, 0.0531, -0.0699, 0.0239, -0.0138, 0.0554, -0.0389, 0.0261, -0.0288, -0.0419, 0.0460, -0.0064, 0.0521, -0.0205, -0.0102, 0.0688, -0.0292, -0.0881, -0.0692, -0.0081, 0.0342, 0.0541, 0.0518, -0.0035, 0.0215, -0.0777, -0.0724, 0.0223, 0.0678, -0.0813, -0.0026, 0.0448, -0.0503, -0.0437, 0.0359, -0.0609, 0.0789, -0.0552, -0.0107, 0.0725, 0.0681, 0.0636, 0.0475, -0.0358, -0.0339, 0.0128, -0.0524, -0.0653, 0.0299, -0.0373, 0.0414, 0.0719, -0.0225, 0.0462, 0.0668, -0.0862, -0.0476, -0.0207, 0.0787, 0.0096, 0.0715, -0.0200, -0.0773, -0.0218, -0.0343, -0.0537, -0.0748, 0.0660, -0.0271, -0.0641, -0.0009, 0.0113, -0.0536, 0.0161, -0.0438, 0.0354, -0.0017, -0.0552, 0.0071, 0.0830, 0.0803, -0.0833, 0.0179, -0.0568, -0.0502, -0.0402, -0.0780, 0.0443, -0.0329, -0.0411, 0.0672, -0.0847, 0.0255, -0.0144, 0.0439, 0.0461, 0.0283, 0.0061, 0.0805, 0.0237, -0.0381, -0.0704, -0.0729, -0.0086, -0.0042, 0.0618, 0.0416, -0.0214, -0.0858, 0.0262, -0.0148, -0.0330, 0.0774, 0.0353], requires_grad=True) torch.Size([256]) out.weight Parameter containing: tensor([[-0.0167, -0.0487, -0.0353, ..., -0.0388, 0.0404, 0.0401], [-0.0403, -0.0562, 0.0585, ..., -0.0038, -0.0478, 0.0184], [-0.0057, -0.0612, -0.0607, ..., 0.0030, 0.0144, 0.0002], ..., [-0.0290, 0.0233, 0.0219, ..., -0.0163, -0.0378, -0.0244], [ 0.0316, -0.0497, 0.0182, ..., -0.0062, 0.0361, 0.0335], [ 0.0476, -0.0497, -0.0115, ..., -0.0212, -0.0204, 0.0286]], requires_grad=True) torch.Size([10, 256]) out.bias Parameter containing: tensor([-0.0288, 0.0392, -0.0213, -0.0028, -0.0356, 0.0588, 0.0381, 0.0176, 0.0029, -0.0034], requires_grad=True) torch.Size([10]) ## 使用TensorDataset和DataLoader来简化 tn2>获取训练集和验证集 ```python from torch.utils.data import TensorDataset from torch.utils.data import DataLoader # 将x_train, y_train封装数据成TensorDataset格式 train_ds = TensorDataset(x_train, y_train) # DataLoader 把train_ds打包给cpu。 # batch_size=bs 所以以每64byte打包给cpu。(数值可以为:64、128、256自定义) # shuffle=True 打乱顺序 train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True) valid_ds = TensorDataset(x_valid, y_valid) valid_dl = DataLoader(valid_ds, batch_size=bs * 2) ``` ```python # 获取数据的方法 def get_data(train_ds, valid_ds, bs): return ( DataLoader(train_ds, batch_size=bs, shuffle=True), DataLoader(valid_ds, batch_size=bs * 2), ) ``` tn2>一般在训练模型时加上`model.train()`,这样会正常使用Batch Normalization和 Dropout 测试的时候一般选择`model.eval()`,这样就不会使用Batch Normalization和 Dropout 我们数据有了,模型有了,接着我们需要定义一个fit函数作为一个训练的方法。 ```python import numpy as np # steps 训练次数 # model 训练模型 # loss_func 损失函数 # opt 优化器 # train_dl 训练集 # valid_dl 验证集 def fit(steps, model, loss_func, opt, train_dl, valid_dl): # 循环次数训练 for step in range(steps): # 训练模式,更新w和b model.train() for xb, yb in train_dl: loss_batch(model, loss_func, xb, yb, opt) # 验证模式是不进行更新的 model.eval() with torch.no_grad(): # zip 多个数值按照下标打包成的字典 # zip(*) 表示解包,这里解出来两个结果 losses, nums = zip( *[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl] ) # 计算验证集的结果 # np.multiply 乘法 losses*nums再相加=总损失 # 除以总数量=等于平均损失 val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums) print('当前step:'+str(step), '验证集损失:'+str(val_loss)) ``` ```python from torch import optim def get_model(): # 定义模型 model = Mnist_NN() # SGD 是梯度下降,model.parameters()全更新,lr是学习率 return model, optim.SGD(model.parameters(), lr=0.001) # return model, optim.Adam(model.parameters(), lr=0.001) ``` ```python def loss_batch(model, loss_func, xb, yb, opt=None): # 计算我们的损失 # model(xb) 预测值 # yb 真实值 loss = loss_func(model(xb), yb) if opt is not None: # 反向传播 loss.backward() # 更新参数 w、b opt.step() # 梯度清零(pytorch会进行累加所以要清理) opt.zero_grad() # 返回结果和总数,因为要计算平均 return loss.item(), len(xb) ``` ## 三行搞定! ```python train_dl, valid_dl = get_data(train_ds, valid_ds, bs) model, opt = get_model() fit(25, model, loss_func, opt, train_dl, valid_dl) ``` >当前step:0 验证集损失:2.2804982192993166 当前step:1 验证集损失:2.2535984596252443 当前step:2 验证集损失:2.2155482387542724 当前step:3 验证集损失:2.1587322315216064 当前step:4 验证集损失:2.073927662277222 当前step:5 验证集损失:1.9530213565826415 当前step:6 验证集损失:1.7918485031127929 当前step:7 验证集损失:1.5947792680740356 当前step:8 验证集损失:1.3865230758666993 当前step:9 验证集损失:1.199518952178955 当前step:10 验证集损失:1.0501244049072265 当前step:11 验证集损失:0.936854721069336 当前step:12 验证集损失:0.8493013159751892 当前step:13 验证集损失:0.7818769567489624 当前step:14 验证集损失:0.7263854211807251 当前step:15 验证集损失:0.680776209449768 当前step:16 验证集损失:0.6429182374954223 当前step:17 验证集损失:0.6104381775856018 当前step:18 验证集损失:0.5826128076553345 当前step:19 验证集损失:0.5583832846164704 当前step:20 验证集损失:0.5369707444667816 当前step:21 验证集损失:0.51700747590065 当前step:22 验证集损失:0.5001905463218689 当前step:23 验证集损失:0.4858731382369995 当前step:24 验证集损失:0.4717775447368622 ```python correct = 0 total = 0 # 循环获取每一次验证集的预测 for xb, yb in valid_dl: outputs = model(xb) _, predicted = torch.max(outputs.data, 1) # 返回最大值和最大值的索引 total += yb.size(0) correct += (predicted == yb).sum().item() print('准确率:%d %%' % (100 * correct / total)) ``` >准确率:87 % ## Adam测试 tn2>接下来我们使用Adam来进行测试 ```python from torch import optim def get_model(): # 定义模型 model = Mnist_NN() # SGD 是梯度下降,model.parameters()全更新,lr是学习率 # return model, optim.SGD(model.parameters(), lr=0.001) return model, optim.Adam(model.parameters(), lr=0.001) ``` 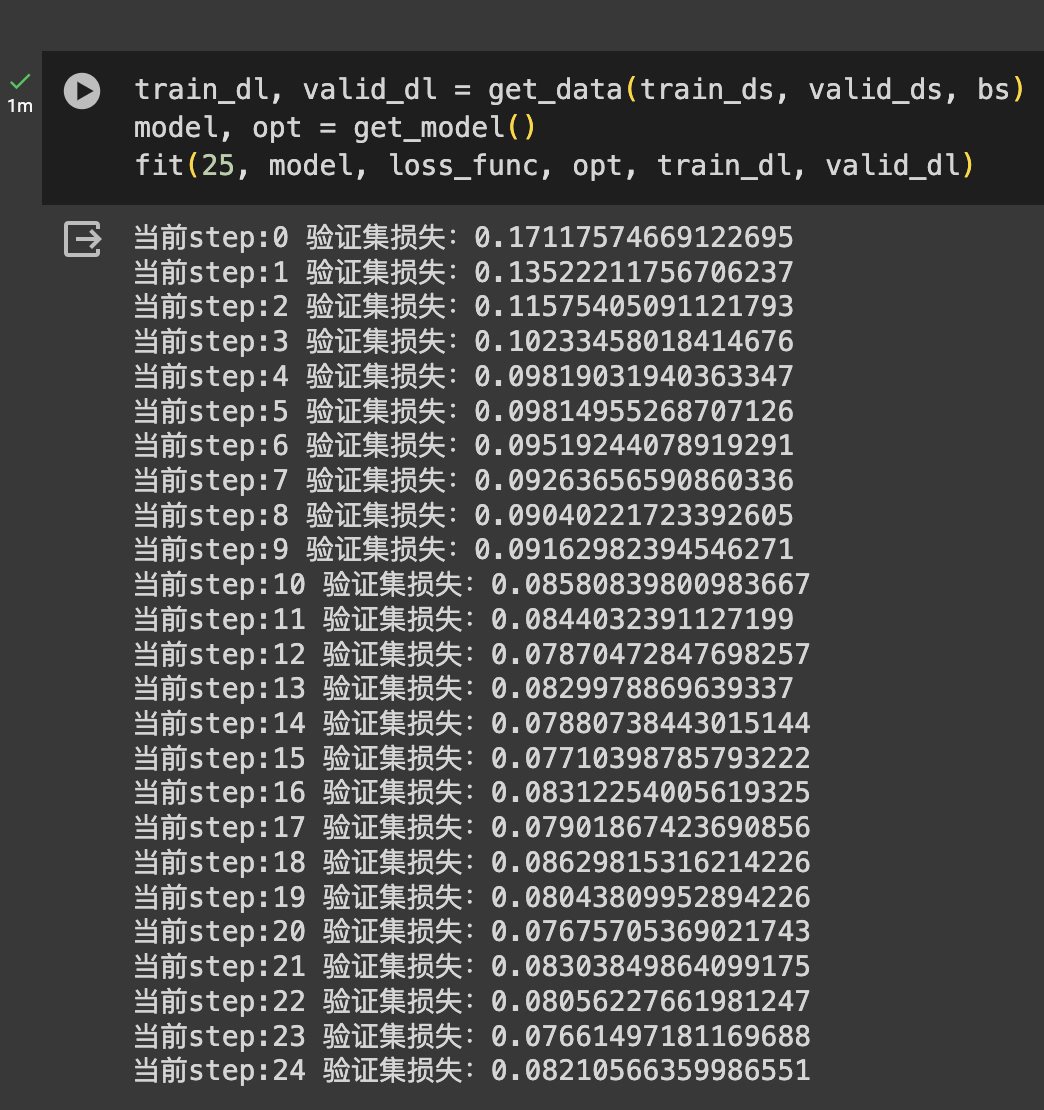 tn2>通过切换优化器发现 SGD:下降得慢,而且训练25次只有85%-89%左右 Adam:下降得快,而且训练25次只有97%左右

