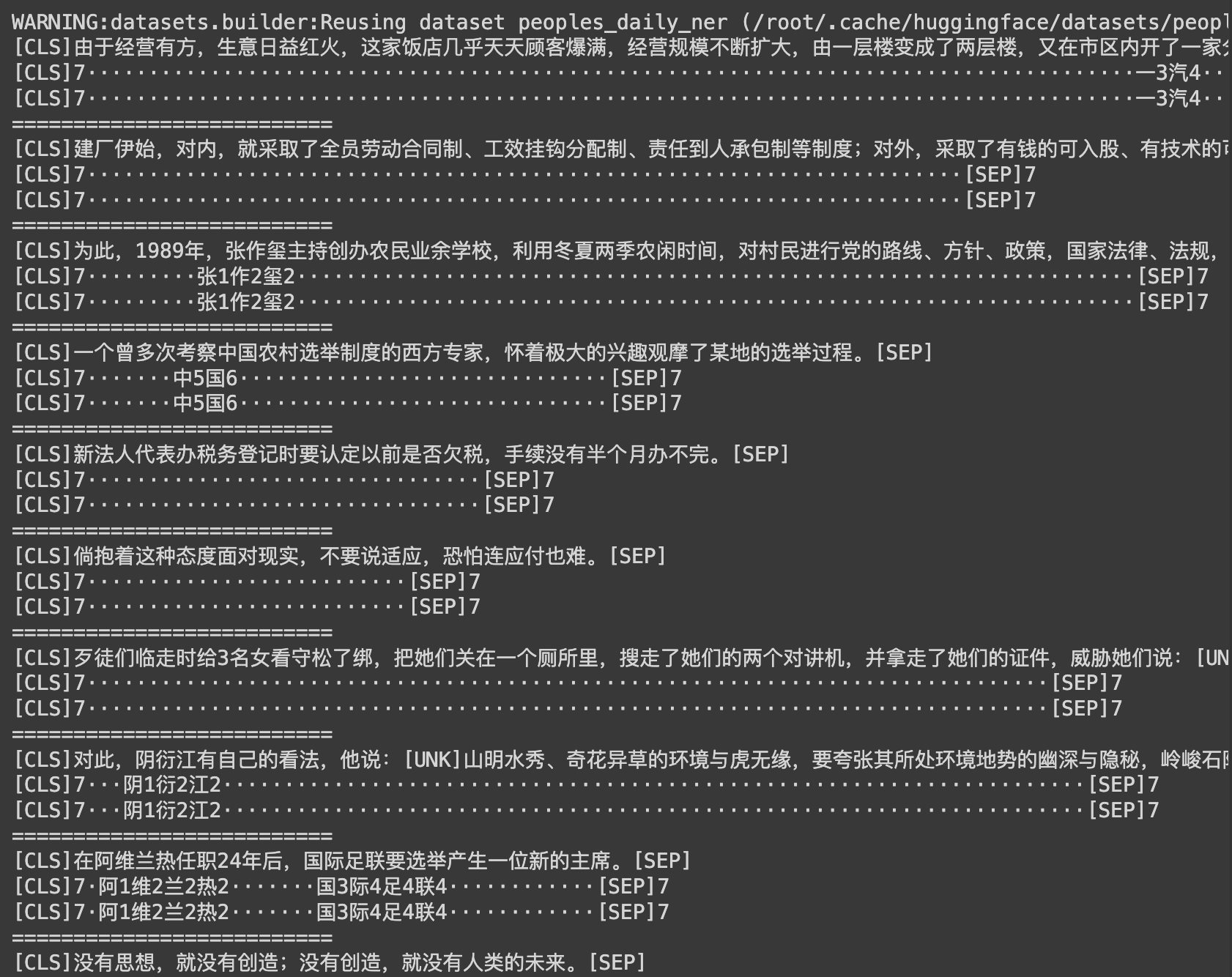
HugginFace 中文命名实体识别(学习笔记) 电脑版发表于:2023/10/31 21:23  >#HugginFace 中文命名实体识别(学习笔记) [TOC] ## 任务简介 tn2>简单来说就是的识别人名、机构名、地名。 ## 数据集的介绍 tn2>本章所使用的数据集是`people_daily_ner`数据集。 `people_daily_ner`数据集标签对照表如下所示。 | 标签 | 描述 | | ------------ | ------------ | | `O` | 表示不属于一个命名实体 | | `B-PER` | 表示人名的开始。 | | `I-PER` | 表示的人名的中间和结尾部分。 | | `B-ORG` | 表示组织机构名的开始部分。 | | `I-ORG` | 表示组织机构名的中间和结尾部分。 | | `B-LOC` | 表示地名的开始。 | | `I-LOC` | 标识地名的中间和结尾部分。 | ## 实现代码 ### 准备数据集 #### 使用编码工具 tn2>`hfl/rbt3`编码器的编码结果与`bert-base-chinese`编码器相同,使用`hfl/rbt3`编码基本不需要任何的学习过程,此处首先加载该编码器,代码如下: ```python # 加载编码器 from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained('hfl/rbt3') tokenizer ```  tn2>进行试算一次,更加清晰的观察编码工具的输入和输出: ```python # 编码测试 out = tokenizer.batch_encode_plus( [[ '海', '钓', '比', '赛', '地', '点', '在', '厦', '门', '与', '金', '门', '之', '间', '的', '海', '域', '。' ], [ '这', '座', '依', '山', '傍', '水', '的', '博', '物', '馆', '由', '国', '内', '一', '流', '的', '设', '计', '师', '主', '持', '设', '计', '。' ]], truncation=True, padding=True, return_tensors='pt', max_length=20, is_split_into_words=True) #还原编码为句子 print(tokenizer.decode(out['input_ids'][0])) print(tokenizer.decode(out['input_ids'][1])) for k, v in out.items(): print(k, v) ``` 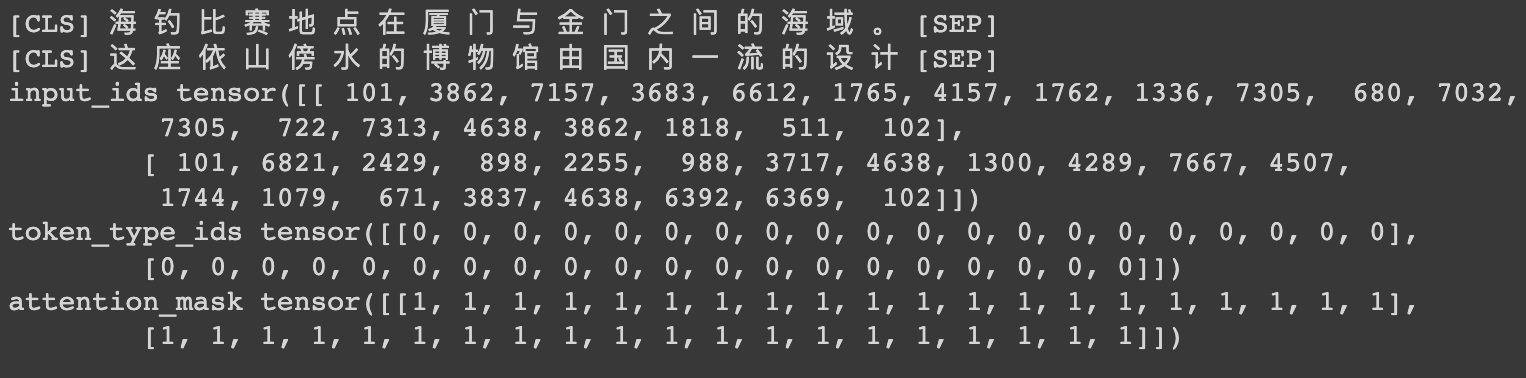 | 参数 | 描述 | | ------------ | ------------ | | `is_split_into_words` | 当为`True`时表示告诉编码器输入的句子是分好的词的,不需要进行分词工作了。 | | `max_length` | 为`20`时,表示长度最长为20,不足补`[PAD]`,超出会被截断。 | #### 定义数据集 tn2>数据集为`people_daily_ner`。 ```python #第10章/定义数据集 import torch from datasets import load_dataset, load_from_disk class Dataset(torch.utils.data.Dataset): def __init__(self, split): #在线加载数据集 dataset = load_dataset(path='peoples_daily_ner', split=split) #离线加载数据集 #dataset = load_from_disk( # dataset_path='./data/peoples_daily_ner')[split] self.dataset = dataset #dataset.features['ner_tags'].feature.num_classes #7 #dataset.features['ner_tags'].feature.names #['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC'] def __len__(self): return len(self.dataset) def __getitem__(self, i): tokens = self.dataset[i]['tokens'] labels = self.dataset[i]['ner_tags'] return tokens, labels dataset = Dataset('train') tokens, labels = dataset[0] print(tokens), print(labels) len(dataset) ``` tn2>这里我使用的是在线加载,在`people_daily_ner`数据集中,每条数据包括两个字段,即`tokens`和`ner_tag`,分别代码句子和标签,在`__getitem__()`函数中的两个字段取出来并返回即可。 运行结果如下: 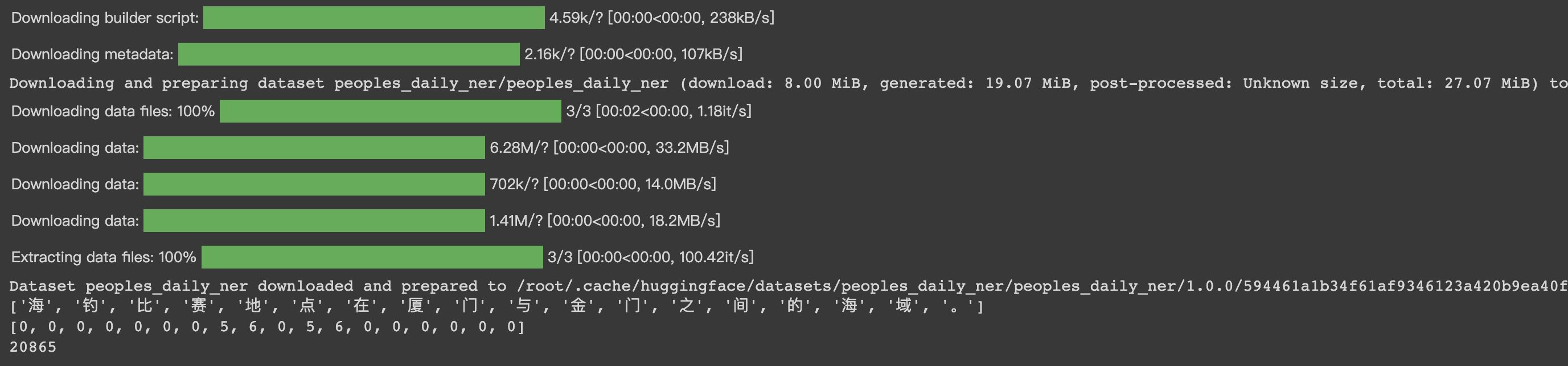 tn2>可见,训练数据集包括`20865`条数据,每条数据包括一条分好的词的文本和一个标签列表。 值得注意的是,此处的数据任然是文本数据,还没有被编码器编码。 #### 定义计算机设备 ```python device = 'cpu' if torch.cuda.is_available(): device = 'cuda' device ```  #### 定义数据整理函数 tn2>做一个数据整理的操作。 ```python #第10章/定义数据整理函数 def collate_fn(data): tokens = [i[0] for i in data] labels = [i[1] for i in data] #编码 inputs = tokenizer.batch_encode_plus(tokens, truncation=True, padding=True, return_tensors='pt', max_length=512, is_split_into_words=True) #求一批数据中最长的句子长度 lens = inputs['input_ids'].shape[1] #在labels的头尾补充7,把所有的labels补充成统一的长度 for i in range(len(labels)): labels[i] = [7] + labels[i] labels[i] += [7] * lens labels[i] = labels[i][:lens] #把编码结果移动到计算设备 for k, v in inputs.items(): inputs[k] = v.to(device) #把统一长度的labels组装成矩阵,并移动到计算设备 labels = torch.LongTensor(labels).to(device) return inputs, labels ``` tn2>使用`tokenizer`的工具对 tokens 进行编码。`tokenizer.batch_encode_plus` 函数将 `tokens` 编码成模型可以处理的格式,同时确保它们具有相同的长度。这个函数执行以下操作: `truncation=True`:截断文本以确保所有文本的长度不超过指定的最大长度。 `padding=True`:在文本的末尾添加填充标记,以确保它们的长度相等。 `return_tensors='pt'`:返回 PyTorch 张量。 `max_length=512`:限制文本长度不超过512个标记。 `is_split_into_words=True`:表示 tokens 已经分割成单词。 接下来进行试算一下: ```python #数据整理函数试算 #模拟一批数据 data = [ ([ '海', '钓', '比', '赛', '地', '点', '在', '厦', '门', '与', '金', '门', '之', '间', '的', '海', '域', '。' ], [0, 0, 0, 0, 0, 0, 0, 5, 6, 0, 5, 6, 0, 0, 0, 0, 0, 0]), ([ '这', '座', '依', '山', '傍', '水', '的', '博', '物', '馆', '由', '国', '内', '一', '流', '的', '设', '计', '师', '主', '持', '设', '计', ',', '整', '个', '建', '筑', '群', '精', '美', '而', '恢', '宏', '。' ], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ]), ] #试算 inputs, labels = collate_fn(data) for k, v in inputs.items(): print(k, v.shape) print('labels', labels.shape) ``` 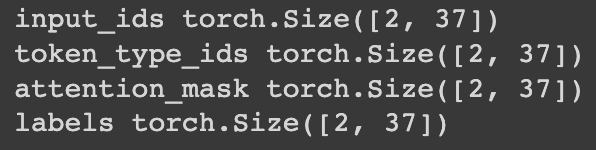 tn2>当前最长的句子有37个词。 #### 定义数据集加载器 ```python #数据加载器 loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=16, collate_fn=collate_fn, shuffle=True, drop_last=True) len(loader) ``` 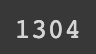 tn2>可见训练数据集一共执行了1340个批次。 定义好了数据集加载器之后,可以查看一批数据样本,代码如下: ```python #第10章/查看数据样例 for i, (inputs, labels) in enumerate(loader): break print(tokenizer.decode(inputs['input_ids'][0])) print(labels[0]) for k, v in inputs.items(): print(k, v.shape) ```  ### 定义模型 #### 加载预训练模型 tn2>使用`hfl/rbt3`作为预习训练模型,代码如下: ```python #加载预训练模型 from transformers import AutoModel pretrained = AutoModel.from_pretrained('hfl/rbt3') pretrained.to(device) #统计参数量 print(sum(i.numel() for i in pretrained.parameters()) / 10000) ```  tn2>定义好预训练模型之后,可以进行一次试算: ```python #第10章/模型试算 #[b, lens] -> [b, lens, 768] pretrained(**inputs).last_hidden_state.shape ```  tn2>样式数据为16句话的编码结果,从预训练模型的计算结果可以看出,这也是16句话的结果,每句话包括54个词,每个词被抽成了一个768维的向量。到此为止,通过预训练模型成功的把16句话转换成一个特征向量矩阵,可以接入下游任务模型做分类或回归任务。 #### 定义下游任务模型 tn2>本章将使用两段式训练,所以要求下游任务模型能够切换微调(Fine Tuning)模式。 tn>什么是两段式训练?两段式训练是一种训练计较,指先单独对下游任务模型进行一定的训练,待下游任务模型掌握了一定的知识以后,再连通预训练模型和下游模型一起进行训练的模式。 ```python #第10章/定义下游模型 class Model(torch.nn.Module): def __init__(self): super().__init__() #标识当前模型是否处于tuning模式 self.tuning = False #当处于tuning模式时backbone应该属于当前模型的一部分,否则该变量为空 self.pretrained = None #当前模型的神经网络层 self.rnn = torch.nn.GRU(input_size=768, hidden_size=768, batch_first=True) self.fc = torch.nn.Linear(in_features=768, out_features=8) def forward(self, inputs): #根据当前模型是否处于tuning模式而使用外部backbone或内部backbone计算 if self.tuning: out = self.pretrained(**inputs).last_hidden_state else: with torch.no_grad(): out = pretrained(**inputs).last_hidden_state #backbone抽取的特征输入rnn网络进一步抽取特征 out, _ = self.rnn(out) #rnn网络抽取的特征最后输入fc神经网络分类 out = self.fc(out).softmax(dim=2) return out #切换下游任务模型的的tuning模式 def fine_tuning(self, tuning): self.tuning = tuning #tuning模式时,训练backbone的参数 if tuning: for i in pretrained.parameters(): i.requires_grad = True pretrained.train() self.pretrained = pretrained #非tuning模式时,不训练backbone的参数 else: for i in pretrained.parameters(): i.requires_grad_(False) pretrained.eval() self.pretrained = None model = Model() model.to(device) model(inputs).shape ``` tn2>这段代码定义并初始化了下游任务模型,在下游任务模型的`__init_()`函数中有两个重要的变量,即`tuning`和`pretrained`,其中`tuning`为布尔型变量,取值为`True`和`False`,它表明了当前模型是否处于微调模型,默认值为`False`,即非微调模式。`pretrained`代表了预训练模型,当前处于微调模型时预训练模型应该属于当前模型的一部分,反之则不属于,默认为`None`,即预训练模型不属于当前模型的一部分。<br/> 在`__init__()`函数中还定义了下游任务模型的两个网络层,即是循环神经网络层和全连接神经网络层,分别命名为`rnn`和`fc`,其中循环神经网络的实现为GRU网络。<br/> `forward()`函数定义了下游任务模型的计算过程,首先判断当前模型是否处于微调模式,如果处于微调模式的话使用内部的预训练模型,否则使用外部的预训练模型,并且不计算预训练模型的梯度。得到预训练模型抽取的文本特征后,把文本特征输入循环神经网络进一步抽取特征,最后把特征数据输入全连接神经网络分类即可。<br/> 为什么需要循环神经网络层?这是一个想当然的想法,因为标签列表也可以看作一句话,这句`话`也符合一定的统计规律,例如人名的中间部分(I-PER)一定出现在人名的开头(B-PER之后),所以把预训练模型抽取的文本特征也当作一个序列数据进行处理,输入循环神经网络再次抽取特征,最后做分类计算,期望可以得到更好的结果。读者也可以尝试移除,或者增加其他的层,来提高模型预测的正确率,深度学习任务中往往有很多这样的尝试性实验。 一般的PyTorch模型定义`__init__()`函数和`forward()`函数就可以了,但是在上面的模型中还定义了`fine_tuning()`的函数,这个函数就是要切换下游模型的微调模型,入参为一个布尔值,取值为`True`和`False`。如前所述,当切换到微调模式时,把预训练模型切换到训练模型。 反之,不处于微调模式时要冻结预训练模型的参数,不让它们随着训练更新,并且预训练模型不属于下游任务模型的一部分,要把训练模式切换为运行模式。 下游任务模型试算结果如下:  tn2>从结果可以看出,运算的结果为16句话,54个词,每个词为8分类结果。 ### 训练和测试 #### 两个工具函数 tn2>为了便于后续的训练和测试,需要定义两个工具函数,第一个函数的功能是对计算结果和labels变形,并且移除`PAD`,需要这个函数的原因是因为在一批数据中,往往会有很多的`PAD`,对这些`PAD`去计算它们的实体命名是没有什么意义的,显然它们不可能是任何命名实体,为了不让模型去研究这些`PAD`是什么东西,直接从计算结果中移除这些`PAD`,以防止模型做无用功。实现代码如下: ```python #第10章/对计算结果和label变形,并且移除pad def reshape_and_remove_pad(outs, labels, attention_mask): #变形,便于计算loss #[b, lens, 8] -> [b*lens, 8] outs = outs.reshape(-1, 8) #[b, lens] -> [b*lens] labels = labels.reshape(-1) #忽略对pad的计算结果 #[b, lens] -> [b*lens - pad] select = attention_mask.reshape(-1) == 1 outs = outs[select] labels = labels[select] return outs, labels reshape_and_remove_pad(torch.randn(2, 3, 8), torch.ones(2, 3), torch.ones(2, 3)) ``` tn2>这段的代码中,首先把模型的预测结果和labels都从多句话合并成一句话,合并的方式就是简单地进行头尾相接,这样能够方便后续计算loss。 移除`PAD`时使用编码结果中的`attention_mask`,`attention_mask`标记了一个句子中哪些的位置是`PAD`,`attention_mask`中只有0和1,其中0标识是其中`PAD`的位置,使用`attention_mask`可以很轻松地过滤掉结果中的`PAD`. 在代码的最后使用一批虚拟的数据试算该函数,运行结果如下:  tn2>虚拟数据中的`2x3x8`矩阵表示2句话、3个词、每个词8分类的预测结果,第1个`2x3`矩阵表示真实的`labels`,第二个`2x3`的矩阵表示`attention_mask`,因为全为1,所以全部保留,没有`PAD`。 最后计算的结果也确实全部保留了预测结果和`labels`,并且预测结果和`labels`被变形成一句话,和预测一致。 第二个函数用于预测结果中测试正确了多少个,以及一共有多少个预测结果如下: ```python #第10章/获取正确数量和总数 def get_correct_and_total_count(labels, outs): #[b*lens, 8] -> [b*lens] outs = outs.argmax(dim=1) correct = (outs == labels).sum().item() total = len(labels) #计算除了0以外元素的正确率,因为0太多了,包括的话,正确率很容易虚高 select = labels != 0 outs = outs[select] labels = labels[select] correct_content = (outs == labels).sum().item() total_content = len(labels) return correct, total, correct_content, total_content get_correct_and_total_count(torch.ones(16), torch.randn(16, 8)) ```  tn2>因为虚拟的labels全是1,并没有出现标签0的情况,所以统计得出的两套正确数量和总数相等。 #### 训练 ```python #第10章/训练 from transformers import AdamW from transformers.optimization import get_scheduler def train(epochs): lr = 2e-5 if model.tuning else 5e-4 optimizer = AdamW(model.parameters(), lr=lr) criterion = torch.nn.CrossEntropyLoss() scheduler = get_scheduler(name='linear', num_warmup_steps=0, num_training_steps=len(loader) * epochs, optimizer=optimizer) model.train() for epoch in range(epochs): for step, (inputs, labels) in enumerate(loader): #模型计算 #[b, lens] -> [b, lens, 8] outs = model(inputs) #对outs和label变形,并且移除pad #outs -> [b, lens, 8] -> [c, 8] #labels -> [b, lens] -> [c] outs, labels = reshape_and_remove_pad(outs, labels, inputs['attention_mask']) #梯度下降 loss = criterion(outs, labels) loss.backward() optimizer.step() scheduler.step() optimizer.zero_grad() if step % (len(loader) * epochs // 30) == 0: counts = get_correct_and_total_count(labels, outs) accuracy = counts[0] / counts[1] accuracy_content = counts[2] / counts[3] lr = optimizer.state_dict()['param_groups'][0]['lr'] print(epoch, step, loss.item(), lr, accuracy, accuracy_content) torch.save(model, 'model/中文命名实体识别.model') ``` tn2>训练函数接受一个参数`epochs`,表示要使用全量数据训练几个轮次,由于是两段式训练,所以得出来的训练轮次可能不一样。所以需要这个参数。 由于采用了两段式训练,所以会根据模型是否处于微调模式选择不同的Learning Rate,在非微调模式时选择较大的Learning Rate,以快速训练下游任务模型在微调模式时则选择较小的Learning Rate,以精细地调节模型参数,帮助模型优化到更优的性能。 之后定义了优化器、loss计算函数、学习率调节器。 需要注意的是,优化器优化的参数表为下游任务模型的所有参数,因为下游任务模型在微调模式的问题,在非微调模式下,预训练模型并不属于下游任务模型的一部分,所以优化器的参数数量比较少,仅包含下游任务模型本身的参数。而在微调模式下,预训练模型属于下游任务模型的一部分,所以优化器优化的参数表也会包括预训练模型,这也是为什么要在切换微调模式时,设置下游任务模型的pretrained属性的原因。 接下来把下游任务模型切换到训练模式,并且在全量训练数据上遍历epochs个轮次,对模型进行训练。训练过程如下所述: (1)从训练集加载器中获取一个批次的数据。 (2)让模型计算预测结果 (3)使用工具函数对预测结果和labels进行变形,移除预测结果和labels中的PAD。 (4)计算loss并执行梯度下降优化模型。 (5)每隔一定的steps,输出一次模型当前的各项数据,便于观察 (6)每训练完一个epoch,将模型的参数大家保存到磁盘。 #### 两段式训练 ```python #两段式训练第1步,训练下游任务模型 model.fine_tuning(False) print(sum(p.numel() for p in model.parameters()) / 10000) train(1) ``` tn2>在这段代码中,首先把下游任务模型切换到非微调模式,之后输出了模型的参数量,由于干预训练模型并不属于下游任务模型的一部分,所以此处期待的参数量应该稍小,最后在全量数据上训练1个轮次,运行结果如下: 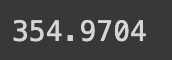 tn2>可以看到在非微调模式下,下游任务模型的参数量为354万。 训练过程的输出表如下:  tn2>从该表可以看出,随着训练步骤的增多,loss收敛得很快,并且正确率已经很高,即达到了`85%`,但排除`labels`中的0之后,正确率却只有`25%`,可见正确率是虚高的。 接下来可以进行两段式训练的第二个阶段,代码如下: ```python #第10章/两段式训练第2步,同时训练下游任务模型和预训练模型 model.fine_tuning(True) print(sum(p.numel() for p in model.parameters()) / 10000) train(5) ``` tn2>这段代码,把下游任务模式切换到微调模式,这意味着预训练模型将被一起训练。代码中输出了当前下游模型的参数量,由于预训练模型已经属于下游任务模型的一部分,因此此处的参数量期望会比较大,最后在全量数据上执行5个轮次的训练,运行结果如下: 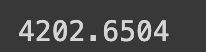 tn2>可见切换到微调模式后,下游任务模型的的参数量增加到`4200`万个,由于采用了较小的的预训练模式,所以这个参数量的规模依然较小,即使在一颗CPU上训练这个任务,时间也应该在可接受的范围内。训练过程的输出见表:  tn2>可以看出训练总体的正确率上升了不少,排除标签0之后的正确率也上升了。 #### 测试 tn2>最后,对训练好的模型进行训练,以验证训练的有效性,代码如下: ```python #第10章/测试 def test(): #加载训练完的模型 model_load = torch.load('中文命名实体识别.model') model_load.tuning = True model_load.eval() model_load.to(device) #测试数据集加载器 loader_test = torch.utils.data.DataLoader(dataset=Dataset('validation'), batch_size=128, collate_fn=collate_fn, shuffle=True, drop_last=True) correct = 0 total = 0 correct_content = 0 total_content = 0 #遍历测试数据集 for step, (inputs, labels) in enumerate(loader_test): #测试5个批次即可,不全部全部遍历 if step == 5: break print(step) #计算 with torch.no_grad(): #[b, lens] -> [b, lens, 8] -> [b, lens] outs = model_load(inputs) #对outs和label变形,并且移除pad #outs -> [b, lens, 8] -> [c, 8] #labels -> [b, lens] -> [c] outs, labels = reshape_and_remove_pad(outs, labels, inputs['attention_mask']) #统计正确数量 counts = get_correct_and_total_count(labels, outs) correct += counts[0] total += counts[1] correct_content += counts[2] total_content += counts[3] print(correct / total, correct_content / total_content) test() ``` tn2>在这段的代码中,首先从磁盘加载了训练完毕的模型,然后把模型切换到运行模式,再把模型移动到定义好的计算设备上。 完成模型的加载之后,定义测试数据集和加载器,并取出5个批次的数据让模型进行预测,最后统计两个正确率并输出,两个正确率之间的区别是一个统计了标签0,另一个则没有,运行结果如下:  #### 预测 tn2>验证了模型的有效性之后,可以进行一些预测,以更直观地观察模型的预测结果,代码如下: ```python #预测 def predict(): #加载模型 model_load = torch.load('中文命名实体识别.model') model_load.tuning = True model_load.eval() model_load.to(device) #测试数据集加载器 loader_test = torch.utils.data.DataLoader(dataset=Dataset('validation'), batch_size=32, collate_fn=collate_fn, shuffle=True, drop_last=True) #取一个批次的数据 for i, (inputs, labels) in enumerate(loader_test): break #计算 with torch.no_grad(): #[b, lens] -> [b, lens, 8] -> [b, lens] outs = model_load(inputs).argmax(dim=2) for i in range(32): #移除pad select = inputs['attention_mask'][i] == 1 input_id = inputs['input_ids'][i, select] out = outs[i, select] label = labels[i, select] #输出原句子 print(tokenizer.decode(input_id).replace(' ', '')) #输出tag for tag in [label, out]: s = '' for j in range(len(tag)): if tag[j] == 0: s += '·' continue s += tokenizer.decode(input_id[j]) s += str(tag[j].item()) print(s) print('==========================') predict() ``` tn2>这段代码中执行了以下工作: (1)加载了训练完毕的模型,并切换到运行模式,再移动到定义好的计算设备上。 (2)定义了测试数据集加载器,然后从数据集加载器中取出了一批数据。 (3)对这批数据进行预测。 (4)对原句子进行一些处理,以便符合人类对阅读习惯。 (5)输出labels和预测结果,以观察两种的异同。