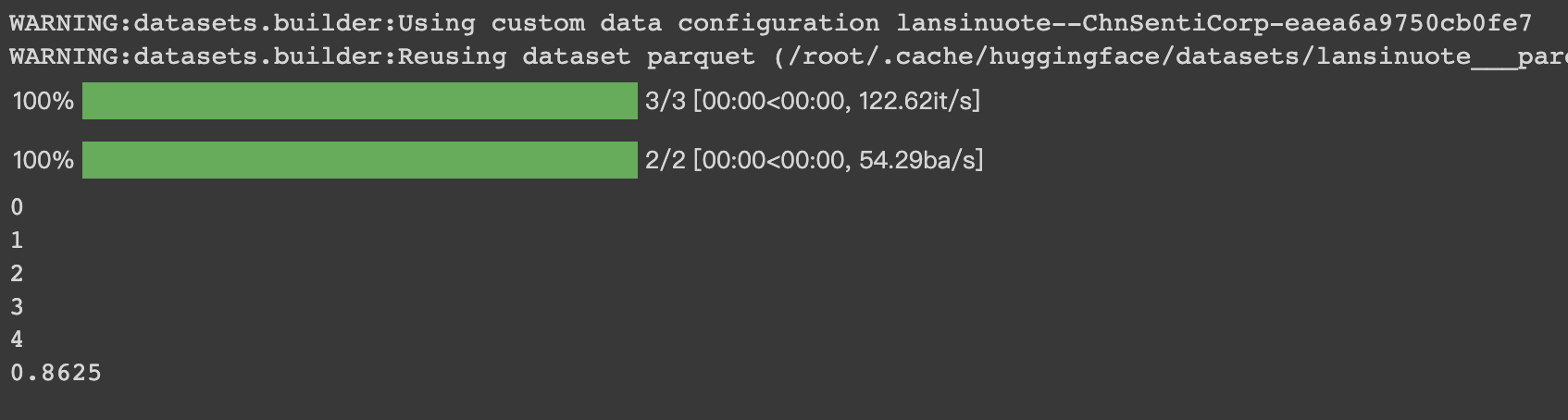
HugginFace 中文数据关系推断(学习笔记) 电脑版发表于:2023/10/30 15:56  >#HugginFace 中文数据关系推断(学习笔记) [TOC] ## 实现代码 ### 安装包 tn2>加载的环境可以通过如下命令进行安装。 ```python %pip install -q transformers==4.18 datasets==2.4.0 torchtext ``` ### 准备数据集 tn2>使用编码工具。 本章依然使用的是`bert-base-chinese`编码工具。 ```python from transformers import BertTokenizer token = BertTokenizer.from_pretrained('bert-base-chinese') token ```  tn2>进行试算一次,以更清晰的观察输入和输出,代码如下: ```python #试编码句子 out = token.batch_encode_plus( batch_text_or_text_pairs=[('不是一切大树,', '都被风暴折断。'), ('不是一切种子,', '都找不到生根的土壤。')], truncation=True, padding='max_length', max_length=18, return_tensors='pt', return_length=True, ) #查看编码输出 for k, v in out.items(): print(k, v.shape) #把编码还原为句子 print(token.decode(out['input_ids'][0])) ``` tn2>与情感分类和填空任务不同,这里编码的是句子对,运行结果如下:  tn2>确定编码的长度为`18`个词的长度。 ### 定义数据集 tn2>定义本次任务所需要的数据集仍然是`ChnSentiCorp`数据集。 ```python # 定义数据集 import torch from datasets import load_dataset import random class Dataset(torch.utils.data.Dataset): def __init__(self, split): dataset = load_dataset('lansinuote/ChnSentiCorp')[split] def f(data): return len(data['text']) > 40 self.dataset = dataset.filter(f) def __len__(self): return len(self.dataset) def __getitem__(self, i): text = self.dataset[i]['text'] #切分一句话为前半句和后半句 sentence1 = text[:20] sentence2 = text[20:40] #随机整数,取值范围为0和1 label = random.randint(0, 1) #有一半的概率把后半句替换为一句无关的话 if label == 1: j = random.randint(0, len(self.dataset) - 1) sentence2 = self.dataset[j]['text'][20:40] return sentence1, sentence2, label dataset = Dataset('train') sentence1, sentence2, label = dataset[7] len(dataset), sentence1, sentence2, label ``` tn2>在这段代码中,加载了`ChnSentiCorp`数据集,并使用PyTorch的Dataset对象进行封装,由于本次任务是要判断两句话是否存在相连的关系,如果假设定义每句话的长度为20个字,则原句子最短不能少于40个字,否则不能被切割成两句话。 所以在`__init__()`函数中加载了`ChnSentiCorp`数据集后对数据集进行过滤,丢弃了数字少于40个字的句子。 在`__getitem__()`函数中把原句切割成了各20个字的两句话,并且有一半的概率把后半句替换为无关的句子,这样就形成了本次任务中需要的数据结构,即每条数据中包括两句话,并且这两句话分别有`50%`的概率是相联和无关的关系。 运行结果如下: 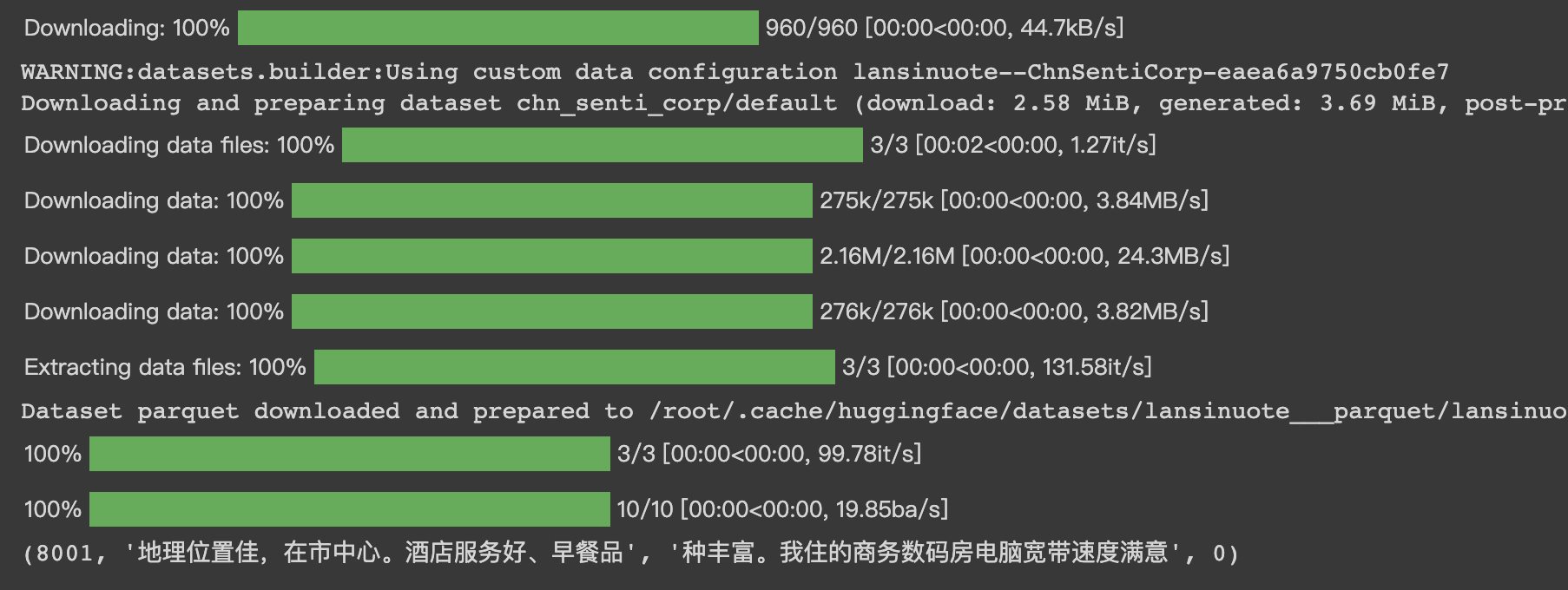 tn2>可见,训练数据集包括`8001`条数据,有两句话一个标识。 ### 定义计算设备 tn2>能不能支持gpu。 ```python import torch device = 'cpu' if torch.cuda.is_available(): device = 'cuda' device ```  ### 定义数据整理函数 tn2>定义一个数据整理函数,它具有批量编码一批文本数据的功能,代码如下: ```python #数据整理函数 def collate_fn(data): sents = [i[:2] for i in data] labels = [i[2] for i in data] #编码 data = token.batch_encode_plus(batch_text_or_text_pairs=sents, truncation=True, padding='max_length', max_length=45, return_tensors='pt', return_length=True, add_special_tokens=True) #input_ids:编码之后的数字 #attention_mask:是补零的位置是0,其他位置是1 #token_type_ids:第一个句子和特殊符号的位置是0,第二个句子的位置是1 input_ids = data['input_ids'].to(device) attention_mask = data['attention_mask'].to(device) token_type_ids = data['token_type_ids'].to(device) labels = torch.LongTensor(labels).to(device) return input_ids, attention_mask, token_type_ids, labels ``` tn2>在这段代码中,入参的data表示一批数据,取出其中的句子对和标识,分别为两个list,其中句子对的list中为一个一个tuple,每个tuple中包括两个句子,即一对句子。 在制作数据集时已经明确两个句子各有20个字,但在经历编码时每个字并不一定会被编码成一个词,此外在编码时还需要往句子中插入一些特殊福好,如标识句子开始的`[CLS]`标识一个句子的结束的`[SEP]`,所以编码的结果并不能确定为40个词,因此在编码时需要留下一定的容差,让编码结果中能囊括两个句子的所有信息,如果过有多余的位置,则可以以`[PAD]`填充。 综上所述,使用编码工具编码这一批句子对时,在参数中指定了编码后的结果为确定的45个词,超过45个词的句子将被截断,而不足45个词的句子将被补充`PAD`,直到45个词。 在编码时,通过参数`return_tensors='pt'`让编码结果为`PyTorch`的`Tensor`格式,这免去了后续转换数据格式的麻烦。 之后取出编码的结果,不妨假定一批数据,让数据整理函数进行试算,以观察数据整理的输入和输出,代码如下: ```python #数据整理函数试算 #模拟一批数据 data = [('酒店还是非常的不错,我预定的是套间,服务', '非常好,随叫随到,结帐非常快。', 0), ('外观很漂亮,性价比感觉还不错,功能简', '单,适合出差携带。蓝牙摄象头都有了。', 0), ('《穆斯林的葬礼》我已闻名很久,只是一直没', '怎能享受4星的服务,连空调都不能用的。', 1)] #试算 input_ids, attention_mask, token_type_ids, labels = collate_fn(data) #把编码还原为句子 print(token.decode(input_ids[0])) input_ids.shape, attention_mask.shape, token_type_ids.shape, labels ```  tn2>编码之后的结果都是确定的45个词 ### 定义数据集加载器 ```python #数据加载器 loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=8, collate_fn=collate_fn, shuffle=True, drop_last=True) len(loader) ```  tn2>可见,训练数据集加载器一共有1000个批次。 定义好了数据加载器之后,可以查看一批数据样本,代码如下: ```python #查看数据样例 for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader): break input_ids.shape, attention_mask.shape, token_type_ids.shape, labels ```  tn2>这个结果其实就是数据整理函数的计算结果,只是句子的数量更多。 ## 定义模型 ### 加载预训练模型 ```python #加载预训练模型 from transformers import BertModel pretrained = BertModel.from_pretrained('bert-base-chinese') #统计参数量 sum(i.numel() for i in pretrained.parameters()) / 10000 ``` tn2>在代码的最后,输出了模型的参数量,运行结果如下:  tn2>可见`bert-base-chinese`的参数量约为1亿个,在本次任务中选择不训练它,代码如下: ```python #不训练预训练模型,不需要计算梯度 for param in pretrained.parameters(): param.requires_grad_(False) ``` tn2>运行结果如下:  tn2>样例数据为8句话的编码结果,从预训练模型的计算结果可以看出,这也是8句话的结果,每句话包括45个词,每个词被抽成了一个768维的向量。到此为止,通过预训练模型成功地把8句话转换为一个特征向量矩阵,可以接入下游任务模型做分类或者回归任务。 ### 定义下游任务模型 tn2>完成以上工作后,现在可以定义下游任务模型了,对于本章的任务来讲,需要计算一个二分类的结果,并且需要和数据集中真实的label保持一致,代码如下: ```python #定义下游任务模型 class Model(torch.nn.Module): def __init__(self): super().__init__() self.fc = torch.nn.Linear(768, 2) def forward(self, input_ids, attention_mask, token_type_ids): #使用预训练模型抽取数据特征 with torch.no_grad(): out = pretrained(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) #对抽取的特征只取第一个字的结果做分类即可 out = self.fc(out.last_hidden_state[:, 0]) out = out.softmax(dim=1) return out model = Model() #设定计算设备 model.to(device) #试算 model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids).shape ``` tn2>在这段代码中,定义了下游任务模型,该模型只包括一个全连接的线性神经网络,权重矩阵为768x2,所以它能够把一个768维度的向量转换到二维空间中。 下游任务模型丢弃了44个词的特征,只取得了第1个词(索引为0)的特征向量,对应了编码结果中的`[CLS]`,把特征向量矩阵变成了`16x768`。相当于把每句话变成了一个`768`维度的向量。 tn>之所以只取了第1个词的特征做后续的判断计算,这和预训练模型BERT的训练方法有关系。 tn2>之后再使用自己的全连接线性神经网络把`16x768`特征矩阵转换到`16x2`,即为要求的二分类结果。  tn2>可见,这就是要求的16句话的二分类的结果。 ## 训练和测试 ### 训练 ```python #第9章/训练 from transformers import AdamW from transformers.optimization import get_scheduler def train(): #定义优化器 optimizer = AdamW(model.parameters(), lr=5e-5) #定义loss函数 criterion = torch.nn.CrossEntropyLoss() #定义学习率调节器 scheduler = get_scheduler(name='linear', num_warmup_steps=0, num_training_steps=len(loader), optimizer=optimizer) #模型切换到训练模式 model.train() #按批次遍历训练集中的数据 for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader): #模型计算 out = model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) #计算loss并使用梯度下降法优化模型参数 loss = criterion(out, labels) loss.backward() optimizer.step() scheduler.step() optimizer.zero_grad() #输出各项数据的情况,便于观察 if i % 20 == 0: out = out.argmax(dim=1) accuracy = (out == labels).sum().item() / len(labels) lr = optimizer.state_dict()['param_groups'][0]['lr'] print(i, loss.item(), lr, accuracy) train() ``` tn2>在这段代码中,首先定义了优化器、loss计算函数、学习率调节器。 训练完成后见下图所示: 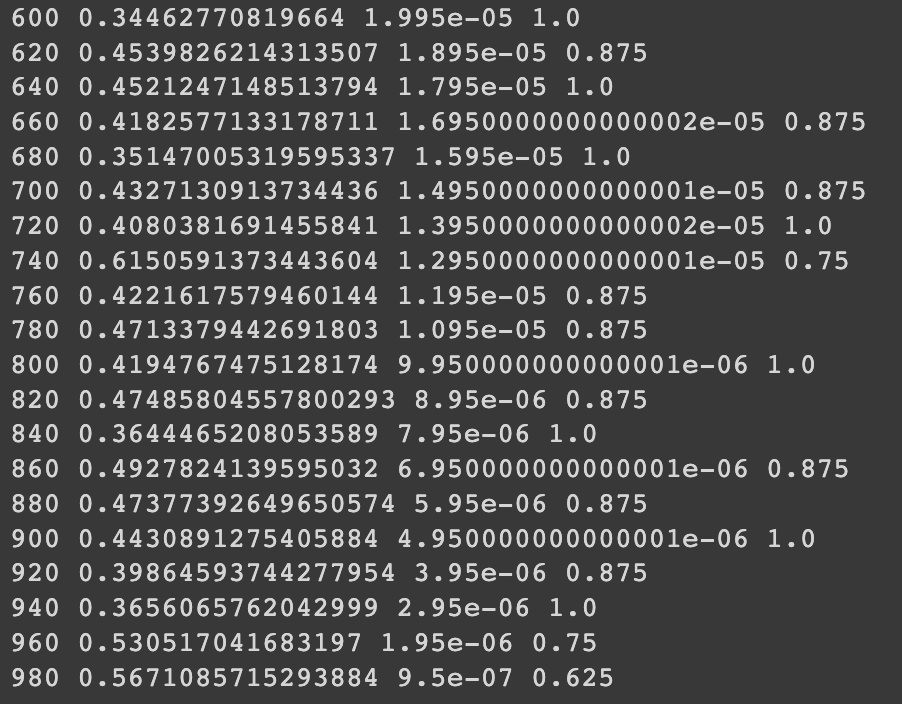 tn2>由于只是简单的一层全连接神经网络,所以训练的难度很低。 学习率在慢慢下降。 ### 测试 tn2>最后,对训练好的模型进行测试,以验证训练的有效性,代码如下图所示: ```python #第9章/测试 def test(): #定义测试数据集加载器 loader_test = torch.utils.data.DataLoader(dataset=Dataset('test'), batch_size=32, collate_fn=collate_fn, shuffle=True, drop_last=True) #下游任务模型切换到运行模式 model.eval() correct = 0 total = 0 #按批次遍历测试集中的数据 for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader_test): #计算5个批次即可,不需要全部遍历 if i == 5: break print(i) #计算 with torch.no_grad(): out = model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) pred = out.argmax(dim=1) #统计正确率 correct += (pred == labels).sum().item() total += len(labels) print(correct / total) test() ``` tn2>定义了测试数据集和加载器,并取出5个批次的数据让模型进行预测,最后统计正确率并输出,运行结果如下: