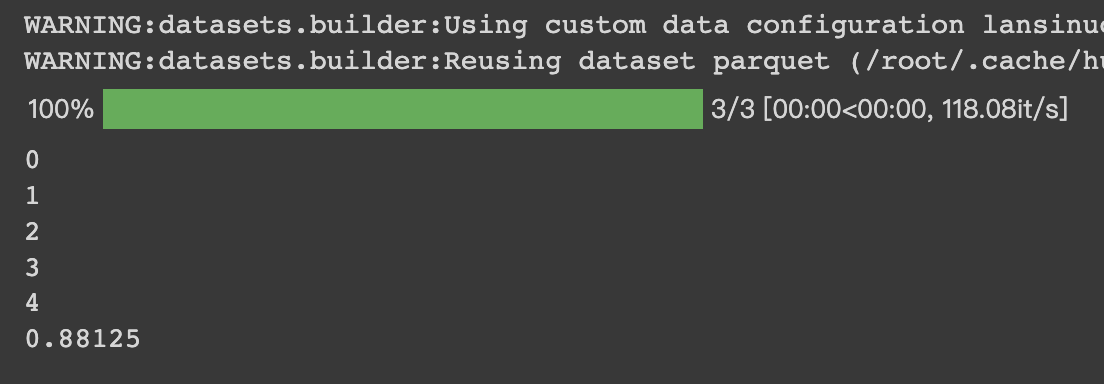
HugginFace 中文情感分类(学习笔记) 电脑版发表于:2023/10/27 17:22  >#HugginFace 中文情感分类(学习笔记) [TOC] ## 数据集介绍 tn2>本章使用的是`lansinuote/ChnSentiCorp`数据集,这是一个情感分类数据集,每条数据中包括一句购物评价和标识(好评或差评)。 ## 模型架构 tn2>RNN的主要功能是能把自然语言的句子抽取成特征向量,有了特征向量之后入全连接神经网络做分类或者回归就水到渠成了。 RNN把一个自然语言处理的任务换成了全连接神经网络任务。 对于类似RNN能把抽象数据类型转换成具体的特征向量的网络层,被统称为backbone,中文一般译为特征抽取层。 本章的情感分类任务中也将使用BERT中文模型作为backbone层。 相对于backbone的网络,后续的处理神经网络被称为下游任务模型,它往往会对backbone输出的特征向量进行再计算,得到业务上需要的计算结果,这往往是分类或者回归的结果。整合backbone和下游任务模型的架构如下图所示。 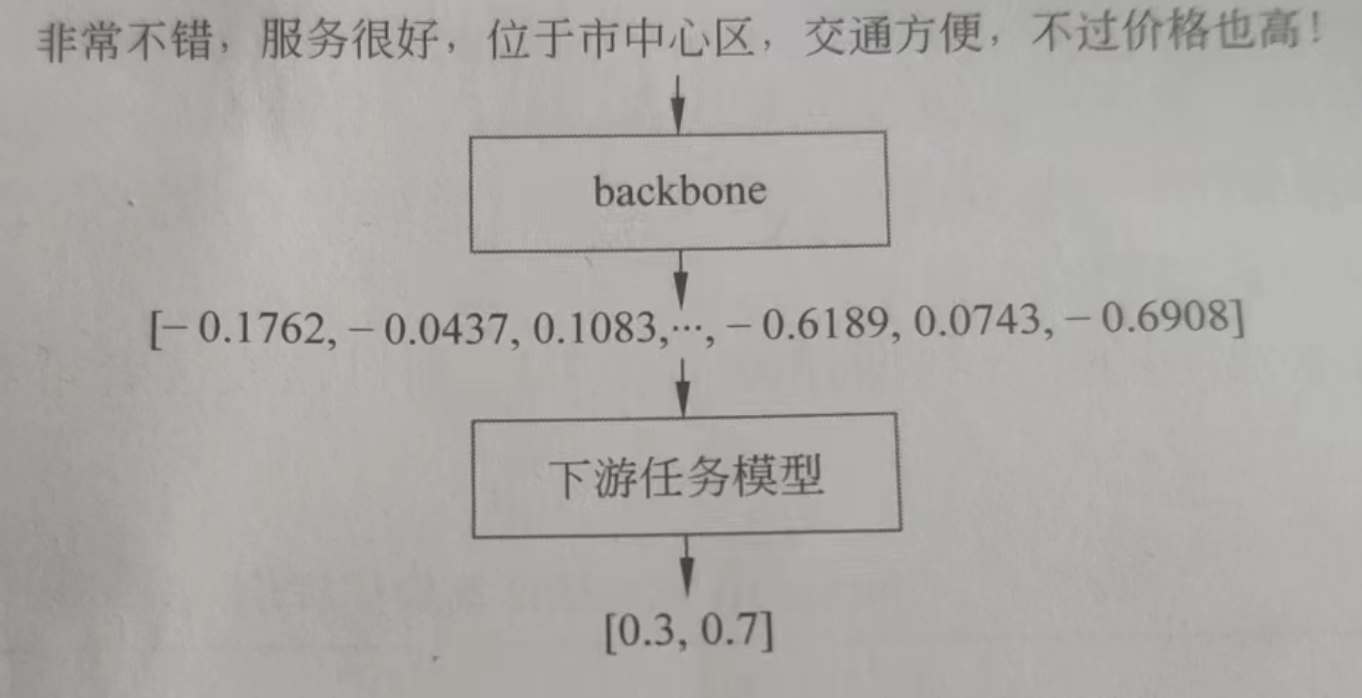 tn2>网络的计算过程先把一句自然语言输入backbone网络中进行特征抽取,特征是一个向量,再把特征向量输入下游任务模型中进行计算,得出最终业务需要的结果。 对于应用了预训练的backbone的网络,训练时可以选择继续训练backbone层,也可以不训练backbone层,因为backbone的参数量往往非常巨大。如果要对backbone进行再训练,则往往会消耗掉更多的计算资源;如果不对backbone进行再训练二模型的性能已经达到业务需求,也可以选择节省这些计算资源,接下来将进行演示。 ## 实现代码 ### 环境设置 ```python %pip install torch torchvision torchaudio -f https://download.pytorch.org/whl/cpu/torch_stable.html %pip install -q transformers==4.18 datasets==2.4.0 torchtext ``` ### 准备数据集 #### 使用编码工具 tn2>加载编码工具,把文字转数字。 ```python from transformers import BertTokenizer token = BertTokenizer.from_pretrained('bert-base-chinese') token ``` tn2>这里加载的编码工具为`bert-base-chinese`,编码工具和预训练模型往往是成对使用的,后续啊讲使用同名的预训练模型作为backbone,运行结果如下:  tn2>从输出可以看出,`bert-base-chinese`模型中的字典有`21128`个,编码器编码句子的最大长度为`512`个词,并且能看到`bert-base-chinese`模型所使用的一些特殊符号。 加载编码工具之后,不妨进行一次试算,以便更清晰地观察到编码工具的输入和输出,代码如下: ```python out = token.batch_encode_plus( batch_text_or_text_pairs=['从明天起,做一个幸福的人。', '喂马,劈柴,周游世界。'], truncation=True, padding='max_length', max_length=17, return_tensors='pt', return_length=True) #查看编码输出 for k, v in out.items(): print(k, v.shape) #把编码还原为句子 print(token.decode(out['input_ids'][0])) ```  tn2>从上面的代码中的参数`max_length=17`的说明可以看出,超过长度的会被夹断。 #### 定义数据集 tn2>我们将一个情感分类数据集进行模型的训练和测试,这里我们加载`lansinuote/ChnSentiCorp`数据集。 ```python import torch from datasets import load_dataset class Dataset(torch.utils.data.Dataset): def __init__(self,split): self.dataset = load_dataset('lansinuote/ChnSentiCorp')[split] def __len__(self): return len(self.dataset) def __getitem__(self, i): text = self.dataset[i]['text'] label = self.dataset[i]['label'] return text, label dataset = Dataset('train') len(dataset), dataset[20] ``` tn2>定义了一个`Dataset`类初始化时加载`lansinuote/ChnSentiCorp`的`train`训练数据集。 `__len__`获取长度。 `__getitem__`定义了每条数据,包括`text`和`label`两个字段,最后初始化训练数据集,并查看训练集的长度和一条数据采样。 结果如下: 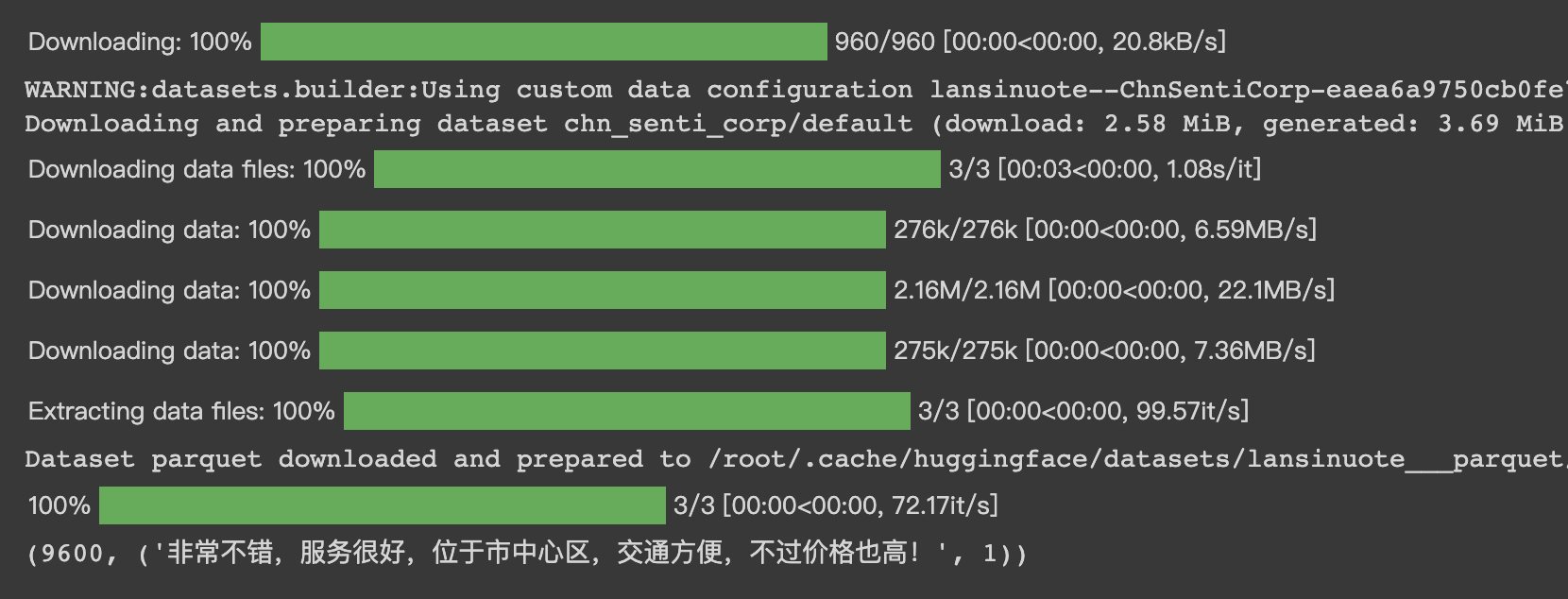 tn2>可见训练数据集包括`9600`条数据。 #### 定义数据整理函数 tn2>再CUDA计算平台上进行计算比在CPU上要快。 但不一定准,我们可以通过如下代码来确认系统是否支持GPU。 ```python device = 'cpu' if torch.cuda.is_available(): device = 'cuda' device ``` tn2>这里我使用的显卡是V100,所以输出的是`GUDA`。  #### 定义数据整理函数 tn2>接下来我们需要定义个数据整理函数,它具有批量编码一批文本数据的功能。 代码如下: ```python def collate_fn(data): sents = [i[0] for i in data] labels = [i[1] for i in data] #编码 data = token.batch_encode_plus(batch_text_or_text_pairs=sents, truncation=True, padding='max_length', max_length=500, return_tensors='pt', return_length=True) #input_ids:编码之后的数字 #attention_mask:是补零的位置是0,其他位置是1 input_ids = data['input_ids'] attention_mask = data['attention_mask'] token_type_ids = data['token_type_ids'] labels = torch.LongTensor(labels) #把数据移动到计算设备上 input_ids = input_ids.to(device) attention_mask = attention_mask.to(device) token_type_ids = token_type_ids.to(device) labels = labels.to(device) return input_ids, attention_mask, token_type_ids, labels ``` tn2>入参的data表示每一批数据,在参数中将编码后的结果指定为确定的500个词,超过500个词的句子将被截断,而不足500个词的句子将被补充PAD,直到500个词。 取出的编码也转换为`PyTorch`的`Tensor`格式。 接下来我们将模拟一组数据进行试算。 ```python #第7章/数据整理函数试算 #模拟一批数据 data = [ ('你站在桥上看风景', 1), ('看风景的人在楼上看你', 0), ('明月装饰了你的窗子', 1), ('你装饰了别人的梦', 0), ] #试算 input_ids, attention_mask, token_type_ids, labels = collate_fn(data) input_ids.shape, attention_mask.shape, token_type_ids.shape, labels ``` 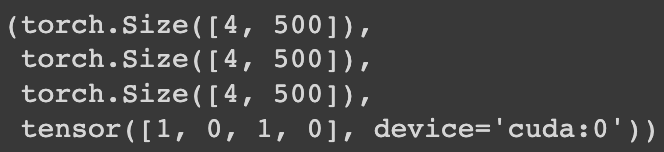 tn2>输出到结果4个句子每个500个词。 #### 定义数据集加载器 tn2>数据集加载器可以将数据整理函数来成批地处理数据集中的数据,代码如下: ```python loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=16, collate_fn=collate_fn, shuffle=True, drop_last=True) len(loader) ``` | 参数 | 描述 | | ------------ | ------------ | | `dataset=dataset` | 表示要加载的数据集。 | | `batch_size=16` | 表示每个批次中包括16条数据 | | `collate_fn=collate_fn` | 表示要使用的数据整理函数,这里使用了之前定义好的的数据整理函数。 | | `shuffle=True` | 表示打乱各个批次之间的顺序,让数据更加随机。 | | `drop_last=True` | 表示当剩余的数据不足16条时,丢弃这些尾数。 | tn2>运行的结果获取加载器一共有多少个批次,运行结果如下:  tn2>我们来进行一次数据样本的示例,代码如下: ```python for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader): break input_ids.shape, attention_mask.shape, token_type_ids.shape, labels ```  ### 定义模型 #### 加载预训练模型 tn2>完成以上准备工作,现在数据数据的机构已经准备好,可以输入模型进行计算了,即可加载预训练了,代码如下: ```python from transformers import BertModel pretrained = BertModel.from_pretrained('bert-base-chinese') #统计参数量 sum(i.numel() for i in pretrained.parameters()) / 10000 ``` tn2>此处加载的模型为`bert-base-chinese`模型,和编码工具的名字一致,注意模型和其编码工具往往配套使用。 模型的参数量,运行结果如下:  tn2>可见`bert-base-chinese`模型的参数量约为1亿个。 由于`bert-base-chinese`的体量比较大所以我们不需要对于本次的二分类任务进行训练。 代码如下: ```python # 不训练预训练模型,不需要计算梯度 for param in pretrained.parameters(): param.requires_grad_(False) ``` tn2>定义好预训练模型之后,可以进行一次试算,观察模型的输入和输出,代码如下: ```python #设定计算设备 pretrained.to(device) #模型试算 out = pretrained(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) out.last_hidden_state.shape ``` tn2>在这段代码中,首先把预训练模型移动到计算设备上,如果模型和数据不在同一个设备上,则无法计算。 之后把之前得到的样例数据输入预训练模型中,得到的计算结果为一个`BaseModelOutputWithPoolingAndCrossAttentions`对象,其中包括`last_hidden_state`和`pooler_output`两个字段,此处只关心`last_hidden_state`字段,取出该字段并输出其形状,运行结果如下:  tn2>16句话,每句话包括500个词,每个词被抽象成768维的向量。 接着我们接入下游任务模型做分类或者回归任务。 #### 定义下游任务类型 tn2>下游任务模型的任务是对`backbone`抽取的特征进行进一步计算,得到符合业务需求的计算结果。 代码如下: ```python #第7章/定义下游任务模型 class Model(torch.nn.Module): def __init__(self): super().__init__() self.fc = torch.nn.Linear(in_features=768, out_features=2) def forward(self, input_ids, attention_mask, token_type_ids): #使用预训练模型抽取数据特征 with torch.no_grad(): out = pretrained(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) #对抽取的特征只取第一个字的结果做分类即可 out = self.fc(out.last_hidden_state[:, 0]) out = out.softmax(dim=1) return out model = Model() #设定计算设备 model.to(device) #试算 model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids).shape ``` tn2>在这段代码中,定义了下游任务模型,该模型只包括一个全连接的神经网络,权重矩阵`768x2`,所以它能够把一个`768`维度的向量转换到二维空间中。 下游任务模型的计算过程为,获取了一批数据之后,使用`backbone`将这批数据抽取成特征矩阵,抽取的特征矩阵的形状应该是`16x500x768`,这在之前预训练模型的试算中已经看到。这三个维度分别代表了16句话、500个词、768维度的特征向量。 之后下游任务模型丢弃了499个词的特征,只取得第一个词(索引为0)的特征向量,对应编码结果中的`[CLS]`,把特征向量矩阵变成了`16x768`。相当于把每句话变成了一个`768`维度的向量。 tn>注意:之所以只取了第0个词的特征做后续的判断计算,这和预训练模型BERT的训练方法有关系. tn2>之后再使用自己的全连接线性神经网络把`16x768`特征矩阵转换到`16x2`,即为要求的分类结果。 运行结果如下:  tn2>这是16句话的二分类结果。 ### 训练预测 #### 训练 ```python from transformers import AdamW from transformers.optimization import get_scheduler def train(): #定义优化器 optimizer = AdamW(model.parameters(), lr=5e-4) #定义loss函数 criterion = torch.nn.CrossEntropyLoss() #定义学习率调节器 scheduler = get_scheduler(name='linear', num_warmup_steps=0, num_training_steps=len(loader), optimizer=optimizer) #模型切换到训练模式 model.train() #按批次遍历训练集中的数据 for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader): #模型计算 out = model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) #计算loss并使用梯度下降法优化模型参数 loss = criterion(out, labels) loss.backward() optimizer.step() scheduler.step() optimizer.zero_grad() #输出各项数据的情况,便于观察 if i % 10 == 0: out = out.argmax(dim=1) accuracy = (out == labels).sum().item() / len(labels) lr = optimizer.state_dict()['param_groups'][0]['lr'] print(i, loss.item(), lr, accuracy) train() ``` tn2>首先定于了优化器、loss计算函数、学习率调节器,其中优化器使用了HuggingFace提供的AdamW优化,这是传统的Adam优化器改进版本,在自然语言处理任务中,该优化器往往能取得比Adam优化器更好的成绩,并且计算效率更高。 学习率调节器也使用了HuggingFace提供的线性学习率调节器,它能在训练的过程中,让学习率缓慢地下降,而不是使用始终如一的学习率,因为在训练的后期阶段,需要更小的学习率来微调参数,这有利于loss 下降到更低的点。 由于本章的任务为分类任务,所以使用的loss计算函数为`CrossEntropyLoss`,即交叉熵计算函数。 之后把下游任务模型切换到训练模式,即可开始训练。训练的过程为不断地从数据集加载器中获取一批一批的数据,让模型进行计算,用模型计算的结果和真实的labels 计算 loss,根据 loss计算模型中所有参数的梯度,并执行梯度下降优化参数。 最后,每优化10次模型参数,就计算一次当前模型预测结果的正确率,并输出模型的 loss 和优化器的学习率,最终训练完毕后,输出的观察数据图表。 从图表可以看出,在训练到大约580个steps时,模型已经能够达到大约`87%`和`100%`的正确率,并且能够观察到loss是随着训练的进程在不断地下降,学习率也如预期的一样,也在缓慢地下降 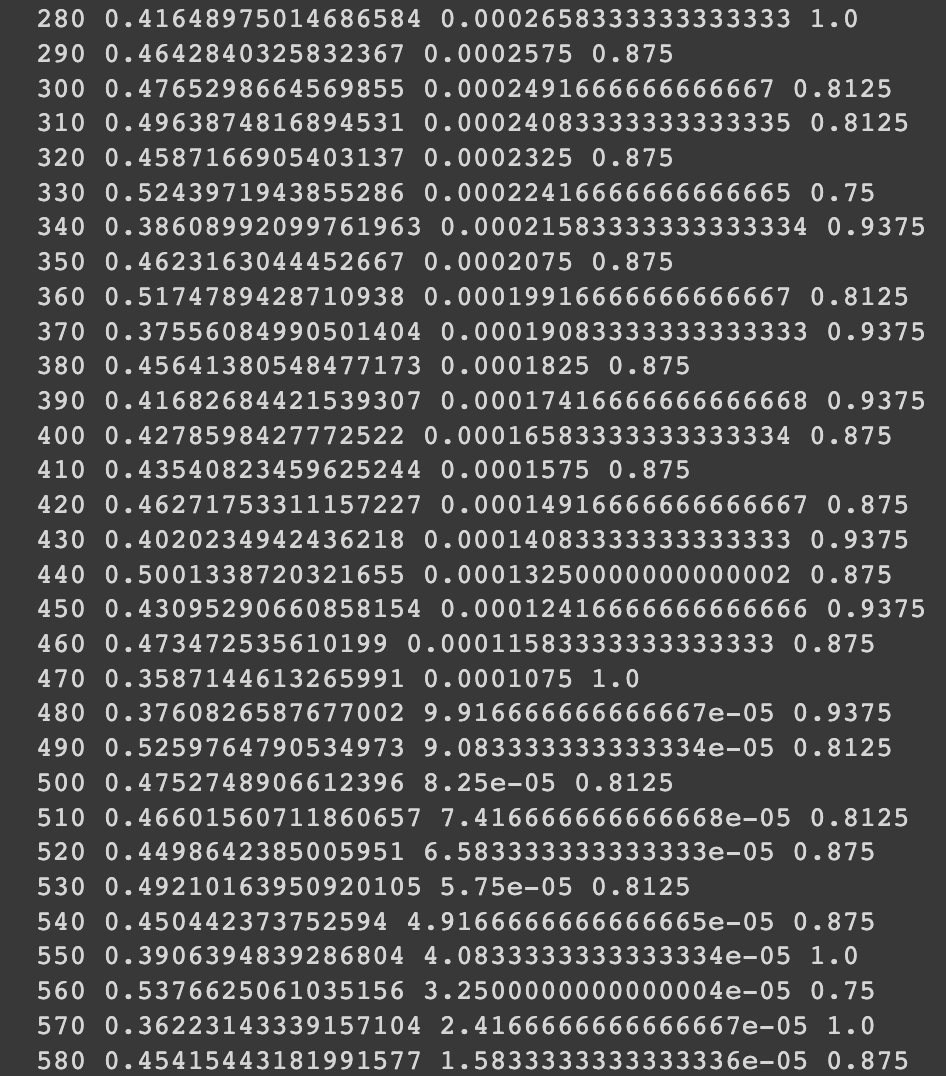 #### 测试 ```python def test(): #定义测试数据集加载器 loader_test = torch.utils.data.DataLoader(dataset=Dataset('test'), batch_size=32, collate_fn=collate_fn, shuffle=True, drop_last=True) #下游任务模型切换到运行模式 model.eval() correct = 0 total = 0 #按批次遍历测试集中的数据 for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader_test): #计算5个批次即可,不需要全部遍历 if i == 5: break print(i) #计算 with torch.no_grad(): out = model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) #统计正确率 out = out.argmax(dim=1) correct += (out == labels).sum().item() total += len(labels) print(correct / total) test() ``` tn2>首先定义了测试数据集和加载器,并取出5个批次的数据让模型进行预测,最后统计正确率并输出,如下图所示: