HugginFace 使用编码工具(学习笔记) 电脑版发表于:2023/10/20 14:58  >#HugginFace 使用编码工具(学习笔记) [TOC] ## 安装环境 ```python # 我这里的python是3.11 %pip install -q transformers==4.18 datasets==2.4.0 torchtext ``` ## 编码工具简介 tn2>HuggingFace提供了一套统一的编码API,由每个模型各自提交实现。 ## 编码工具流程示例 ### 1.定义字典 tn2>我们想让输入的文本,让电脑理解就是将其转换成数字的一个字典,这样可以方便电脑进行更好的计算。 举例: ```python vocab = { '<SOS>': 0, '<EOS>': 1, 'the': 2, 'quick': 3, 'brown': 4, 'fox': 5, 'jumps': 6, 'over': 7, 'a': 8, 'lazy': 9, 'dog': 10, } ``` ### 2.句子预处理 tn2>我们可以通过添加首尾标识把长的句子进行分词。 常用的是: `<SOS>`表示开始。 `<EOS>`表示结束。 ```python #添加首尾符号 sent = 'the quick brown fox jumps over a lazy dog' sent = '<SOS> ' + sent + ' <EOS>' print(sent) ``` tn2>运行结果如下:  ### 3.分词 tn2>这个句子是英文,可以直接通过空格进行分词。 由于中文的复杂性可以通过一些成熟的分词工具进行分词。 ```python #英文分词 words = sent.split() print(words) ``` tn2>运行结果如下:  ### 4.编码 tn2>当我们需要把这些单词映射成数字,就可以通过我们前面定义的字典来实现。 ```python #编码为数字 encode = [vocab[i] for i in words] print(encode) ``` tn2>运行结果如下:  tn2>以上就是一个编码的工作流程,经历了定义字典、句子预处理、分词、编码4个步骤。 ## 使用编码工具 tn2>接下来我们来看看Huggingface提供的编码工具。 ### 1.加载编码工具 tn2>首先我们添加的`bert-base-chinese`的编码工具。 ```python #第2章/加载编码工具 from transformers import BertTokenizer tokenizer = BertTokenizer.from_pretrained( pretrained_model_name_or_path='bert-base-chinese', cache_dir=None, force_download=False, ) tokenizer ``` | 参数 | 描述 | | ------------ | ------------ | | `pretrained_model_name_or_path` | 指定要加载的编码工具。这些工具可以从hangginface中找到。 | | `cache_dir` | 指定编码工具的缓存路径。默认值为None。 | | `force_download` | 当为True时表示已经有本地缓存都要强制执行下载工作。建议设置为False |  ### 2.准备实验数据 ```python #第2章/准备实验数据 sents = [ '你站在桥上看风景', '看风景的人在楼上看你', '明月装饰了你的窗子', '你装饰了别人的梦', ] ``` ### 3.基本的编码函数 tn2>首先通过`encode()`来进行基本的编码函数,一次编码将对应一个或者一对句子,在这个例子中,编码了一对句子。 不是每个编码工具都有编码一对句子的功能,具体取决于不同模型的实现。 ```python #第2章/基本的编码函数 out = tokenizer.encode( text=sents[0], text_pair=sents[1], #当句子长度大于max_length时截断 truncation=True, #一律补pad到max_length长度 padding='max_length', add_special_tokens=True, max_length=25, return_tensors=None, ) print(out) print(tokenizer.decode(out)) ``` | 参数 | 描述 | | ------------ | ------------ | | `text`与`text_pair` | `text`与`text_pair`分别为两个句子,如果只想编码一个句子,则可让`text_pair`传None | | `truncation` | 当为`True`时表示句子长度大于`max_length`时,截断句子。 | | `padding` | 当值为`max_length`时,表示当句子不足为`max_length`时通过PAD进行填充到max_length的最大长度。 | | `add_special_tokens` | 当为`True`,表示需要在句子中添加特殊符号 | | `max_length` | 定义句子的长度 | | `return_tensors` | 当为None时,返回的list的格式。除此之外还支持pytorch,numpy,tensorflow。 |  tn2>这里的`decode()`函数可以将list还原为分词前的句子,我们可以看到的句子的头部添加符号`[CLS]`,句子尾部添加符号`[SEP]`,由于长度不足`max_length`所以补充了4个`[PAD]`。 可以通过空格看出编码把每一个字作为一个词,所以在BERT的实现中,中文分词处理做的比较简单。 ### 4.进阶的编码函数 tn2>接下来展示一个稍微复杂的编码函数。 ```python #第2章/进阶的编码函数 out = tokenizer.encode_plus( text=sents[0], text_pair=sents[1], #当句子长度大于max_length时截断 truncation=True, #一律补零到max_length长度 padding='max_length', max_length=25, add_special_tokens=True, #可取值tf,pt,np,默认为返回list return_tensors=None, #返回token_type_ids return_token_type_ids=True, #返回attention_mask return_attention_mask=True, #返回special_tokens_mask 特殊符号标识 return_special_tokens_mask=True, #返回length 标识长度 return_length=True, ) #input_ids 编码后的词 #token_type_ids 第一个句子和特殊符号的位置是0,第二个句子的位置是1 #special_tokens_mask 特殊符号的位置是1,其他位置是0 #attention_mask pad的位置是0,其他位置是1 #length 返回句子长度 for k, v in out.items(): print(k, ':', v) tokenizer.decode(out['input_ids']) ``` tn2>这里调用了`encode_plus()`函数,进阶版的编码函数。 它多了几个编码结果,如果指定为False则不会返回对应的内容。  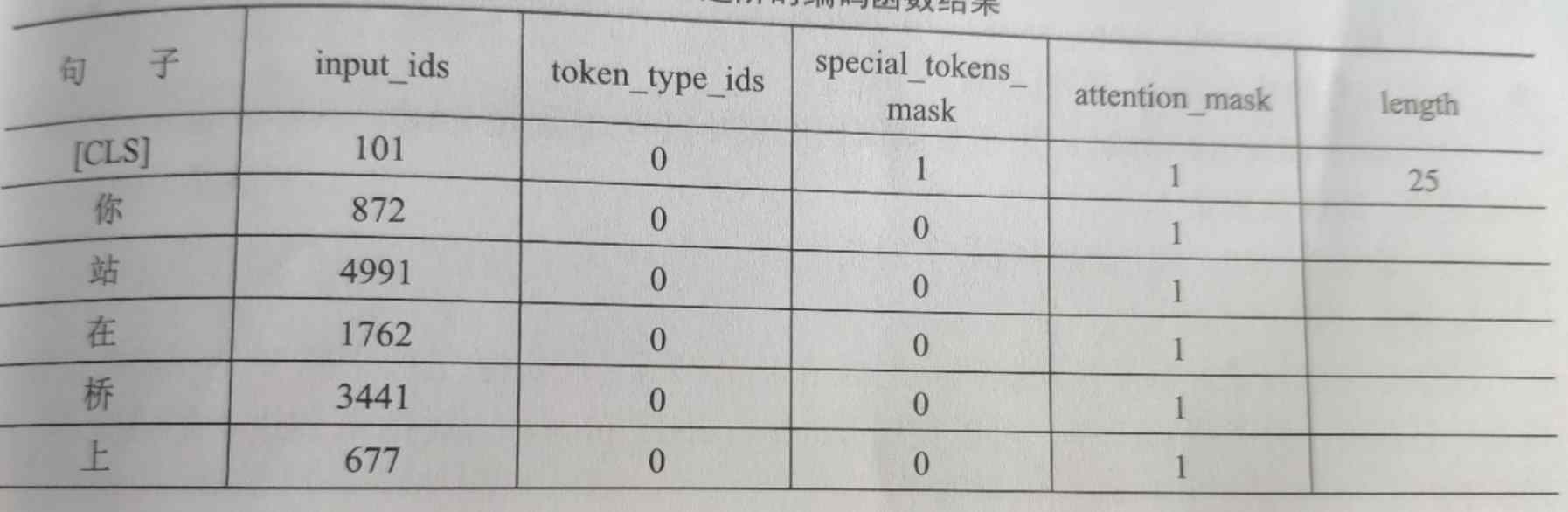 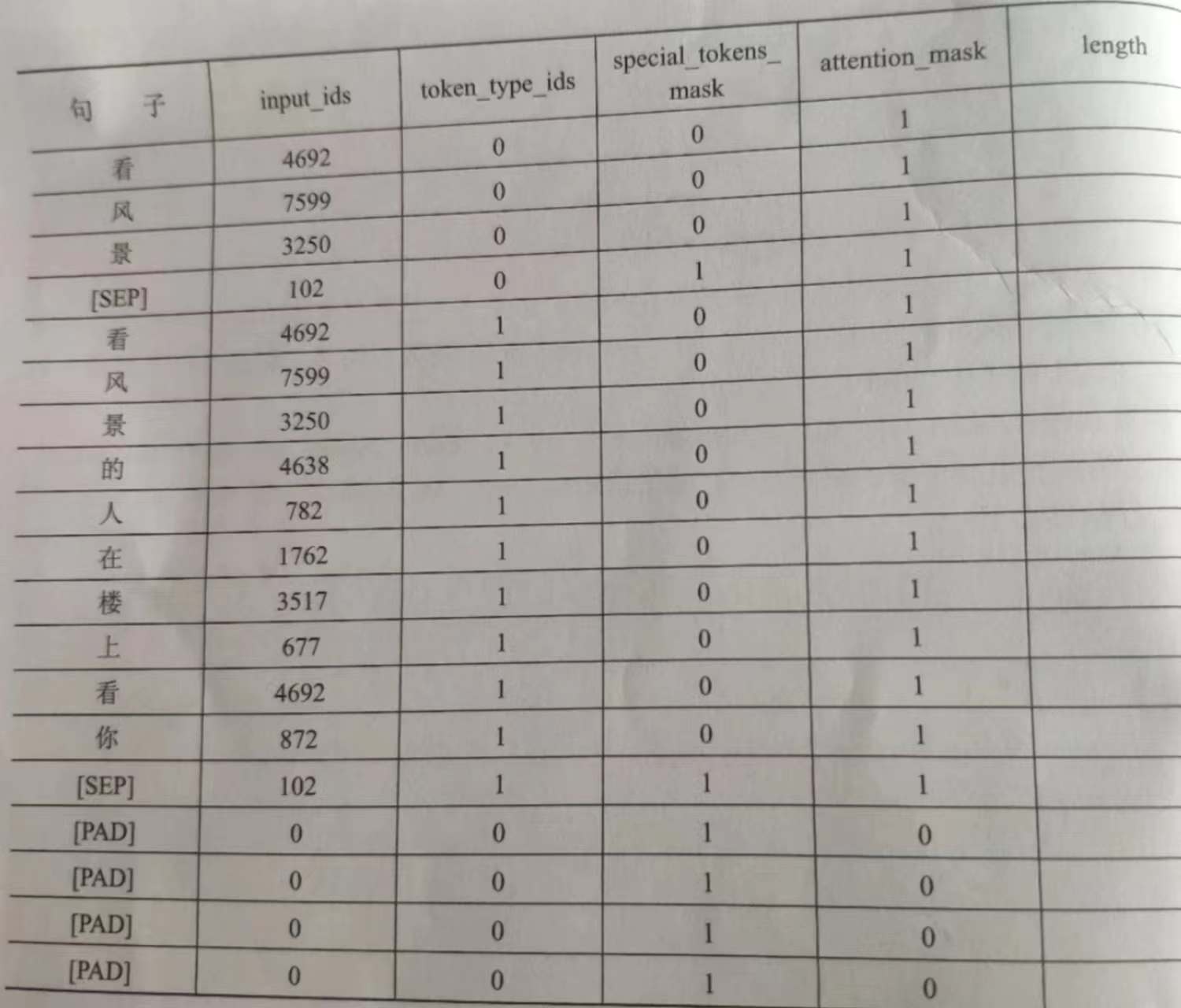 | 参数 | 描述 | | ------------ | ------------ | | `input_ids` | 编码后的词。 | | `token_type_ids` | 因为编码的是两个句子,这里表示第二个句子为1,其他位置都是0。 | | `special_tokens_mask` | 特殊符号的位置是1,其他位置是0 | | `attention_mask` | PAD的位置是0,其他位置是1 | | `length` | 表明编码后句子的长度。 | ### 5.批量的编码函数 tn2>我们可以通过的`batch_encode_plus()`函数批量的进行数据处理,代码如下: ```python #第2章/批量编码成对的句子 out = tokenizer.batch_encode_plus( #编码成对的句子 batch_text_or_text_pairs=[(sents[0], sents[1]), (sents[2], sents[3])], add_special_tokens=True, #当句子长度大于max_length时截断 truncation=True, #一律补零到max_length长度 padding='max_length', max_length=25, #可取值tf,pt,np,默认为返回list return_tensors=None, #返回token_type_ids return_token_type_ids=True, #返回attention_mask return_attention_mask=True, #返回special_tokens_mask 特殊符号标识 return_special_tokens_mask=True, #返回offset_mapping 标识每个词的起止位置,这个参数只能BertTokenizerFast使用 #return_offsets_mapping=True, #返回length 标识长度 return_length=True, ) #input_ids 编码后的词 #token_type_ids 第一个句子和特殊符号的位置是0,第二个句子的位置是1 #special_tokens_mask 特殊符号的位置是1,其他位置是0 #attention_mask pad的位置是0,其他位置是1 #length 返回句子长度 for k, v in out.items(): print(k, ':', v) tokenizer.decode(out['input_ids'][0]) ``` | 参数 | 描述 | | ------------ | ------------ | | `batch_text_or_text_pairs` | 用于编码一批句子,示例中为成对的句子,如果需要编码的是一个一个的句子,则修改为如下的形式即可 | ```python batch_text_or_text_pairs=[sents[0], sents[1]] ``` tn2>运行结果如下:  tn2>可以看到这里输出的都是二维的list,表明这是一个批量的编码。 ### 6.对字典操作 tn2>查看字典。 ```python #第2章/获取字典 vocab = tokenizer.get_vocab() type(vocab), len(vocab), '明月' in vocab ```  tn2>可以看到字典是dict类型,在BERT的字典中,共有21128个词,并且`明月`不存在字典中。 接下来我们将添加这个词 ```python #第2章/添加新词 tokenizer.add_tokens(new_tokens=['明月', '装饰', '窗子']) # 添加新符号 tokenizer.add_special_tokens({'eos_token': '[EOS]'}) vocab = tokenizer.get_vocab() type(vocab), len(vocab), vocab['明月'], vocab['[EOS]'] ```  tn2>接下来试试使用新词的字典编码句子,代码如下: ```python #第2章/编码新添加的词 out = tokenizer.encode( text='明月装饰了你的窗子[EOS]', text_pair=None, #当句子长度大于max_length时,截断 truncation=True, #一律补pad到max_length长度 padding='max_length', add_special_tokens=True, max_length=10, return_tensors=None, ) print(out) tokenizer.decode(out) ``` tn2>输出如下:  tn2>可以看到,`明月`已经被识别为一个词,而不是两个词,新的特殊符号`[EOS]`也被正确识别。

