HugginFace 初探 电脑版发表于:2023/10/11 17:44  >#HugginFace 初探 [TOC] ## 安装环境 tn2>python环境是`3.6`。 ```python import sys sys.version ```  tn2>安装torch,简单起见,避免环境问题,并且计算量不大,使用cpu运行本套代码。 后面章节会介绍使用cuda计算的方法。 ```python %pip install torch==1.10.1+cpu torchvision==0.11.2+cpu torchaudio==0.10.1 -f https://download.pytorch.org/whl/cpu/torch_stable.html ``` tn2>torch是一个进行深度学习使用的包,可以通过torch搭建深度学习模型,应用于图像分类、语音识别、文本分类等任务。 ```python import torch import torchvision import torchaudio torch.__version__, torchvision.__version__, torchaudio.__version__ ``` 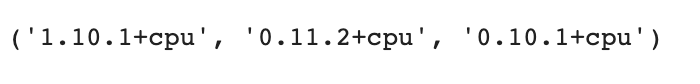 tn2>Transformers是由Hugging Face公司开发并维护,包含了最多NLP模型,同时也有CV等其他领域模型,支持预训练模型的快速使用和改进,并且模型可以快速在不同的深度学习框架间(Pytorch/Tensorflow/Jax)无缝转移。 通过pip安装transformers。 ```python %pip install transformers==4.18.0 ``` ```python import transformers transformers.__version__ ```  tn2>datasets包它通常用于在机器学习中加载和管理数据集,通过pip安装datasets。 ```python %pip install datasets==2.4.0 ``` tn2>TorchText是PyTorch的一个功能包,主要提供文本数据读取、创建迭代器的的功能与语料库、词向量的信息,分别对应了`torchtext.data`、`torchtext.datasets`和`torchtext.vocab`三个子模块。 ```python pip install torchtext==0.11.2 ``` ## NLP要解决的任务 tn2>——处理文本数据,首先对文本数据进行分词操作(分词的方法可能会不同,中文常见的就是分词或者分字) ——分完的词它不还是字符嘛,计算机还不认识,最终我们希望吧这些字符映射成实际的特征(向量) ——输入搞定好了之后,接下来我们要构建模型了(一般都用预训练模型,例如BERT、GPT系列等) ——怎么去完成我们自己的任务呢,基本上就是在预训练模型的基础上进行微调(训练我们自己数据的过程) (但很费电和gpu) ## HugginFace做了什么? tn2>Huggingface这个包就不是就是调用即可,开箱即用的过程。 ```python import warnings # 处理警告信息 warnings.filterwarnings("ignore") from transformers import pipeline # 用人家设计好的流程完成一些简单的任务 classifier = pipeline("seatiment-analysis")# 这是一个情感分类器 calssifier([ "I've been waiting for a HugginFace course my whole life.", "I hate this so much!" ]) ```  ## HugginFace基本流程 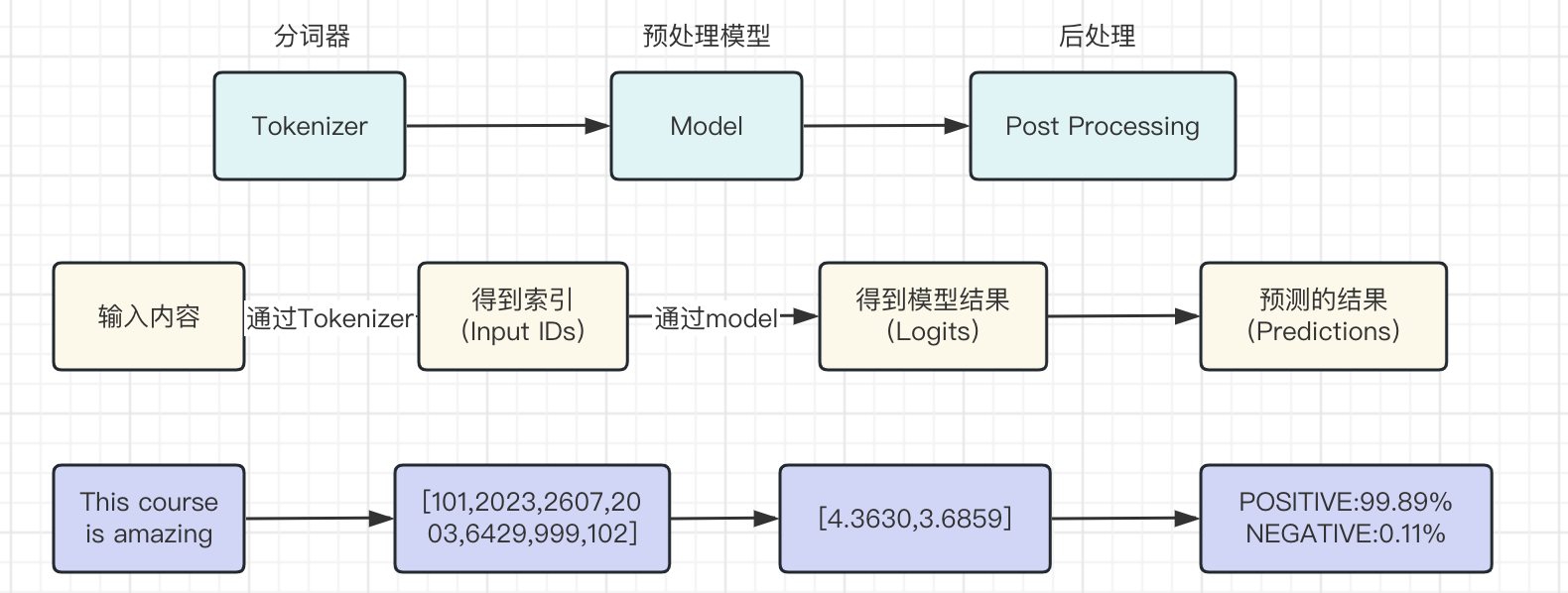 ## Tokenizer分词器要做的事 tn2>——分词,分字以及特殊字符(起始,终止,间隔,分类等特殊字符可以自己设计的) ——对每一个token映射得到一个ID(每个词都会对应一个唯一的ID) ——还有一些辅助信息也可以得到,比如当前词属于哪个句子(还有一些MASK,表示是否原来的词还是特殊字符) ```python from transforms import AutoTokenizer #自动判断 # 更具模型所对应的来加载:https://huggingface.co/search/full-text?q=seatiment-analysis checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"#\ tokenizer = AutoTokenizer.from_pretrained(checkpoint) ``` ```python raw_inputs = [ "I've been waiting for a this course my whole life", "I hate this so much!" ] inputs = tokenizer(raw_inputs, padding=True,truncation=True,return_tensors="pt") print(inputs) ``` | 参数 | 描述 | | ------------ | ------------ | | `padding` | 当为true时,我们会更具最长的话为一个词的长度,其他的语句不足该长度的为其中的语句填上0. | | `truncation` | 截断语句的长度为`512` | | `return_tensors` | 通过不同的值返回不同的张量。 | tn2>return_tensors 的值为以下几个时: `pt`:表示返回PyTorch张量(tensor)。如果你在PyTorch中进行深度学习任务,这是一个常见的选择,因为你可以将tokenizer的输出直接用于PyTorch模型的输入。 `tf`:表示返回TensorFlow张量(tensor)。如果你在TensorFlow中进行深度学习任务,这是一个常见的选择,因为你可以将tokenizer的输出直接用于TensorFlow模型的输入。 `np`:表示返回NumPy数组。这对于一些其他机器学习框架或一些数据处理任务可能更方便,因为NumPy是一个常用的数值计算库。 None:如果将return_tensors参数设置为None,则tokenizer将返回一个Python字典,其中包含各种输出,如input_ids、attention_mask等,而不是张量或数组。这是一种更灵活的选项,可以根据需要自行处理。  tn2>上面这幅图是输出的结果,我们直接来看第二排,如果按照字符串加上标点符号来看第二个句子有6个词。算上分割符号`101`与`102`就是八个,其他的按照0来补,后面的`attention_mask`添加的0表示不会进行带入计算。 下面进行反向测试。 ```python tokenizer.decode([101,1045,1005,2310,2042,3403,2005,1037,2023,2607,2026,2878,2166,1012,102]) ```  ## 模型的加载方法很简单 tn2>可以直接指定好名字即可,这里我们先不加输出层。 ```python from transformers import AutoModel checkpoint = "distilbert-base-uncased-finetuned-sst-2-english" tokenizer = AutoTokenizer.from_pretrained(checkpoint) model ``` 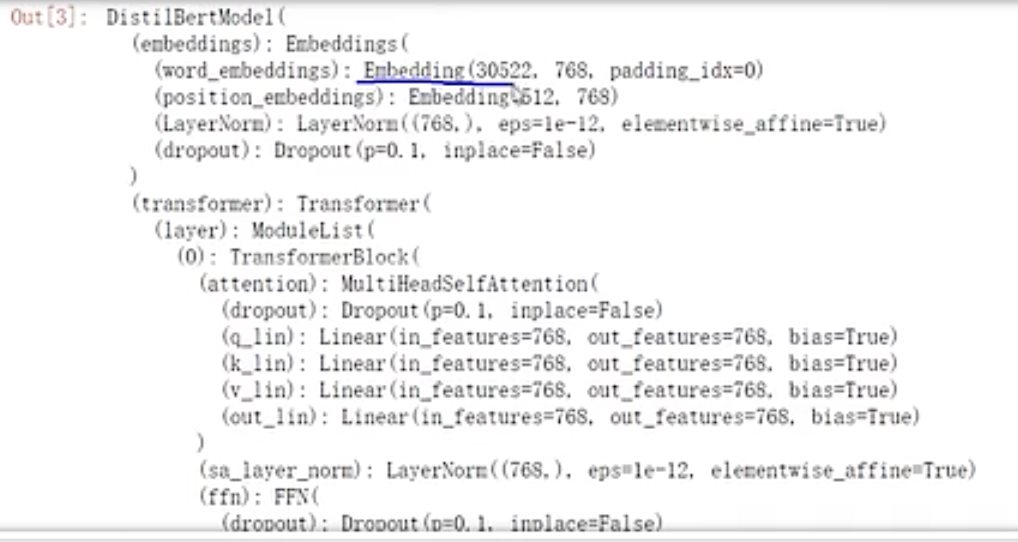 ```python outputs = model(**inputs) print(outputs,last_hidden_state,shape) ``` 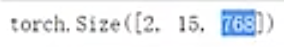 tn2>编码成768个向量。 ## 模型基本逻辑 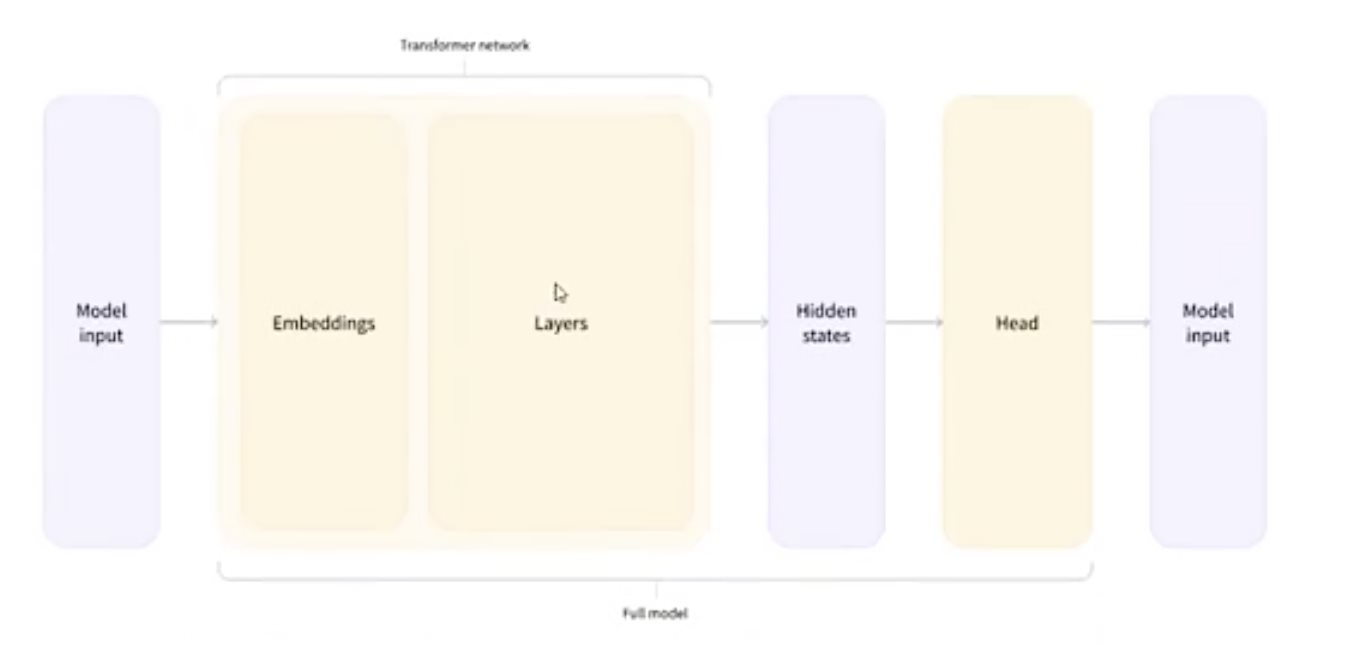 ## 加上输出头 ```python from transformers import AutoModelForSequenceClassification checkpoint = "distilbert-base-uncased-finetuned-sst-2-english" # from_pretrained 方法用于根据预训练模型的名称或标识符从Hugging Face模型库中加载模型权重。这个方法会根据提供的预训练模型名称自动选择正确的模型架构,并加载相应的权重 model = AutoModelForSequenceClassification.from_pretrained(checkpoint) outputs = model(**inputs) print(outputs.logits.shape) ``` ```python model ``` tn2>输出后我们可以看到  ```python import torch # 输出张量 predictions = torch.nn.functional.softmax(outputs.logins,dim=-1) print(predictions) ``` 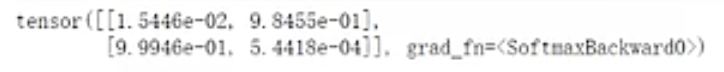 tn2>id2label这个我们后续可以自己设计,标签名字对应都可以自己指定。 ```python model.config.id2label ``` ## padding的作用 ```python sequence1_ids = [[200, 200, 200]] sequence2_ids = [[200, 200]] batched_ids = [ [200, 200, 200], [200, 200, tokenizer.pad_token_id] ] print(model(torch.tensor(sequence1_ids)).logits) print(model(torch.tensor(sequence2_ids)).logits) print(model(torch.tensor(batched_ids)).logits) ```  tn2>我们会发现`tokenizer.pad_token_id`与上面得出的结果还是不一样的。 但是需要补充的必须要加上。!!! ## attention_mask的作用 ```python batched_ids = [ [200, 200, 200], [200, 200, tokenizer.pad_token_id], ] attention_mask = [ [1, 1, 1], [1, 1, 0] ] outputs = model(torch.tensor(batched_ids), attention_mask=torch.tensor(attention_mask)) print(outputs.logits) ``` tn2>这需要与其配套使用。 ## 不同的padding方法 ```python sequences = ["I've been waiting for a this course my whole life.","So have I!","I played basketball yesterday."] # 按照最长的填充 model_inputs = tokenizer(sequences.padding="longest") model_inputs ```  ```python # 如果是max_length就是最大的 model_inputs = tokenizer(sequences.padding="max_length") # max_length表示句子中的词不足8的用0进行添加填充。 model_inputs = tokenizer(sequences.padding="max_length",max_length=8) # 词的长度到10就截断 model_inputs = tokenizer(sequences,max_length=8,truncation=True) ```

