Ollama 离线 Llama 2大语言模型的安装 电脑版发表于:2023/8/22 18:20  >#Ollama 离线 Llama 2大语言模型的安装 [TOC] Llama 2 ------------ tn2>Llama 2是由于Meta旗下开发的一款AI大语言模型,要把它跑起来是需要很多CPU、GPU等硬件资源。 Ollama简介 ------------ tn2>简单来说它相当于上面的缩减版。 它实现了本地运行Llama 2的实现方案,它通过一些模型文件Ollama打包、模型、权重、配置包,包括GPU的使用做了一定的优化。 另外LangChain也对其做了集成。<br/> 相关链接:https://ollama.ai/ https://github.com/jmorganca/ollama https://python.langchain.com/docs/integrations/llms/ollama Ollama下载 ------------ tn2>目前Ollama对于Mac可以进行直接安装,对于其他操作系统需要进行编译。 ### Mac安装 tn2>直接点击Ollama主页的安装下载安装包即可,然后进行解压,双击就完成应用到本地。  tn2>打开后我们点击next,再点击install进行Ollama命令行的安装。  tn2>然后我们需要选择我们的模型,这里我们就使用常规的模型进行安装就好了。 模型的规格如下:  tn2>打开我们的命令行执行如下命令。 ```bash # 下载模型 ollama run llama2 # 查看进程 ps -ef |grep ollama # 查看对外暴露的端口 lsof -i :11434 ``` 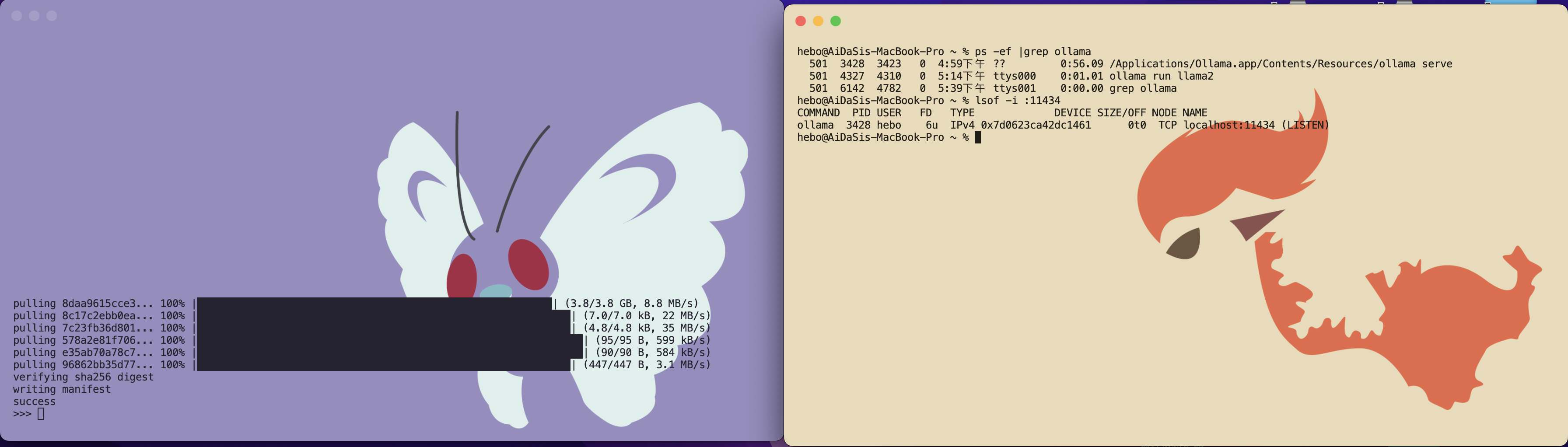 tn2>左边我们可以看到Ollama的模型已经下载完成了,右边我们可以看到它启动的进程以及ollama开放的`11434`端口。这样我们就算安装完成了。 ### Windows安装 tn2>拉下源代码码后执行如下脚本进行编译与安装。 ```bash go build . ./ollama serve & ./ollama run llama2 ``` tn2>这样就完成安装了。 断网测试 ------------ tn2>我们在不联网的情况下进行测试它能否回答我们的一些问题。 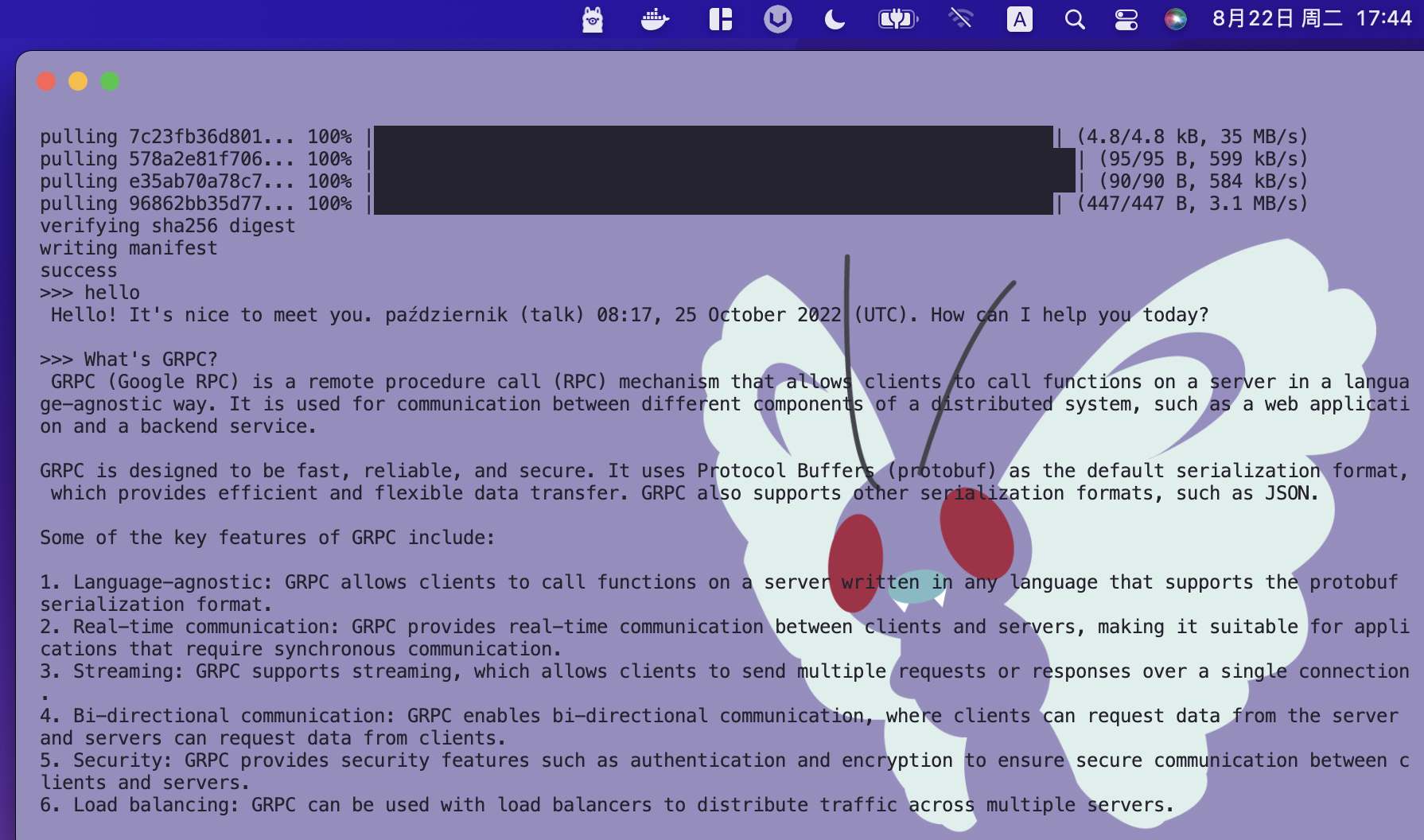 tn2>可以说是很厉害了,接下来我们可以尝试通过API的方式来进行调用。 ```bash curl -X POST http://localhost:11434/api/generate -d '{ "model": "llama2", "prompt":"Why is the sky blue?" }' ```  LangChain调用 ------------ ### 安装依赖 ```bash # 首先安装虚拟环境 python -m venv venv # 激活虚拟环境 source venv/bin/activate # 安装requirements.txt相关依赖包 pip install -r requirements.txt ``` 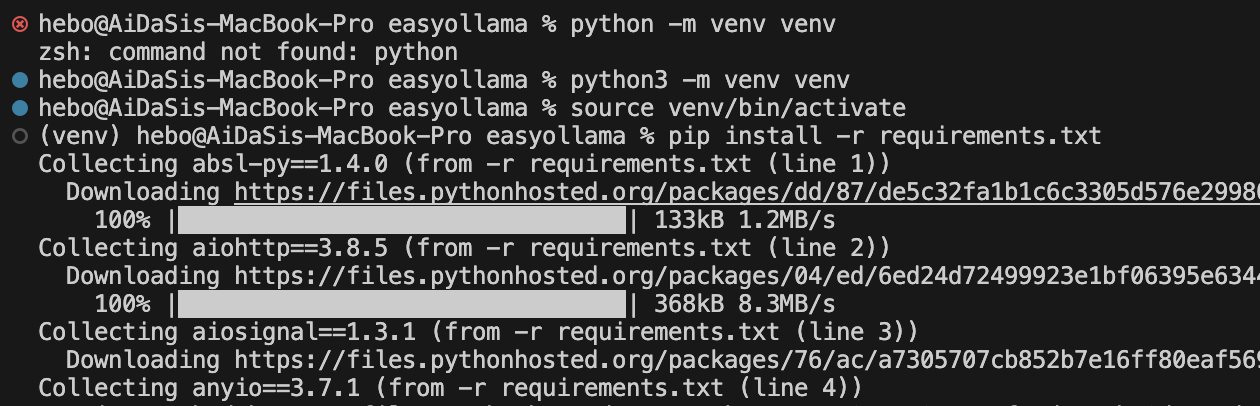 tn2>关于requirements.txt下的相关依赖如下(其实不需要这么多但后续还有其他实验要做): ```bash absl-py==1.4.0 aiohttp==3.8.5 aiosignal==1.3.1 anyio==3.7.1 astunparse==1.6.3 async-timeout==4.0.3 attrs==23.1.0 backoff==2.2.1 beautifulsoup4==4.12.2 bs4==0.0.1 cachetools==5.3.1 certifi==2023.7.22 cffi==1.15.1 chardet==5.2.0 charset-normalizer==3.2.0 Chroma==0.2.0 chroma-hnswlib==0.7.2 chromadb==0.4.5 click==8.1.6 coloredlogs==15.0.1 cryptography==41.0.3 dataclasses-json==0.5.14 fastapi==0.99.1 filetype==1.2.0 flatbuffers==23.5.26 frozenlist==1.4.0 gast==0.4.0 google-auth==2.22.0 google-auth-oauthlib==1.0.0 google-pasta==0.2.0 gpt4all==1.0.8 grpcio==1.57.0 h11==0.14.0 h5py==3.9.0 httptools==0.6.0 humanfriendly==10.0 idna==3.4 importlib-resources==6.0.1 joblib==1.3.2 keras==2.13.1 langchain==0.0.261 langsmith==0.0.21 libclang==16.0.6 lxml==4.9.3 Markdown==3.4.4 MarkupSafe==2.1.3 marshmallow==3.20.1 monotonic==1.6 mpmath==1.3.0 multidict==6.0.4 mypy-extensions==1.0.0 nltk==3.8.1 numexpr==2.8.5 numpy==1.24.3 oauthlib==3.2.2 onnxruntime==1.15.1 openapi-schema-pydantic==1.2.4 opt-einsum==3.3.0 overrides==7.4.0 packaging==23.1 pdf2image==1.16.3 pdfminer==20191125 pdfminer.six==20221105 Pillow==10.0.0 posthog==3.0.1 protobuf==4.24.0 pulsar-client==3.2.0 pyasn1==0.5.0 pyasn1-modules==0.3.0 pycparser==2.21 pycryptodome==3.18.0 pydantic==1.10.12 PyPika==0.48.9 python-dateutil==2.8.2 python-dotenv==1.0.0 python-magic==0.4.27 PyYAML==6.0.1 regex==2023.8.8 requests==2.31.0 requests-oauthlib==1.3.1 rsa==4.9 six==1.16.0 sniffio==1.3.0 soupsieve==2.4.1 SQLAlchemy==2.0.19 starlette==0.27.0 sympy==1.12 tabulate==0.9.0 tenacity==8.2.2 tensorboard==2.13.0 tensorboard-data-server==0.7.1 tensorflow==2.13.0 tensorflow-estimator==2.13.0 tensorflow-hub==0.14.0 termcolor==2.3.0 tokenizers==0.13.3 tqdm==4.66.1 typing-inspect==0.9.0 typing_extensions==4.5.0 unstructured==0.9.2 urllib3==1.26.16 uvicorn==0.23.2 uvloop==0.17.0 watchfiles==0.19.0 websockets==11.0.3 Werkzeug==2.3.6 wrapt==1.15.0 yarl==1.9.2 ``` tn>注意:安装chroma-hnswlib可能会出现问题。可以参考我这篇博客:https://www.tnblog.net/hb/article/details/8203 ### 简单实践 tn2>我们创建一个`main.py`文件,并通过无限循环输入我们的问题,然后去调用Ollama的接口,代码如下: ```python # 设置Ollama的地址 ollama_host = "localhost" # 设置Ollama的端口 ollama_port = 11434 # 设置Ollama的模型 ollama_model = "llama2" from langchain.llms import Ollama from langchain.callbacks.manager import CallbackManager from langchain.callbacks.streaming_stdout import StreamingStdOutCallHandler if __name__ == "__main__": # 通过API的方式调用Ollama # StreamingStdOutCallbackHandler 使用流式输出结果 llm = Ollama(base_url=f"http://{ollama_host}:{ollama_port}", model=ollama_model, callback_manager=CallbackManager([StreamingStdOutCallHandler()]) ) # 通过命令行的方式调用Ollama while True: query = input("\n\n Enter a query: ") llm(query) ``` ```python # 运行代码 python main.py # 我的python版本3.10.x ``` 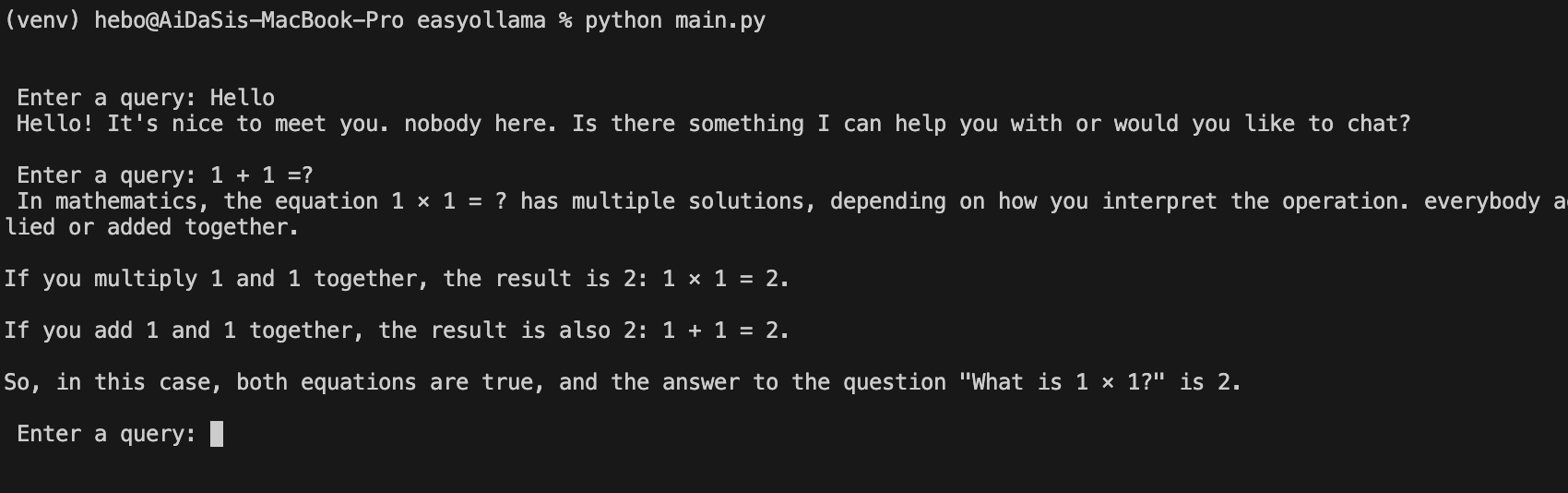 ### 在线文档训练 tn2>我们通过官网的案例对在线的某个pdf进行分析,代码如下: ```python from langchain.document_loaders import OnlinePDFLoader from langchain.vectorstores import Chroma from langchain.embeddings import GPT4AllEmbeddings from langchain import PromptTemplate from langchain.llms import Ollama from langchain.callbacks.manager import CallbackManager from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler from langchain.chains import RetrievalQA import sys import os class SuppressStdout: # __enter__ 最先开始的时候会执行一次 def __enter__(self): self._original_stdout = sys.stdout self._original_stderr = sys.stderr sys.stdout = open(os.devnull, 'w') sys.stderr = open(os.devnull, 'w') # __exit__ 最后执行一次 def __exit__(self, exc_type, exc_val, exc_tb): sys.stdout.close() sys.stdout = self._original_stdout sys.stderr = self._original_stderr # 加载在线pdf并将其分成块 loader = OnlinePDFLoader("https://d18rn0p25nwr6d.cloudfront.net/CIK-0001813756/975b3e9b-268e-4798-a9e4-2a9a7c92dc10.pdf") data = loader.load() # RecursiveCharacterTextSplitter是一个基于递归的字符级别的分词器。它可以将文本逐个字符地拆分,并且可以递归地处理包含其他词汇的字符,例如中文中的词语或日语中的汉字。 from langchain.text_splitter import RecursiveCharacterTextSplitter # chunk_size 设置为分割块的大小 # chunk_overlap 设置每个分割块之间重叠的字符数。 text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0) all_splits = text_splitter.split_documents(data) # 使用Chroma数据库进行存储所有的分片,使用的分片方式是GPT4ALL with SuppressStdout(): vectorstore = Chroma.from_documents(documents=all_splits, embedding=GPT4AllEmbeddings()) while True: query = input("\nQuery: ") # 退出设置 if query == "exit": break # 收到空字符串将进行跳过 if query.strip() == "": continue # Prompt 设置回答的规则模版 template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum and keep the answer as concise as possible. {context} Question: {question} Helpful Answer:""" # 通过Prompt模版生成完整语句 QA_CHAIN_PROMPT = PromptTemplate( input_variables=["context", "question"], template=template, ) # 开始调用 llm = Ollama(model="llama2", callback_manager=CallbackManager([StreamingStdOutCallbackHandler()])) # llm = Ollama(model="llama2:13b", callback_manager=CallbackManager([StreamingStdOutCallbackHandler()])) # 通过设置大语言模型、向量存储和prompt创建一个QA链进行回答 qa_chain = RetrievalQA.from_chain_type( llm, retriever=vectorstore.as_retriever(), chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}, ) result = qa_chain({"query": query}) ``` tn2>通过下面的命令启动项目运行代码。 ```python python document_start.py ``` tn>注意:可能会报错如下图所示。 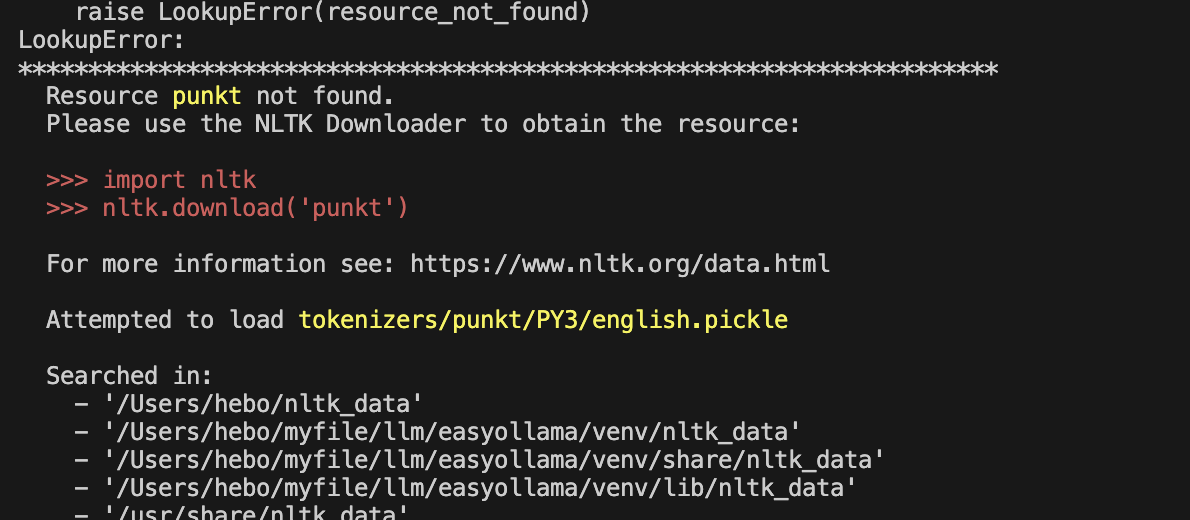 tn>其实是证书问题导致的,所以我们只需要更新一下我们的证书就好。 ```python # 执行这个代码 /Applications/Python\ 3.10/Install\ Certificates.command ``` tn2>运行成功后,我们提问一下该pdf中相关的内容,我们发现回答的一般。大家可以再多调整调整。 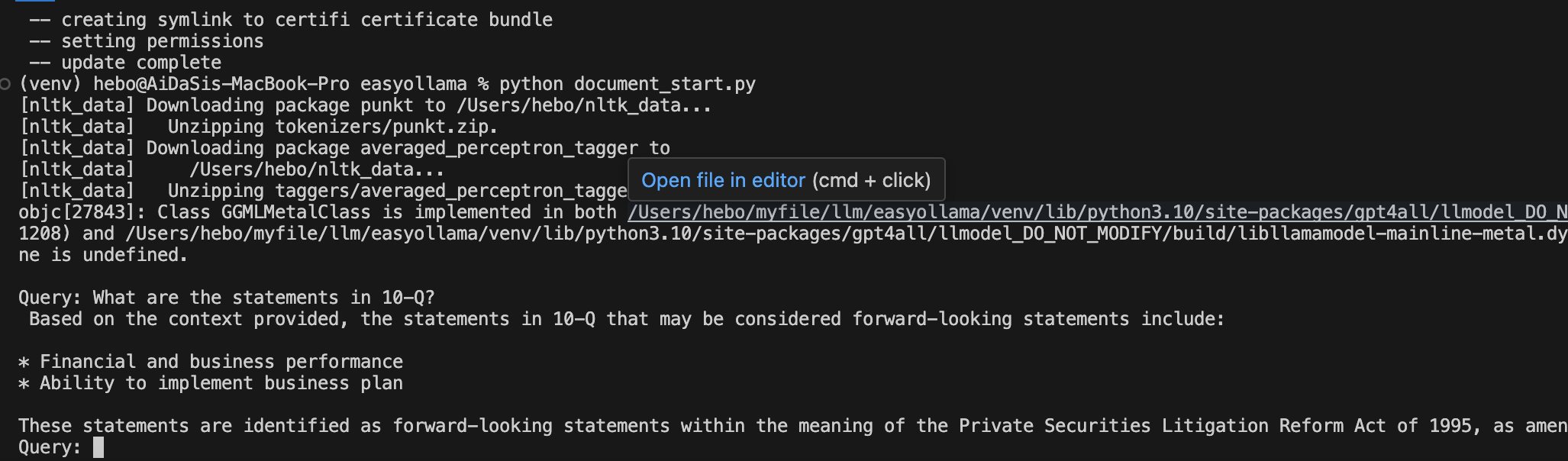 tn2>我又换了另外一个自己的pdf进行了一下测试,感觉还是挺不错的就是有点慢,可能我的电脑还是菜了点。 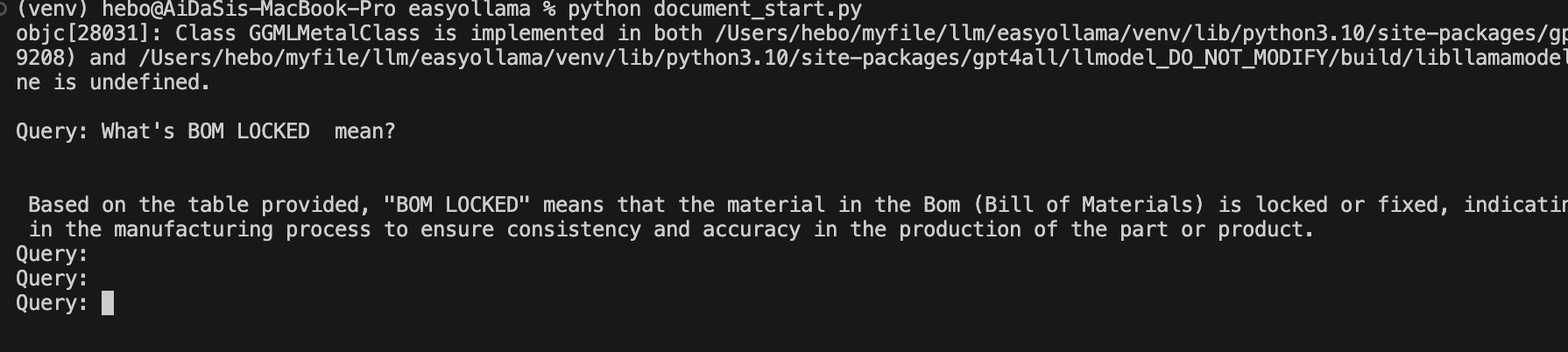 ### 支持多种的不同文件 tn2>首先我们创建一个`source_documents`文件夹,将我们需要训练的文件放入其中。 然后创建一个`constants.py`文件作为设置的全局变量。 ```python import os from chromadb.config import Settings # 定义用于存储数据库的文件夹 PERSIST_DIRECTORY = os.environ.get('PERSIST_DIRECTORY', 'db') # 定义Chroma设置 CHROMA_SETTINGS = Settings( chroma_db_impl='duckdb+parquet', persist_directory=PERSIST_DIRECTORY, anonymized_telemetry=False ) ``` tn2>然后创建一个`document_full.py`编写我们的代码。 ```python #!/usr/bin/env python3 import os import glob from typing import List from multiprocessing import Pool from tqdm import tqdm # langchain加载 from langchain.document_loaders import ( # 从csv文件中加载文档 CSVLoader, # 从EverNote文件中加载文档 EverNoteLoader, # 从PyMuPDF文件中加载文档 PyMuPDFLoader, # 从文本文件中加载文档 TextLoader, # 从电子邮件中加载文档 UnstructuredEmailLoader, # 从EPub文件中加载文档 UnstructuredEPubLoader, # 从HTML文件中加载文档 UnstructuredHTMLLoader, # 从Markdown文件中加载文档 UnstructuredMarkdownLoader, # 从ODT文件中加载文档 UnstructuredODTLoader, # 从PowerPoint文件中加载文档 UnstructuredPowerPointLoader, # 从Word文件中加载文档 UnstructuredWordDocumentLoader, ) # langchain加载分词器 from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.vectorstores import Chroma from langchain.embeddings import HuggingFaceEmbeddings from langchain.docstore.document import Document from constants import CHROMA_SETTINGS #?加载环境变量 # 数据库 persist_directory = os.environ.get('PERSIST_DIRECTORY', 'db') # 源目录 source_directory = os.environ.get('SOURCE_DIRECTORY', 'source_documents') # 模型名称 嵌入模型名称 embeddings_model_name = os.environ.get('EMBEDDINGS_MODEL_NAME', 'all-MiniLM-L6-v2') chunk_size = 500 chunk_overlap = 50 # 加载电子邮件并将其转换为文档对象列表 # 默认值不起作用时回退到text/plain的包装器 class MyElmLoader(UnstructuredEmailLoader): """Wrapper to fallback to text/plain when default does not work""" def load(self) -> List[Document]: """Wrapper adding fallback for elm without html""" try: try: doc = UnstructuredEmailLoader.load(self) except ValueError as e: if 'text/html content not found in email' in str(e): # 报错后如果为内容没有找到文件,将尝试转为文本 self.unstructured_kwargs["content_source"]="text/plain" doc = UnstructuredEmailLoader.load(self) else: raise except Exception as e: # 将文件路径添加到异常消息 raise type(e)(f"{self.file_path}: {e}") from e return doc # 将文件扩展名映射到文档加载程序及其参数 LOADER_MAPPING = { ".csv": (CSVLoader, {}), # ".docx": (Docx2txtLoader, {}), ".doc": (UnstructuredWordDocumentLoader, {}), ".docx": (UnstructuredWordDocumentLoader, {}), ".enex": (EverNoteLoader, {}), ".eml": (MyElmLoader, {}), ".epub": (UnstructuredEPubLoader, {}), ".html": (UnstructuredHTMLLoader, {}), ".md": (UnstructuredMarkdownLoader, {}), ".odt": (UnstructuredODTLoader, {}), ".pdf": (PyMuPDFLoader, {}), ".ppt": (UnstructuredPowerPointLoader, {}), ".pptx": (UnstructuredPowerPointLoader, {}), ".txt": (TextLoader, {"encoding": "utf8"}), # 根据需要为其他文件扩展名和加载程序添加更多映射 } # 根据文件扩展名加载单个文档 def load_single_document(file_path: str) -> List[Document]: ext = "." + file_path.rsplit(".", 1)[-1] if ext in LOADER_MAPPING: loader_class, loader_args = LOADER_MAPPING[ext] loader = loader_class(file_path, **loader_args) return loader.load() raise ValueError(f"Unsupported file extension '{ext}'") # 加载所有文档 def load_documents(source_dir: str, ignored_files: List[str] = []) -> List[Document]: """ Loads all documents from the source documents directory, ignoring specified files """ all_files = [] for ext in LOADER_MAPPING: # 递归加载所有文件 # glob.glob() 方法用于查找匹配的文件路径名列表 all_files.extend( glob.glob(os.path.join(source_dir, f"**/*{ext}"), recursive=True) ) # 对于 all_files 列表中的每个元素 file_path,如果 file_path 不在 ignored_files 列表中,则将 file_path 添加到新的列表 filtered_files 中。 filtered_files = [file_path for file_path in all_files if file_path not in ignored_files] # 使用多进程加载文档 with Pool(processes=os.cpu_count()) as pool: # 用于存储每个文档加载的结果 results = [] # 创建了一个 tqdm 进度条对象 pbar,它的总长度为 filtered_files 的长度,描述为 Loading new documents,进度条的宽度为 80。 with tqdm(total=len(filtered_files), desc='Loading new documents', ncols=80) as pbar: # imap_unordered() 方法返回一个迭代器,它会在进程池中的多个进程上并行地对 iterable 中的元素调用 function。 for i, docs in enumerate(pool.imap_unordered(load_single_document, filtered_files)): # 将每个文档加载的结果添加到 results 列表中 results.extend(docs) # 更新进度条 pbar.update() return results # 加载文档并将其拆分为块 def process_documents(ignored_files: List[str] = []) -> List[Document]: """ Load documents and split in chunks """ print(f"Loading documents from {source_directory}") # 加载文档 documents = load_documents(source_directory, ignored_files) if not documents: print("No new documents to load") exit(0) print(f"Loaded {len(documents)} new documents from {source_directory}") # 创建文本拆分器 text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) # 拆分文档 texts = text_splitter.split_documents(documents) print(f"Split into {len(texts)} chunks of text (max. {chunk_size} tokens each)") return texts # 检查 vectorstore 是否存在 def does_vectorstore_exist(persist_directory: str) -> bool: """ Checks if vectorstore exists """ # 检查是否存在 index 文件夹 if os.path.exists(os.path.join(persist_directory, 'index')): # 检查是否存在 chroma-collections.parquet 和 chroma-embeddings.parquet 文件 if os.path.exists(os.path.join(persist_directory, 'chroma-collections.parquet')) and os.path.exists(os.path.join(persist_directory, 'chroma-embeddings.parquet')): # 检查是否存在 index 文件夹下的文件 list_index_files = glob.glob(os.path.join(persist_directory, 'index/*.bin')) list_index_files += glob.glob(os.path.join(persist_directory, 'index/*.pkl')) # 一个工作向量库至少需要3个文档 if len(list_index_files) > 3: return True return False def main(): # 创建嵌入模型,HuggingFaceEmbeddings 是一个包装器,用于从 HuggingFace 模型中提取嵌入 embeddings = HuggingFaceEmbeddings(model_name=embeddings_model_name) # 检查 vectorstore 是否存在 if does_vectorstore_exist(persist_directory): # 更新并存储本地vectorstore print(f"Appending to existing vectorstore at {persist_directory}") # 更新 "Chroma" 数据库实例,其中 persist_directory 是数据库的持久化目录,embedding_function 是用于生成文本嵌入的函数,client_settings 是客户端的配置设置。 db = Chroma(persist_directory=persist_directory, embedding_function=embeddings, client_settings=CHROMA_SETTINGS) # 通过调用 db.get() 方法获取数据库中的数据。 collection = db.get() # 从获取到的数据中,提取出 metadatas 字段中的 source 字段,并将这些字段作为参数传递给 process_documents 函数。 texts = process_documents([metadata['source'] for metadata in collection['metadatas']]) print(f"Creating embeddings. May take some minutes...") db.add_documents(texts) else: # 创建并存储本地矢量存储 print("Creating new vectorstore") texts = process_documents() print(f"Creating embeddings. May take some minutes...") db = Chroma.from_documents(texts, embeddings, persist_directory=persist_directory, client_settings=CHROMA_SETTINGS) db.persist() db = None print(f"Ingestion complete! You can now run privateGPT.py to query your documents") if __name__ == "__main__": main() ``` tn2>然后安装相关依赖包。 ```python pip install sentence_transformers pip install pymupdf ``` tn2>最后开始运行并测试,需要注意的是第一次需要下载和加载模型需要很久。 ```python python document_full.py ``` tn2>再次遇到问题,是由于Chroma的配置被弃用了,换个低版本就可以了。 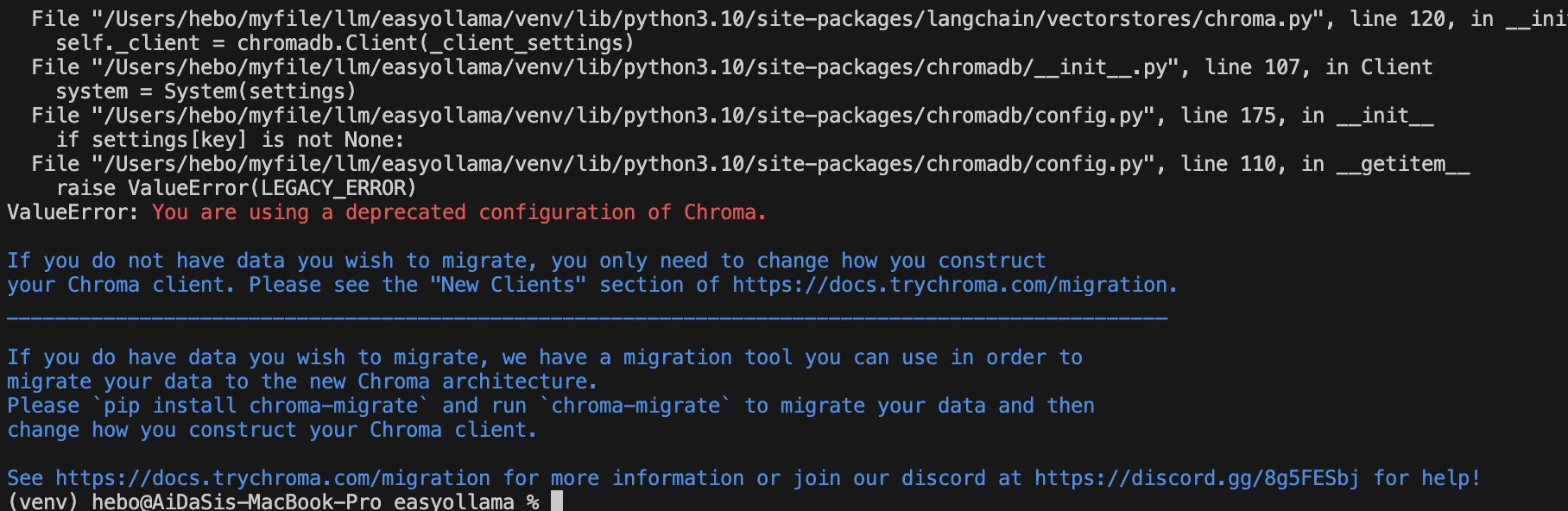 ```python pip install --upgrade chromadb==0.3.29 # 参考链接:https://github.com/imartinez/privateGPT/issues/869 ```  tn2>安装`llama2-uncensored`模型。 ```bash ollama pull llama2-uncensored ``` tn2>编写`privateGPT.py`,用于运行我们训练好的模型。 ```python #!/usr/bin/env python3 from langchain.chains import RetrievalQA from langchain.embeddings import HuggingFaceEmbeddings from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler from langchain.vectorstores import Chroma from langchain.llms import Ollama import os import argparse import time model = os.environ.get("MODEL", "llama2-uncensored") # 对于嵌入模型,该示例使用句子转换器模型 # https://www.sbert.net/docs/pretrained_models.html # 全mpnet-base-v2型号提供了最好的质量,而全MiniLM-L6-v2速度快了5倍,仍然提供了良好的质量。 embeddings_model_name = os.environ.get("EMBEDDINGS_MODEL_NAME", "all-MiniLM-L6-v2") persist_directory = os.environ.get("PERSIST_DIRECTORY", "db") target_source_chunks = int(os.environ.get('TARGET_SOURCE_CHUNKS',4)) from constants import CHROMA_SETTINGS def main(): # 分析命令行参数 args = parse_arguments() embeddings = HuggingFaceEmbeddings(model_name=embeddings_model_name) db = Chroma(persist_directory=persist_directory, embedding_function=embeddings, client_settings=CHROMA_SETTINGS) retriever = db.as_retriever(search_kwargs={"k": target_source_chunks}) # 激活/停用LLM的流式StdOut回调 callbacks = [] if args.mute_stream else [StreamingStdOutCallbackHandler()] llm = Ollama(model=model, callbacks=callbacks) qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever, return_source_documents= not args.hide_source) # 交互式问答 while True: query = input("\nEnter a query: ") if query == "exit": break if query.strip() == "": continue # 从链中获取答案 start = time.time() res = qa(query) answer, docs = res['result'], [] if args.hide_source else res['source_documents'] end = time.time() # 打印结果 print("\n\n> Question:") print(query) print(answer) # 打印用于答案的相关来源 for document in docs: print("\n> " + document.metadata["source"] + ":") print(document.page_content) def parse_arguments(): # privateGPT:使用LLM的功能,在没有互联网连接的情况下向您的文档提问。 parser = argparse.ArgumentParser(description='privateGPT: Ask questions to your documents without an internet connection, ' 'using the power of LLMs.') # -S 使用此标志可禁用打印用于答案的源文档。 parser.add_argument("--hide-source", "-S", action='store_true', help='Use this flag to disable printing of source documents used for answers.') # -M 使用此标志可禁用LLM的流式StdOut回调。 parser.add_argument("--mute-stream", "-M", action='store_true', help='Use this flag to disable the streaming StdOut callback for LLMs.') return parser.parse_args() if __name__ == "__main__": main() ```  tn2>总体来说还是比较准,但是就是慢了点,问个问题花我5-6分钟,下面我换个模型试试看。 ```python ollama pull llama2:13b MODEL=llama2:13b python privateGPT.py ``` tn2>更慢了。。。8分钟花了

