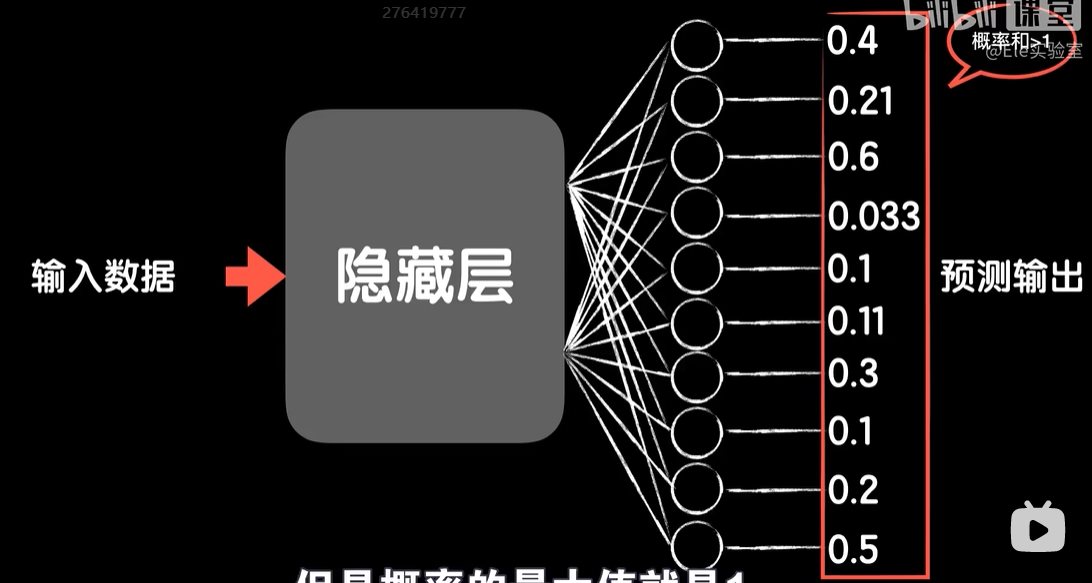
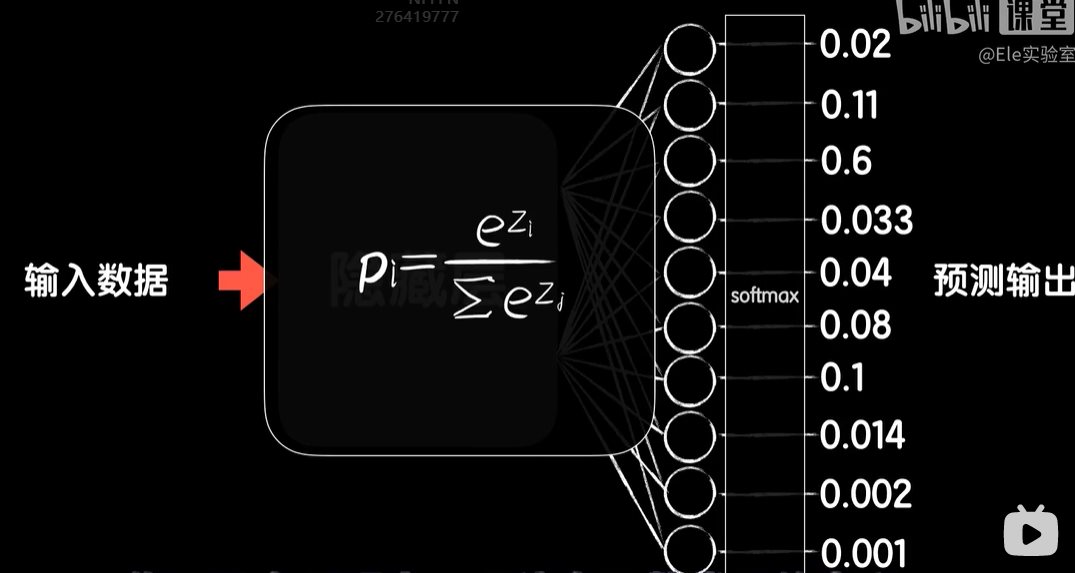
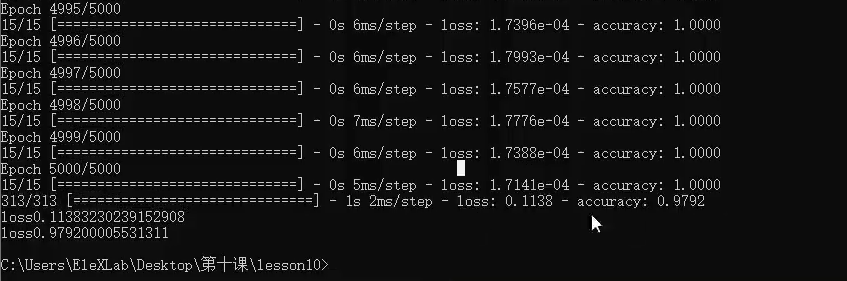
python 打破图像识别的瓶颈(学习笔记) 电脑版发表于:2023/5/5 19:22  >#python 打破图像识别的瓶颈(学习笔记) [TOC] 手写识别 ------------ tn2>mnist数据集的图片采用的28*28的灰度图。 ### 灰度图显示的原理 tn2>一行有28个像素点,一共有28行,每一个像素用一个字节的无符号数表示它的等级,如果是0就是黑色,是1就是白色,是中间的数就是不同程度的灰色。我们通过让不同像素点的灰度值不同而达到显示的效果  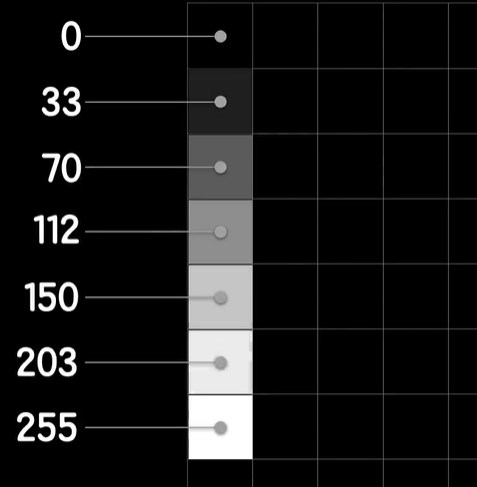 tn2>如果用键盘打出来识别这个图像没什么难度,因为键盘打出来的都是相同的。  tn2>但人写得难免手抖,比如写成如下几张,这样没规则的就无法进行判断了。   ### 神经网络识别图像 tn2>我们知道神经网络的输入是一个多维向量的,或者是一个数组。 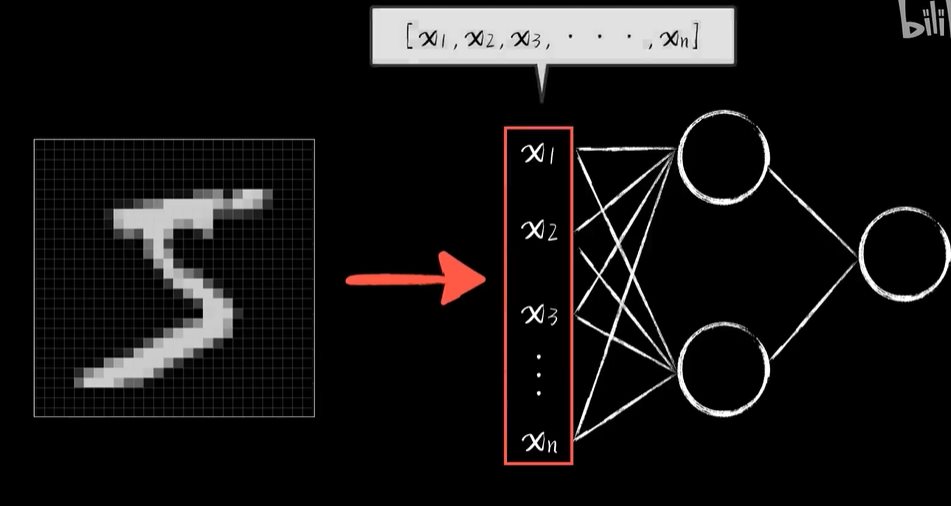 tn2>而图片是一个方形的像素灰度值集合,所以我们只需要将这些像素一个一个拉出来形成一个矩阵就可以了。 mnist数据集每张图片的尺寸是28*28,所以这将拉出784个像素,每个像素都是一个灰度值和起来就是一个矩阵。    tn2>依次送进一个神经网络进行训练就行,最开始人们利用深度全连接神经网络取得了不错的效果,但并不是十分的好。 在机器学习的工作流程中,我们在训练时使用的数据集称为`训练集`,当然我们希望训练集的准确率很高,这意味着模型拟合效果很棒,在训练集数据之外拿一些新的数据进行预测,看看新的训练的数据如何?这些用来测试的数据称之为`测试集`。  tn2>如果训练的准确率67%,很低那这个模型多半是废了。  tn2>如果在训练集上的准确率很高,但在测试集上准确率出现了明显的下降,那说明这个模型的泛化能力不行也就很难推而广之的进行实际应用,这种现象称之为:过拟合。 比如我们用一个过分复杂的模型,去拟合一些实则比简单的问题,我们以豆豆数据集举例子。 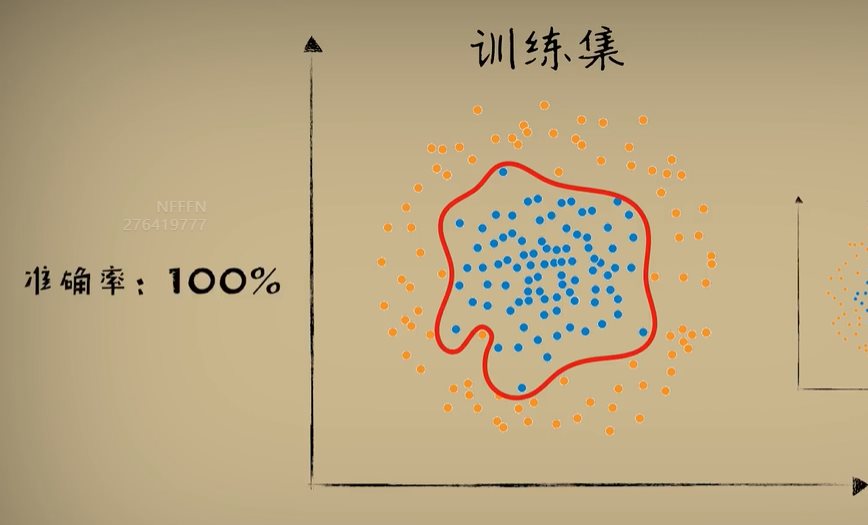 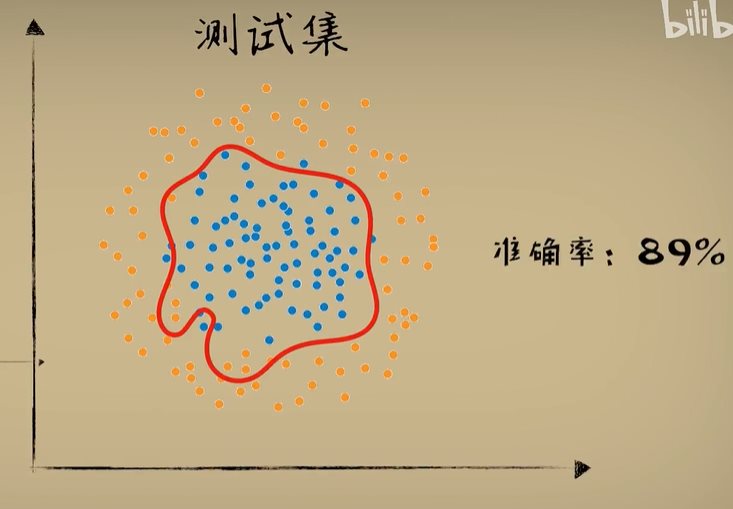 tn2>我们可以看到在训练集上拟合得很好但在测试集上反而没那么好,这就是过拟合。 由于模型不够泛化,或者说没有很好的把握事物的主要矛盾,解决神经网络的过拟合现象也有很多方式: | 方式 | | ------------ | | 调整网络结构 | | L2正则化 | | 节点失活(Dropout) | tn2>mnist数据集有60000个训练集样本和10000个测试集样本,而人们发现在用全连接神经网络做mnist数据集识别,以及其他的图像识别的时候,尽管我们把网络堆叠的越来越深,神经元也添加的越来越多,也用尽了各种防止过拟合的方法,但网络的泛化能力任然越来越难有突破。 ### 什么是卷积? tn2>某人专门做了一份研究,通过卷积神经网络把准确率提高到了`99.77%`,那么什么是卷积呢?卷积是怎么工作的? 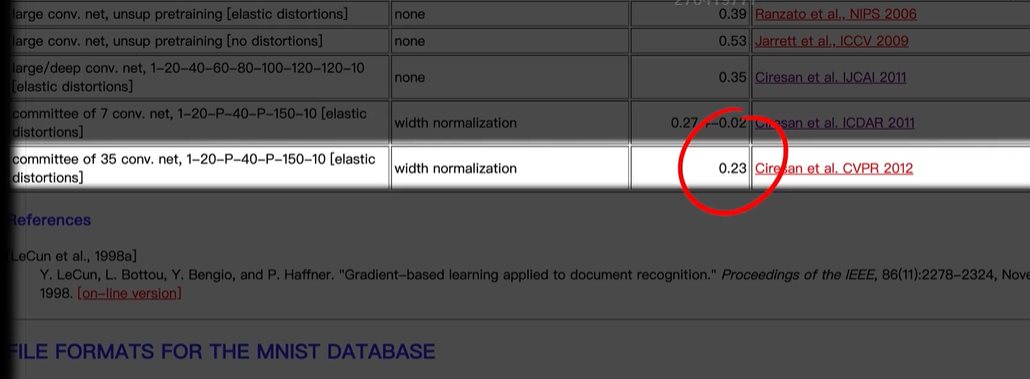 tn2>首先把这些像素点,通过卷积核与原始图像相乘之后再相加,得到卷积后图像。 当然一个像素块的灰度值是一个字节最大值是255,所以我们想把这个卷积后的结果显示出图像,需要把超过255的像素点都处理成255。 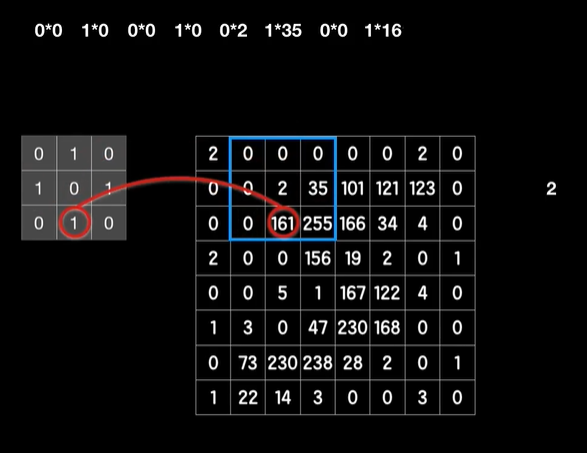 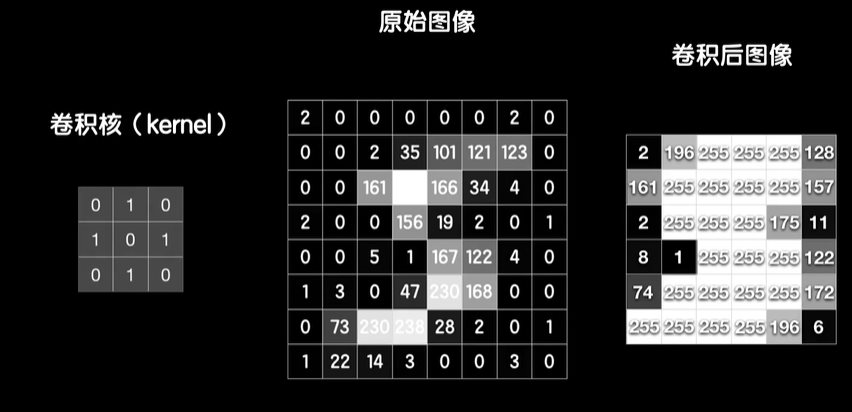 tn2>第一个三乘三的是一个卷积核,也被称为`过滤器`。 所以为什么这种卷积运算,可以提取图像的诸如轮廓,花纹颜色的特征呢?我们用一个简单的例子,通过下面的卷积核可以把垂直的边缘提取出来。  tn2>这是卷积核卷积的两个结果,会发现结果图片都开始显现垂直条纹的特征。 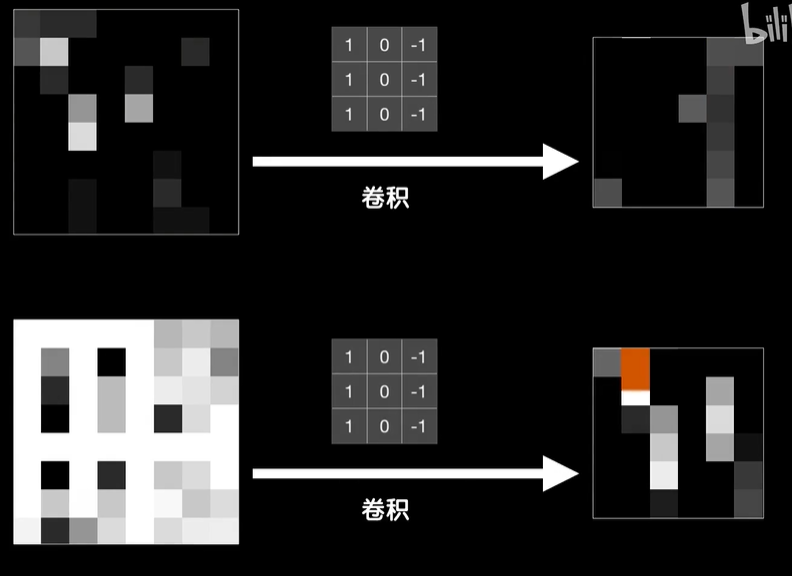 tn2>为了更加的简单,我们将取出一个杯子的边缘部分,在卷积的时候你会发现它的左边部分全是灰度值60,右边部分全是0。 而卷积核的左侧部分是1、中间是0、右侧是-1,所以在右侧的时候元素相乘再相加就等于0. 右侧部分相乘相加等于0,中间部分相乘相加等于180。     tn2>这样的卷积核是进行垂直边缘提取,同样通过颠倒一下卷积核可以进行水平边沿提取。 我们可以做一个简单的测试。   tn2>然后我们回到的手写识别,当我们使用普通的神经网络进行处理的时候,你认为神经网络认为左边的1是更像右边的1呢?还是右边的7?  tn2>很明显是7,虽然作为人能够很好的认为它是1,但是把这些像素块当成数组的时候,与7一模一样,但它相对于第一个1相对于向后挪动了一点点,反倒和第一个1对应位置的特征值相去甚远。    tn2>如果我们使用卷积核,结果就不一样了。 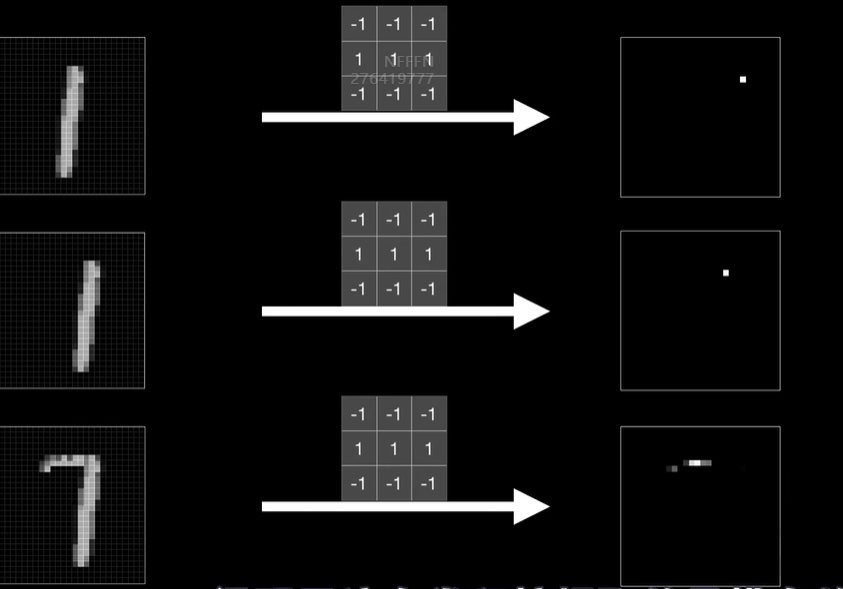 编程实践 ------------ tn2>通过`keras`的mnist进行加载数据并展示出来。 ```python from keras.datasets import mnist import numpy as np from keras.models import Sequential from keras.layers import Dense from keras.optimizers import SGD import matplotlib.pyplot as plt (X_train, Y_train), (X_test, Y_test) = mnist.load_data() print("X_train.shape:"+str(X_train.shape)) print("Y_train.shape:"+str(Y_train.shape)) print("X_test.shape:"+str(X_test.shape)) print("Y_test.shape:"+str(Y_test.shape)) # 打印第一个标签样本值 print(Y_train[0]) # 训练集的第一个样本数据 # 绘图模式为:灰度图(gray) plt.imshow(X_train[0],cmap='gray') plt.show() ``` 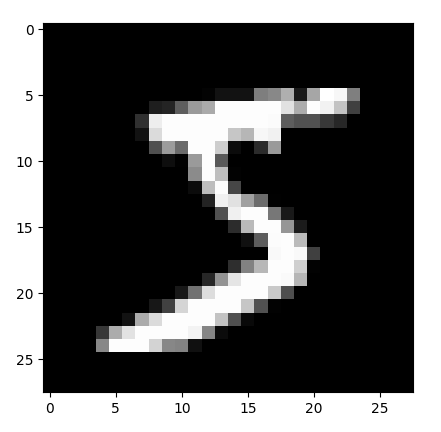 ```python from keras.datasets import mnist import numpy as np from keras.models import Sequential from keras.layers import Dense from keras.optimizers import SGD import plot_utils_2 import matplotlib.pyplot as plt from keras.utils.np_utils import to_categorical (X_train, Y_train), (X_test, Y_test) = mnist.load_data() print("X_train.shape:"+str(X_train.shape)) print("Y_train.shape:"+str(Y_train.shape)) print("X_test.shape:"+str(X_test.shape)) print("Y_test.shape:"+str(Y_test.shape)) # 打印第一个标签样本值 print(Y_train[0]) # 训练集的第一个样本数据 # 绘图模式为:灰度图(gray) plt.imshow(X_train[0],cmap='gray') plt.show() # ndarray 的 reshape函数改变数组的形状。 # 把28*28的图片像素转成784的数组。 # 除以255的目的在于降低梯度下降的复杂度 # 训练集 X_train = X_train.reshape(60000,784)/255 # 测试集 X_test = X_test.reshape(10000,784)/255 # 转换成One Hot编码 Y_train = to_categorical(Y_train,10) Y_test = to_categorical(Y_test,10) # 设置训练层以及神经元数量 model = Sequential() # input_dim = 784表示设置了784个像素块作为输出 model.add(Dense(units=256, activation='relu', input_dim=784)) model.add(Dense(units=256, activation='relu')) model.add(Dense(units=256, activation='relu')) # 输出十个值哪个最大哪个就最像 model.add(Dense(units=10, activation='softmax')) # 输出的预测值实际上是一个概率值。 # 但是十个输出的概率和大于了1,所以我们需要一个函数将这十个相加等于1就是softmax函数 # 设置策略,0.05的阿尔法每次,按照准确率 # 使用多分类交叉熵代价函数 model.compile(loss='categorical_crossentropy',optimizer=SGD(lr=0.05),metrics=['accuracy']) model.fit(X_train, Y_train, epochs=5000, batch_size=1024) # 添加测试数据进行测试模型的泛化能力 loss, accuracy = model.evaluate(X_test, Y_test) # 打印出损失和准确率 print("loss"+str(loss)) print("loss"+str(accuracy)) ```