python 数据探索与可视化洞见(二) 电脑版发表于:2023/3/29 10:09  >#python 数据探索与可视化洞见(二) [TOC] tn2>请根据上一篇结合。 地理数据的可视化 ------------ tn2>可使用DataFrame上的plot方法。 tn>举例:以经度和维度创建一个散点图,密集的地方以比较透明的方式做区分,并且以人员的多少来决定散点的大小,通过不同的房价来显示有区别的颜色,并显示颜色条。 ```python # kind="scatter" 散点图 # x 经度 # y 维度 housing.plot(kind="scatter", x="longitude", y="latitude") ``` 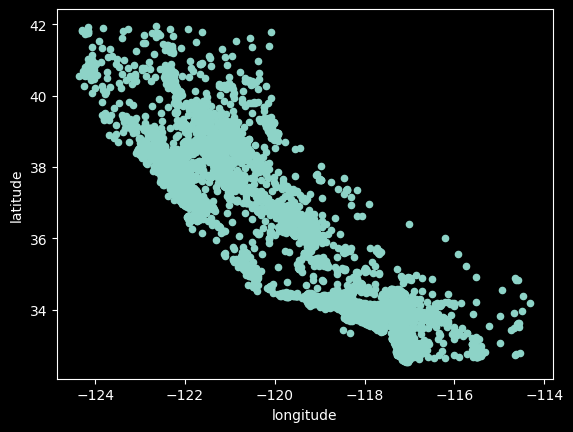 ```python # alpha 透明度 # 这里只的是在密度比较高的地方透明度就比较深反之比较浅 housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1) ``` 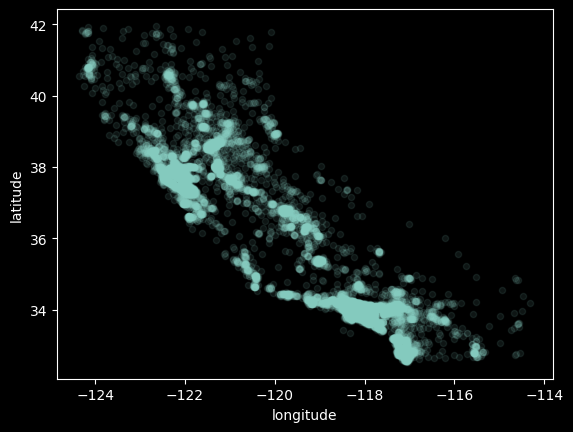 ```python # 然后我们通过人口比较多的圆圈就设置大一点。 # s 设置圈圈的大小 # label 就是标签 # figsize 改变大小 # c color通过什么属性代表颜色 # cmap 设置颜色表 # colorbar 是否显示彩色条 import matplotlib.pyplot as plt housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4, s=housing['population']/100, label="population", figsize=(10, 7),c="median_house_value",cmap=plt.get_cmap("jet"),colorbar=True) # legend 显示图例 plt.legend() ``` 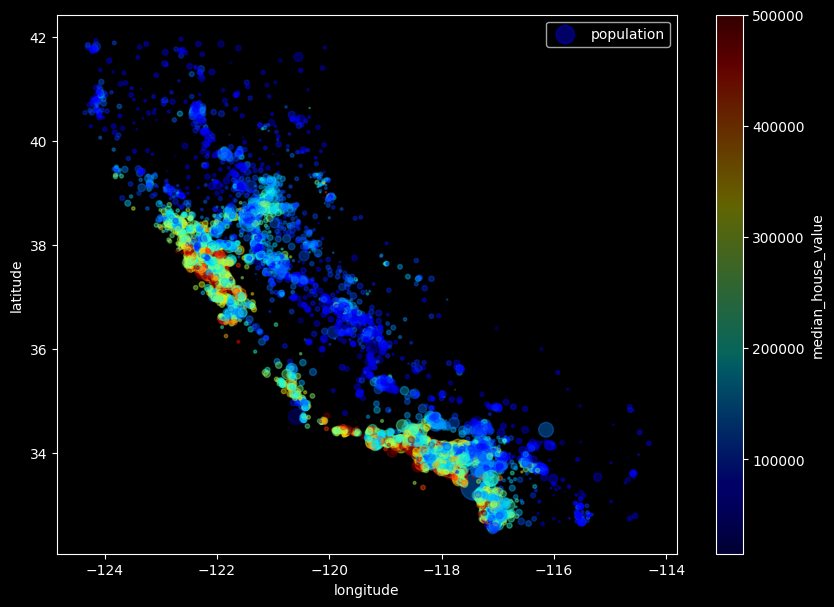 tn2>这里population表示人,红色的表示房价比较贵,蓝色的比较便宜这样就比较直观了。 寻找相关性 ------------ 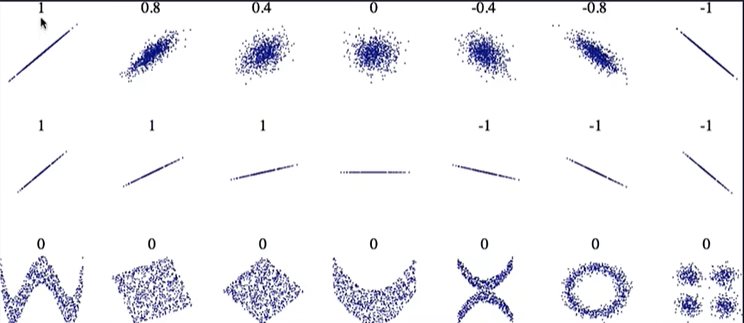 tn2>如上图第一列所示,第一个一条直线相关性就是一,开始慢慢分散就是0.8,然后0.4最后没有关系为0,然后反方向为-0.4、-0.8然后-1等。 第二列以斜度为主。 第三列两者与其他图片根本没有相关性所以都为0. corr函数可以表示其中的相关性。 ```bash # 安装jinja2包 pip install jinja2 ``` tn2>首先以当前的例子显示其中的关联性,以及通过颜色来进行区分它们的关联性。 ```python # numeric_only 关闭警告 corr_matrix = housing.corr(numeric_only=True) corr_matrix ``` 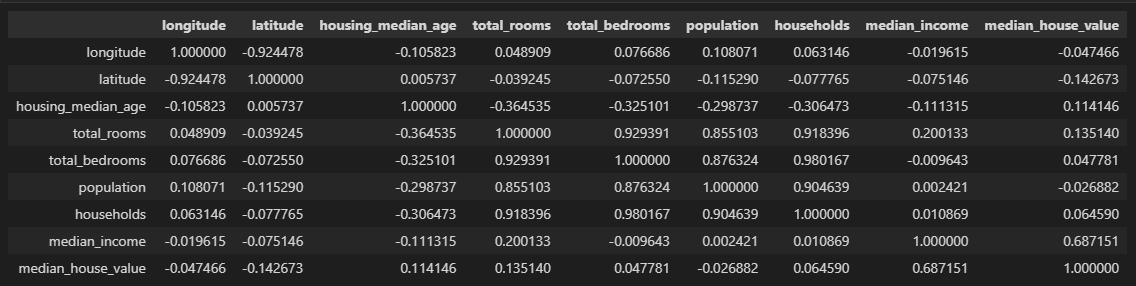 ```python # 设置背景颜色为coolwarm corr_matrix.style.background_gradient(cmap="coolwarm") ``` 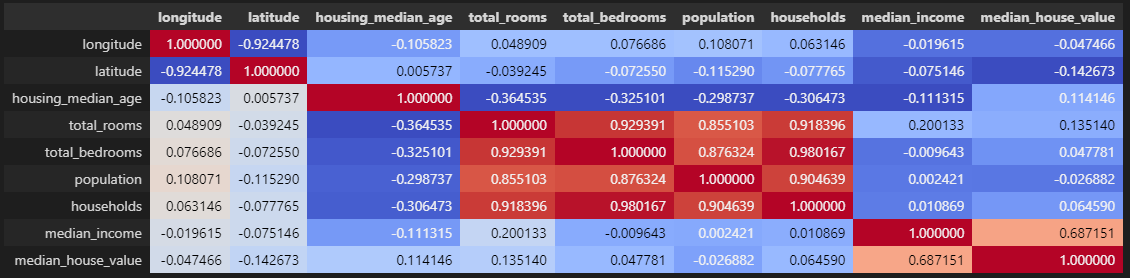 ```python # 仅预测房价的相关性 corr_matrix["median_house_value"].sort_values(ascending=False) ``` 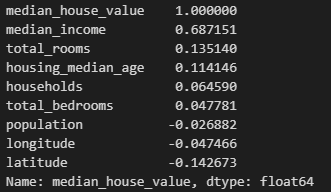 ```python # 通过房价预测、收入中位、房间数量、房间的年龄 from pandas.plotting import scatter_matrix attributes = ["median_house_value","median_income","total_rooms","housing_median_age"] scatter_matrix(housing[attributes],figsize=(12,8)) ``` 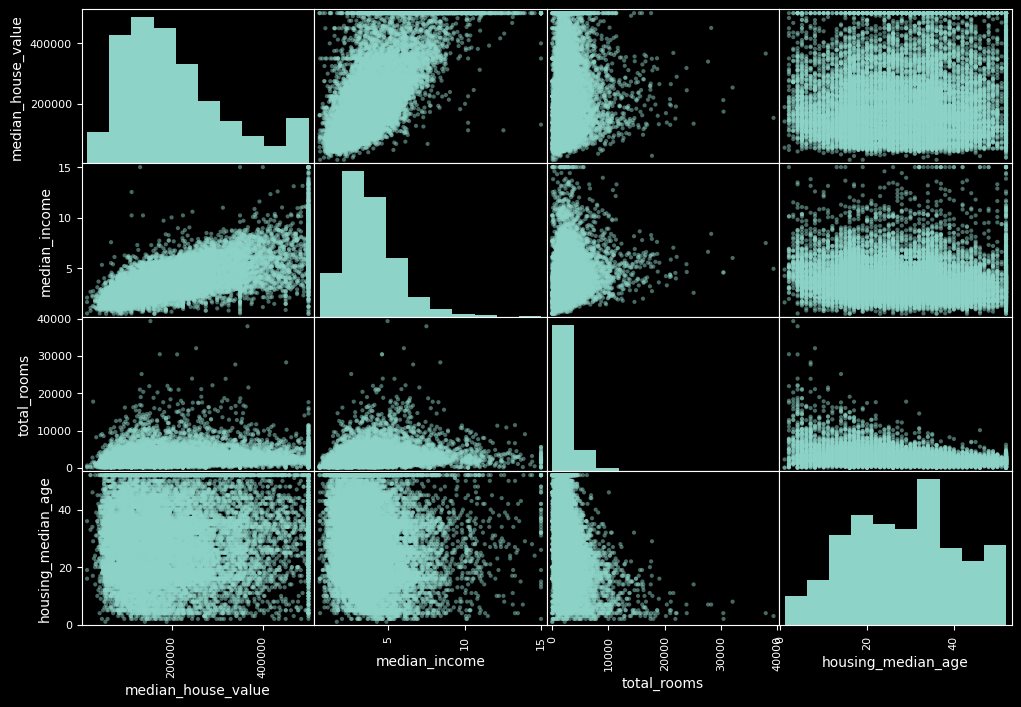 tn2>我们可以看到`median_house_value`(房价)与`median_income`(收入中位数)相关性比较强。 ```python # 通过散点图,再次查看收入中位数与房价的相关性 housing.plot(kind="scatter",x="median_income",y="median_house_value",alpha=0.1) ``` 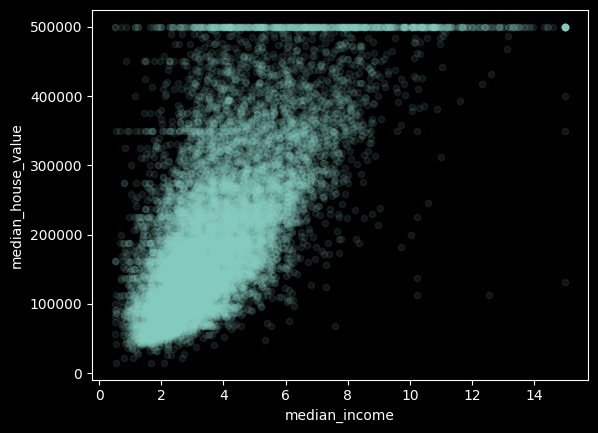 ML算法的数据准备 ------------ tn2>涉及的内容包含:数据清理、处理文本属性和分类属性、自定义转换器、特征缩放、转换流水线。 ### 数据清理 tn2>针对缺失的特征数据的三种选择: ——放弃相应的区域(去掉数据的某行) ——放弃整个属性(去掉数据的某列) ——将缺失的值设为某个数(0,平均数或中位数) 可通过DataFrame的dropna()、drop()、fillna()方法来实现 ```python # 查看有空的简单信息 housing.info() ``` 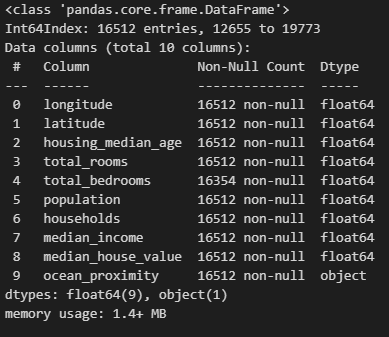 tn2>我们可以从上面的数据中看到`total_bedrooms`它的某些值为空,所以非空的只有16354行。 接下来我们通过`dropna`函数来进行过滤`total_bedrooms`非空的行。 ```python # 过滤total_bedrooms行不为空的 housing.dropna(subset="total_bedrooms") ``` 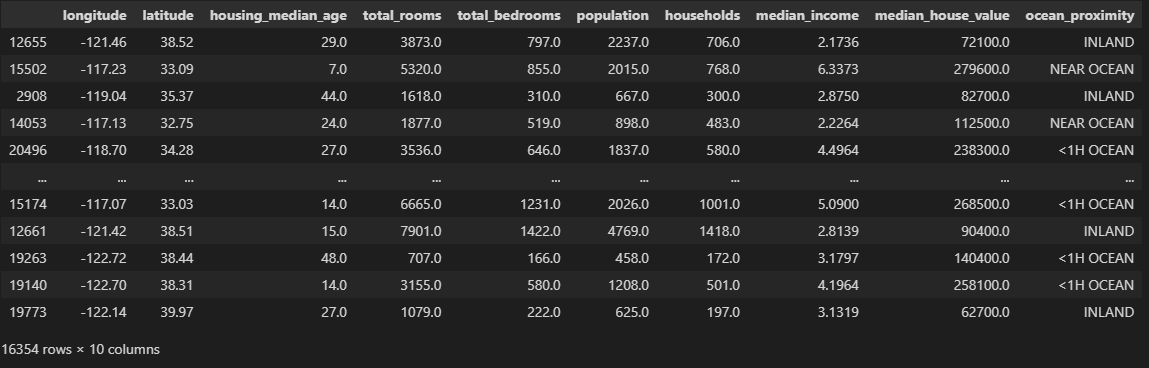 tn2>可以看到现在只有16354行了,但housing本身不会进行改变。 接下来我们可以通过`drop`来过滤掉某列,这里我们就过滤掉`total_bedrooms`就好了,因为它有非空值。 ```python housing.drop("total_bedrooms", axis=1) ``` 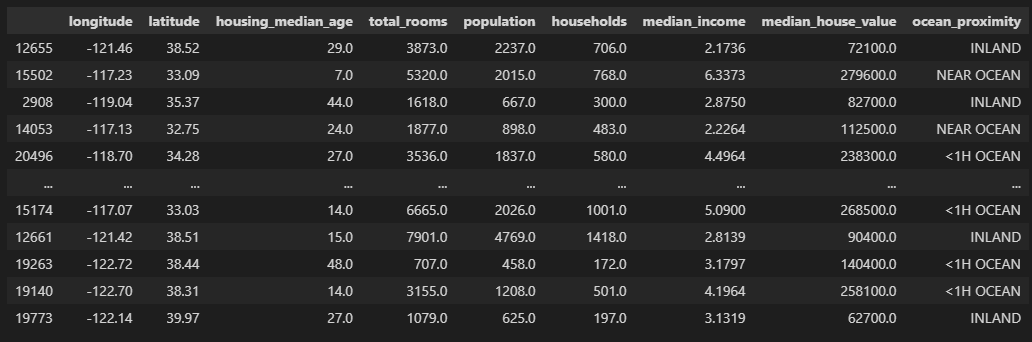 ```python # 获取一个total_bedrooms的中位数 median = housing["total_bedrooms"].median() # 将total_bedrooms列为空的数添加为中位数 housing["total_bedrooms"].fillna(median,inplace=True) housing.info() ``` 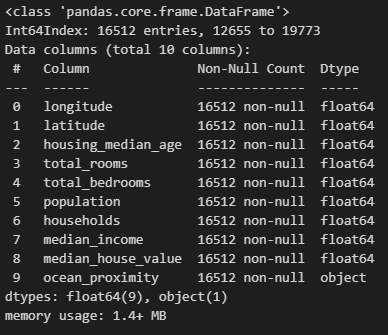 tn2>另一种取中位数的方式。 sklearn提供了一个Simplelmputer,挺简单的 ```python from sklearn.impute import SimpleImputer # 这里的策略设置为取中位数 imputer = SimpleImputer(strategy="median") # 缺点:只能用于数值类型,我们这里有一列不是数值类型的ocean_proximity所以我们需要删除这一列 housing_num = housing.drop("ocean_proximity", axis=1) # fit方法计算housing_num中位数 imputer.fit(housing_num) # 我们也可以通过statistics_获取每列的中位数 imputer.statistics_ ```  tn2>我们还可以通过`median().values`属性来验证一下它是否正确。  ```python # 填充缺失的结果附值中位数给housing_num X = imputer.transform(housing_num) X ``` 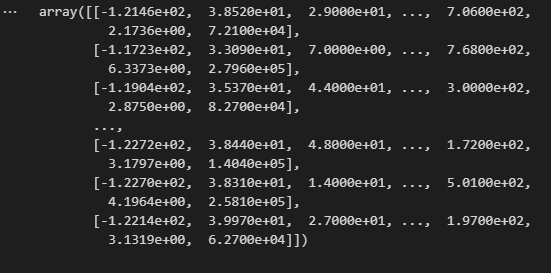 tn2>这样的方式太难看了,我们可以把它转换成数据图标的形式。 ```python housing_tr = pd.DataFrame(X, columns=housing_num.columns, index=housing_num.index) housing_tr.head() ```  ### 处理文本和分类 tn2>到目前为止,我们只处理数值类的属性。 有些熟悉是文本类型的(有点像枚举),就需要编码,将其变成数值 OrdinalEncoder:是一个用于将分类变量编码为整数的类。它可以用于将具有有序关系的分类变量编码为整数,例如“低”、“中”和“高”这样的变量。 OneHotEncoder:通过指定一定的规则,来确定它的排序。 ```python # 对ocean_proximity文本列查看值的总数 housing["ocean_proximity"].value_counts() ``` 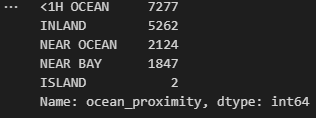 ```python from sklearn.preprocessing import OrdinalEncoder # 创建普通编码器的实例 ordinal_encoder = OrdinalEncoder() # 以这一列为例做成一张表 housing_cat = housing[["ocean_proximity"]] housing_cat.head() ```  ```python # 查看类型 type(housing_cat) ```  ```python # 编码转换 housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat) housing_cat_encoded[:10] # 查看数组 ordinal_encoder.categories_ ``` 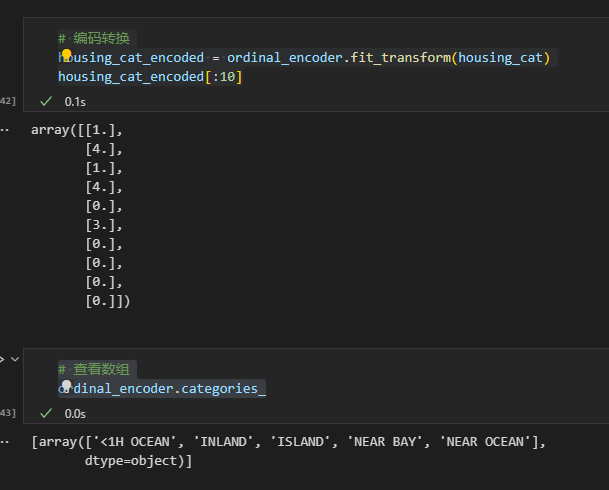 tn2>这种编码器它对于排序并没有逻辑可言。 接下来我们使用`OneHotEncoder`读热编码器。 ```python from sklearn.preprocessing import OneHotEncoder cat_encoder = OneHotEncoder() # 填充 housing_cat_1hot = cat_encoder.fit_transform(housing_cat) housing_cat_1hot.toarray() ``` ```python cat_encoder.categories_ ``` 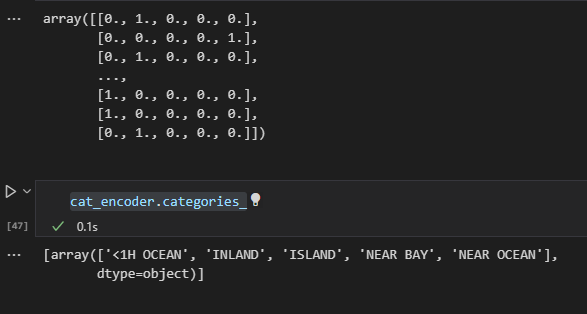 ### 自定义转换器 tn2>sklearn依赖于duck-typing的编译,而不是继承。所以只需要创建一个类,实现fit()、transform()、fit_transform()三个方法就可以自定义转换器;可以通过使用TransformerMixin得到fit_transform(),以及BaseEsitimator作为基类,可获得两种自动调整超参数的方法(`get_params`和`set_params`)。 tn>举例:我们自定义转换器,算出每个房子有多少个房间、每个房子有多少个人。 ```python from sklearn.base import BaseEstimator, TransformerMixin rooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6 class CombinedAttributesAdder(BaseEstimator, TransformerMixin): def __init__(self,add_bedrooms_per_room = True): # 是否添加bedrooms self.add_bedrooms_per_room = add_bedrooms_per_room def fit(self, X, y=None): # 填充 # 这里直接返回 return self def transform(self, X): # 转换 # 求每个房子有多少个房间:房间数除以房子。 rooms_per_household = X[:, rooms_ix] / X[:, households_ix] # 求每个房子有多少个人:人数除以房子。 population_per_household = X[:, population_ix] / X[:, households_ix] # 判断是否添加卧室,如果添加就再求每个房间数有多少个卧室 if self.add_bedrooms_per_room: bedroom_per_room = X[:, bedrooms_ix] / X[:, rooms_ix] # 该方法表示向矩阵后面加三列 return np.c_[X, rooms_per_household, population_per_household, bedroom_per_room] else: return np.c_[X, rooms_per_household, population_per_household] ``` ```python attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False) housing_extra_attribs = attr_adder.transform(housing.values) housing_extra_attribs ``` 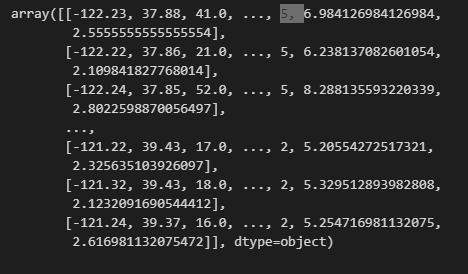 tn2>那么第一行呢就是,平均6个房间,2个人。 ### 特征缩放 tn2>如果输入的数值属性之间具有非常大的比例差异,那么机器学习的性能通常会表现不佳,这时候就需要特征缩放。 同比例缩放所有属性的两种常用方法: 最大-最小缩放:最终范围0至1之间 标准化:减去平均值,除以方差,结果分布具有单位方差差。不绑定到特定范围。 可使用sklearn的MinMaxScaler、StandardScaler等,用来拟合训练集。 ### 转换流水线 tn2>许多转换步骤需要按正确的顺序执行,sklearn提供了Pipeline类来支持这样的转换。 ```python from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler ``` ```python # 挨个走 # imputer 首先取中位数 # attribs_adder 然后调用自定义的方法进行处理 # std_scaler 特征缩放 num_pipeline = Pipeline([ ('imputer', SimpleImputer(strategy="median")), ('attribs_adder', CombinedAttributesAdder()), ('std_scaler', StandardScaler()), ]) housing_num_tr = num_pipeline.fit_transform(housing_num) housing_num_tr ``` 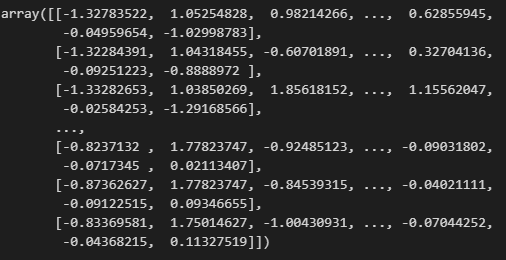 tn2>接下来将读热编码器和数值处理进行合并。 ```python num_attribs = list(housing_num) cat_attribs = ["ocean_proximity"] # 数值类型的流水线 # 处理分类 full_pipeline = ColumnTransformer([ ("num", num_pipeline, num_attribs), ("cat", OneHotEncoder(), cat_attribs), ]) # 最后传入数值 housing_prepared = full_pipeline.fit_transform(housing) housing_prepared.shape ```