python 机器学习的尝鲜实例(一)学习笔记 电脑版发表于:2023/3/28 17:32  >#python 机器学习的尝鲜实例(一)学习笔记 [TOC] 确定问题 ------------ tn2>任务:利用加州人口普查数据建立该州房价模型 ### 问题 tn2>要确定业务目标是什么?(如何从最终构建的模型中创效获益) 了解目标会决定很多事情: ————如何确定问题、选用哪个算法、选取哪个性能度量指标、如何评估模型、花费多少精力来优化调整它。 ————本例的目标:你的模型输出(房价中值预测)将与许多其他信号一起输入另一个机器学习系统。该下游系统将决定是否值得在特定区域投资。这一点至关重要,因为它直接影响收入。 明确答案 ------------ tn2>有监督学习:已经给出标记的训练数据。(举例:有一堆房产数据) 无监督学习:就是给你几个人你给它分类 回归:要对某个值进行预测。(通过一个指标就可以进行预测,比如:这个人体重多少就能测出大概的身高) 多重回归:使用多个特征进行预测。(多个特征进行预测就是多重回归) 一元回归:只预测单个值(由于我们只预测房价所以就是一元回归) (没有连续数据不断流入系统,无需针对变化数据做出特别调整,数据量不大简单的批量学习即可) 选择性能指标RMSE ------------ tn2>回归问题的典型性能指标是:RMSE(均方根误差) | 参数 | 描述 | | ------------ | ------------ | | m | 数据集中的数据数量。 | | x(i) | 数据集中第i个实例的所有特征;y(i):是其标签(该实例的期望输出值) | | X | 矩阵,包含数据集所有实例的所有特征(不包含标签)。 | | h | 是系统的预测函数,也称为假设。 | | RMSE(X,h) | 就是使用预测函数h,在一组示例数据中测量的成本函数。 |   tn2>这个公式主要是通过输入x(i)与h相乘得出预测房价值减去y(i)实际房价值的平方,最后所有数据加到一起的总和除以m行数。 这就是均方根误差。 选择性能指标MAE ------------  tn2>MAE:平均绝对误差 RMSE和MAE都是测量两个向量(预测值向量喝目标值向量)之间距离的方法。 开始实践 ------------ ### 获取数据 tn2>我使用的是VSCode,并且装的Jupyter插件。 首先下载数据集:https://github.com/ageron/handson-ml2/blob/master/datasets/housing/housing.tgz 下到本地,解压后是一个`housing.csv`的文件 ### 安装相关库 tn2>我们需要安装`pandas`、`matplotlib`、`scikit-learn`这三个库,安装命令如下: ```bash pip install pandas pip install matplotlib pip install scikit-learn ``` ### Pandas tn2>Pandas库是一个流行的Python数据操作和分析库。它提供了用于高效存储和操作大型数据集的数据结构,以及用于数据清理、合并和重塑的工具。 Pandas的一些主要特征包括: 用于存储和操作表格数据的DataFrame和Series数据结构 用于在各种文件格式(包括CSV、Excel和SQL数据库)中读取和写入数据的工具 内置数据清理、过滤和聚合功能 支持处理缺失数据和处理重复数据 与其他流行的Python库集成,如NumPy和Matplotlib 接下来我们创建一个`main.ipynb`,来导入这个库并读取`housing.csv`文件。 ```python import pandas as pd housing = pd.read_csv('housing.csv') ``` tn2>housing的相关方法如下: | 方法名 | 描述 | | ------------ | ------------ | | read_csv | 读取数据源 | | head | 默认看前5行数据 | | info | 数据集的简单描述,总行数、属性类型、非空值等。 | | describe | 数值属性的摘要 | | hist | 直方图 | ```python housing.head() # 查看前十行数据 housing.head(10) ```  ```python housing.info() ``` 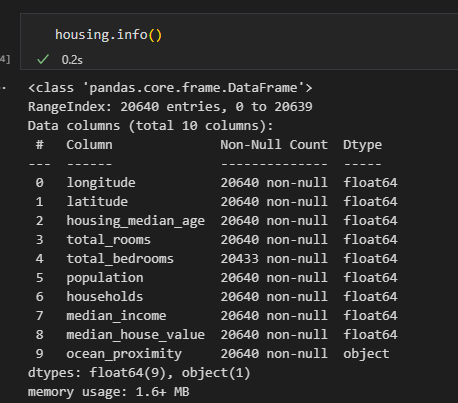 ```python housing.describe() ``` 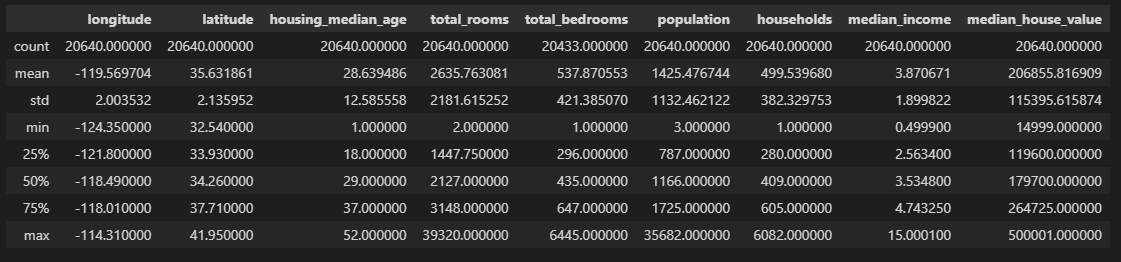 | 列 | 描述 | | ------------ | ------------ | | count | 值的总数是多少,不包含非空 | | mean | 平均值 | | std | 标准差,方差的平方根 | | min | 最小值 | | max | 最大值 | | 25% | 把数从小到大进行排列,排列出25%那一列的数 | | 50% | 把数从小到大进行排列,排列出50%那一列的数 | | 75% | 把数从小到大进行排列,排列出75%那一列的数 | ```python housing.hist() # bins=每个数据分成50项 # figsize=设计图形的大小 housing.hist(bins=50, figsize=(20, 15)) ``` 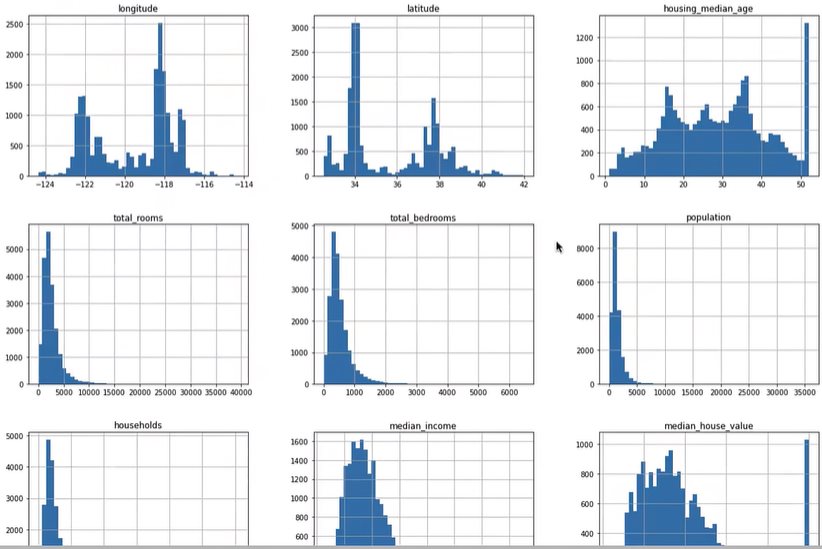 tn2>我们可以看到`housing_median_age`与`median_house_value`最后的数据有点问题,是需要将它处理掉的,一般不会升那么高。 这个以后我学了后面补起。 创建测试数据集 ------------ tn2>通常是随机数据集中20%左右的数据作为测试集,那么80%就是数据集。 `sklearn.model_selection` 的 `train_test_split` 函数。 接下来我们通过代码来创建测试集和数据集。 ```python from sklearn.model_selection import train_test_split # test_size 测试集大小20% # random_state 随机数生成器设置随机种子 train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42) ``` tn2>然后我们通过房价(`median_income`)进行数据拆分,通过参数`bins`来分割,每隔`1.5`万美金进行分类分5次最后一次为6万到最大值,这个值命名为`income_cat`。 ```python import numpy as np housing["income_cat"] = pd.cut(housing["median_income"], bins=[0., 1.5, 3.0, 4.5, 6., np.inf], labels=[1, 2, 3, 4, 5]) ``` tn2>通过head方法查看是否创建成功。 ```python housing.head() ``` 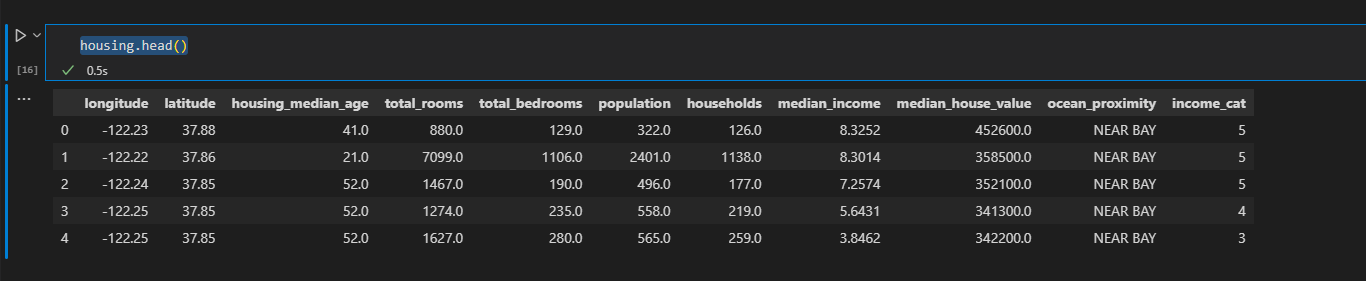 tn2>ok!最后一列是有的。 然后我们看一下这一列的直方图。 ```python housing['income_cat'].hist() ``` 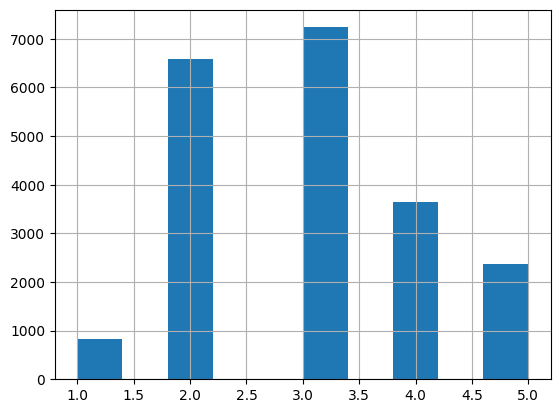 tn2>接下来我们每层都进行抽样,20%作为测试集和80%作为训练数据集。 ```python # StratifiedShuffleSplit 是用于分层抽样 from sklearn.model_selection import StratifiedShuffleSplit split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42) # 以income_cat这个属性进行抽样 for train_index, test_index in split.split(housing, housing["income_cat"]): strat_train_set = housing.loc[train_index] strat_test_set = housing.loc[test_index] # 测试方面 strat_test_set["income_cat"].value_counts() / len(strat_test_set) ``` 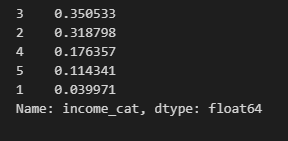 tn2>最后清理数据。 ```python for set_ in (strat_train_set, strat_test_set): set_.drop("income_cat", axis=1, inplace=True) ```

