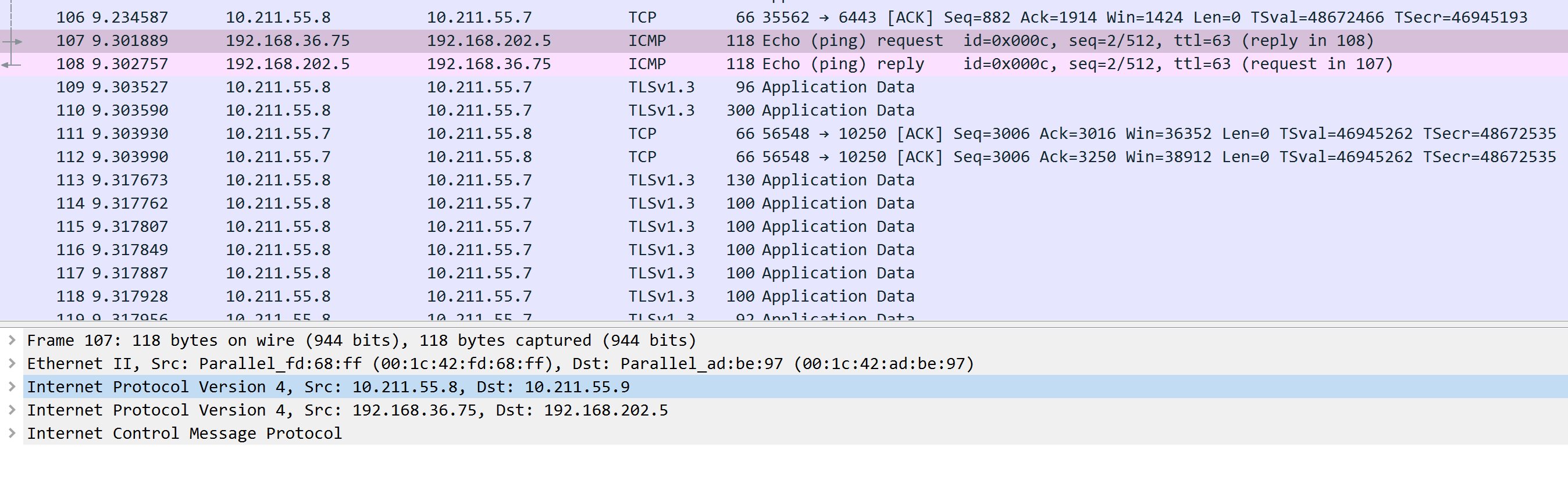
Kubernetes Calico IPIP 电脑版发表于:2022/11/1 17:32  >#Kubernetes Calico IPIP [TOC] ## Calico简介 tn2>1.Calico是一个纯3层的数据中心网络方案,而且无缝集成像OpenStack这种Iaas云架构,能够提供可控的VM、容器、裸机之间的IP通信。 2.Calico不使用重叠网络比如flannel和libnetwork重叠网络驱动,它是一个纯3层的方案,使用虚拟路由代替虚拟交换,每一台虚拟路由通过BGP协议传播可达信息(路由)到剩余的数据中心去。 3.Calico在每一个计算节点利用Linux Kernel实现了一个高效的vRouter来负责数据转发,而每一个vRouter通过BGP协议负责把自己运行的workload的路由信息向整个Calico网络内传播,在小规模的部署情况下可以直接互联,大规模的部署下可以通过制定的BGP route reflector来解决。 4.Calico节点组网可以直接利用数据中心的网络结构(L2或L3),不需要额外的NAT,隧道或者Overlay Network。 5.Calico基于iptables还提供了丰富的灵活网络Policy,保证通过各个节点上的ACLs来提供Workload的多租户隔离、安全组以及其他可达性限制功能。  ## Calico 安装 >### 先决条件 tn2>确保您的linux主机满足以下要求: x86-64、arm64、ppc64le或s390x处理器 2CPU 2GB内存 10GB可用磁盘空间 RedHat Enterprise Linux 7.x+、CentOS 7.x+,Ubuntu 16.04+或Debian 9.x+ 确保Calico可以管理主机上的cali和tunel接口。如果主机上存在NetworkManager,请参阅配置<a href="https://projectcalico.docs.tigera.io/maintenance/troubleshoot/troubleshooting#configure-networkmanager">NetworkManager</a>。 并且有一个Kubernetes的集群。 最好确保Pod的网络段为`192.168.0.0/16`。 >### 开始安装 tn2>安装Tigera Calico操作员和自定义资源定义。 ```bash kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.24.3/manifests/tigera-operator.yaml ``` tn2>通过创建必要的自定义资源来安装Calico。有关此清单中可用配置选项的详细信息,<a href="https://projectcalico.docs.tigera.io/reference/installation/api">请参阅安装参考</a>。 ```bash kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.24.3/manifests/custom-resources.yaml ``` tn>注意:如果你的Pod网段不是`192.168.0.0/16`,请修改这个文件的网络段后再安装,如下图所示: 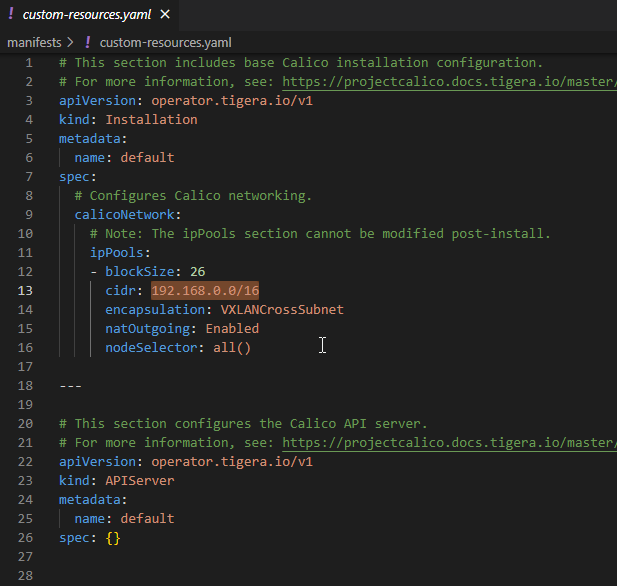 tn2>使用以下命令确认所有pod都在运行。 ```bash watch kubectl get pods -n calico-system ``` tn2>等待所有的Pod的状态都为Running。 >### 第二种方式安装 ```bash curl https://raw.githubusercontent.com/projectcalico/calico/v3.24.3/manifests/calico.yaml -O vim calico.yaml # 修改Pod网络段 kubectl apply -f calico.yaml ``` >### 相关Pod的讲解 tn2>我们可以看到calico有Calico-kube-controllers和canal  tn2>关于calico-kube-controllers的作用如下: 1.识别影响路由变化,且包含多个控制器。 2.网络策略,被用作编写iptables或ipvs来执行网络访问的能力。 3.观察pod的变化,比如标签的变化 4.名称空间的变化 5.SA 设置Calico的配置文件 6.通知节点路由变化 ## Calico 客户端安装 tn2>将calicoctl二进制文件下载到可以访问Kubernetes的Linux主机上。 ```bash wget https://github.com/projectcalico/calicoctl/releases/download/v3.20.0/calicoctl chmod +x calicoctl sudo mv calicoctl /usr/local/bin/ ``` tn2>配置calicoctl以访问Kubernetes。 ```bash export KUBECONFIG=/root/.kube/kubeconfig export DATASTORE_TYPE=kubernetes ``` tn2>测试 ```bash # --allow-version-mismatch该参数表示可以不同版本 calicoctl --allow-version-mismatch version calicoctl version ``` 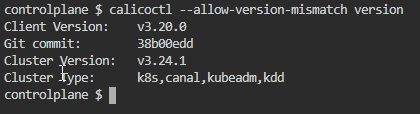 tn2>我们可以通过如下的命令获取workloadEndpoint的信息,里面信息非常丰富。 ```bash calicoctl --allow-version-mismatch get workloadEndpoint -o wide -A ``` tn2>我们从图中可以看到: Name:包含了节点信息、pod名称以及网卡信息 WORKLOAD: 是Pod的信息。 Node:节点名称。 NETWORKS:IP地址信息。 INTERFACE:表示veth虚拟网卡对在root网络名称空间下的网卡名称。   ## Calico 结构 tn2>Calico主要的结构由Felix组件、Confd组件、BGP RR、Bird(BGP客户端)组成。它们的关系如下图所示。 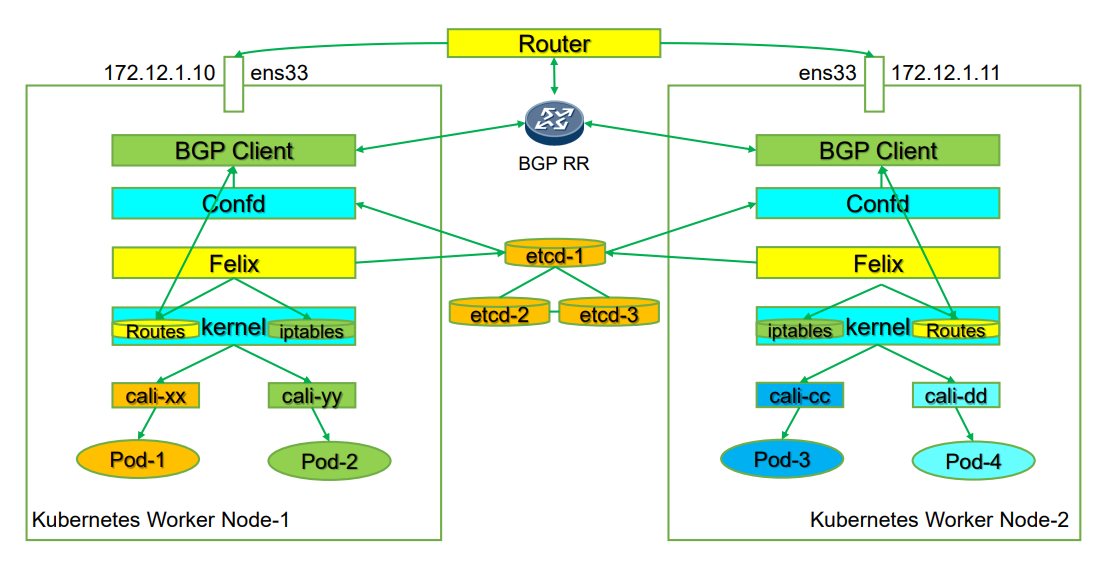 >### Felix tn2>Felix是calico的核心组件,运行在每个节点上。主要的功能有接口管理、路由规则、ACL规则和状态报告。 | 功能 | 描述 | | ------------ | ------------ | | 接口管理 | Felix为内核编写一些接口信息,以便让内核能正确的处理主机endpoint的流量。特别是主机之间的ARP请求和处理ip转发。 | | 路由规则 | Felix负责主机之间路由信息写到Linux内核的FIB(Forwarding Information Base)转发信息库,保证数据包可以在主机之间相互转发。 | | ACL规则 | Felix负责将ACL策略写入到Linux内核中,保证主机endpoint的为有效流量不能绕过calico的安全措施。 | | 状态报告 | Felix负责提供关于网络健康状况的数据。特别是,它报告配置主机时出现的错误和问题。这些数据被写入etcd,使其对网络的其他组件和操作人员可见。 | tn2>部署完成,我们可以看到calico-node的pod会在每一个节点上运行,在这里运行的node中就包含了Felix,由于该pod上面的工具被限制很多,我们可以在此节点上的通过`ps -aux | grep felix`进行查看是否运行。   >### Etcd tn2>保证数据一致性的数据库,存储集群中节点的所有路由信息。为保证数据的可靠和容错建议至少三个以上etcd节点。 >### Bird tn2>BGP客户端,Calico在每个节点上的都会部署一个BGP客户端,它的作用是将Felix的路由信息读入内核,并通过BGP协议在集群中分发。当Felix将路由插入到Linux内核FIB中时,BGP客户端将获取这些路由并将它们分发到部署中的其他节点。这可以确保在部署时有效地路由流量。 (简单来讲写入内核,分发路由) 可通过`ps -aux | grep bird`来查看。  >### BGP Router Reflector tn2>大型网络仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,所有节点需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数。 >### confd tn2>confd 监听 etcd 的数据,用来更新 bird 的配置文件,并重新启动 bird 进程让它加载最新的配置文件。confd的工作目录是 /etc/calico/confd,里面有三个目录: | 目录 | 描述 | | ------------ | ------------ | | conf.d | confd 需要读取的配置文件,每个配置文件告诉 confd 模板文件在什么,最终生成的文件应该放在什么地方,更新时要执行哪些操作等 | | config | 生成的配置文件最终放的目录 | | templates | 模板文件,里面包括了很多变量占位符,最终会替换成 etcd 中具体的数据 | tn2>可通过`ps -aux | grep confd`来查看。  tn2>关于文件我们可以看看有哪些。 ```bash kubectl exec -it calico-node-f7ldv -n kube-system /bin/bash cd /etc/calico/confd ```  ### 回顾IPIP模式 tn2>IPIP模式是将一个IP数据包套在另一个IP包里,使用到了Linux提供的隧道技术。可以理解为一个基于IP层的网桥,将两个本不通的网络通过点对点连接起来。 在各Node的路由之间做一个tunnel。 缺点:IPIP 模式也会因为 IPIP 隧道封包解包损失大量的性能,与 VXLAN 类似。 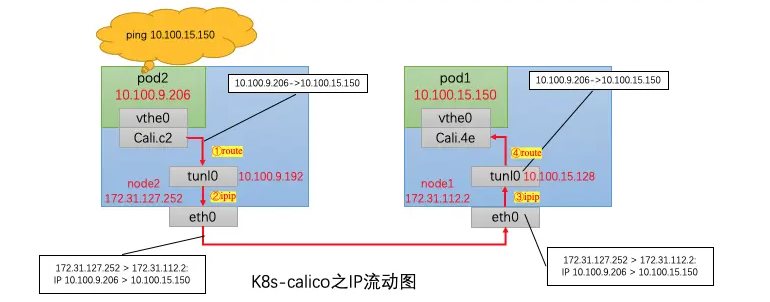 tn2>我们可以简单实践一下,大致如下图所示: 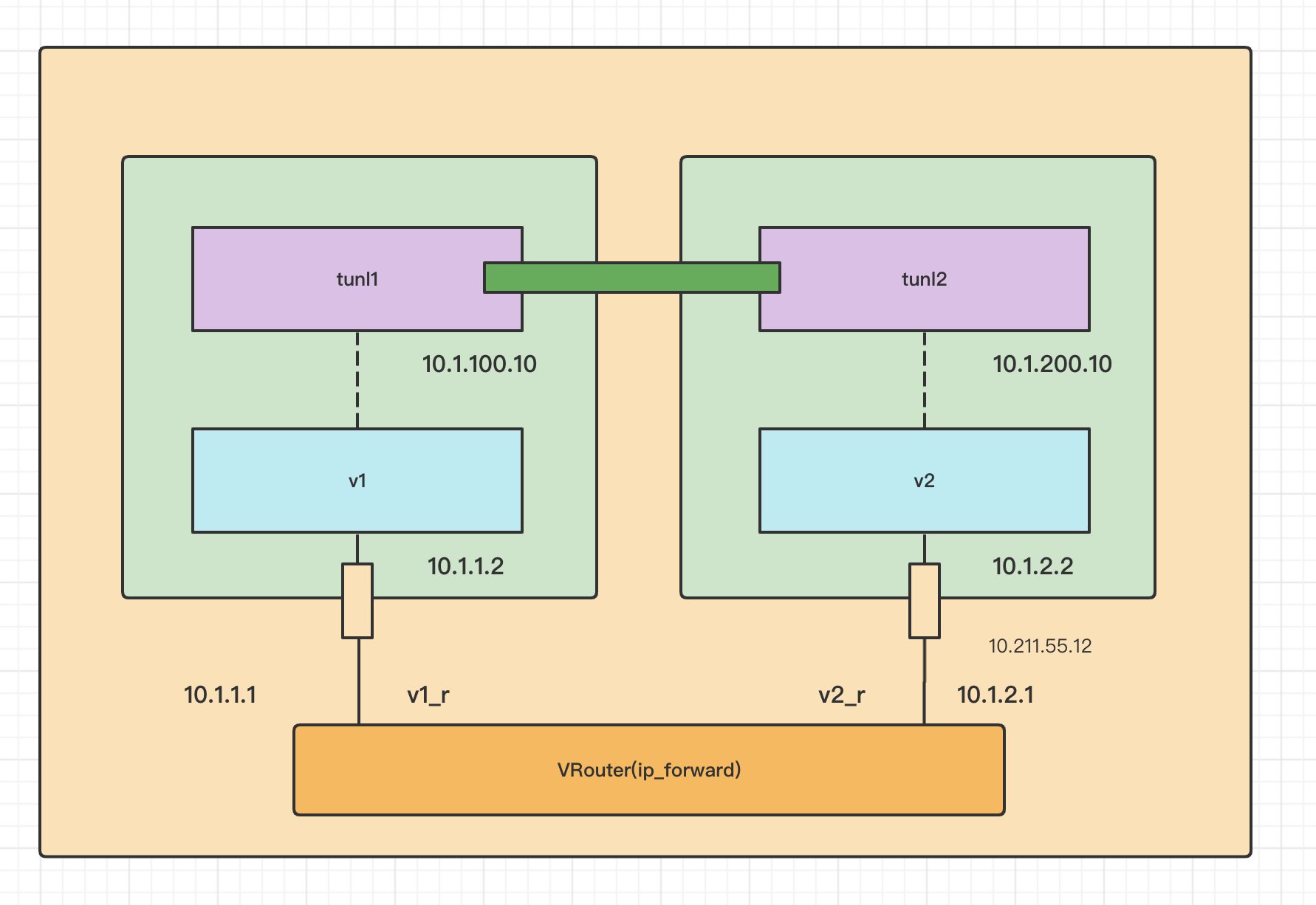 ```bash apt install net-tools -y # 创建两个 namespace ip netns add ns1 ip netns add ns2 # 创建两对 veth-pair ,一端分别挂在两个 namespace 中 ip link add v1 type veth peer name v1_r ip link add v2 type veth peer name v2_r ip link set v1 netns ns1 ip link set v2 netns ns2 # 分别给两对 veth-pair 端点配上IP并启用: ip a a 10.1.1.1/24 dev v1_r ip l s v1_r up ip a a 10.1.2.1/24 dev v2_r ip l s v2_r up ip netns exec ns1 ip a a 10.1.1.2/24 dev v1 ip netns exec ns1 ip l s v1 up ip netns exec ns2 ip a a 10.1.2.2/24 dev v2 ip netns exec ns2 ip l s v2 up # 开启环卫口 ip netns exec ns1 ip l s lo up ip netns exec ns2 ip l s lo up # 添加路由: ip netns exec ns1 route add -net 10.1.2.0 netmask 255.255.255.0 gw 10.1.1.1 ip netns exec ns2 route add -net 10.1.1.0 netmask 255.255.255.0 gw 10.1.2.1 # 修改内核转发: echo 1 > /proc/sys/net/ipv4/ip_forward # 加载IPIP模块 modinfo ipip modprobe ipip ip netns exec ns1 modprobe ipip ip netns exec ns2 modprobe ipip # 测试 ip netns exec ns1 ping 10.1.2.1 # 配置tunl1和tunl2 ip netns exec ns1 ip tunnel add tunl1 mode ipip local 10.1.1.2 remote 10.1.2.2 ip netns exec ns2 ip tunnel add tunl2 mode ipip local 10.1.2.2 remote 10.1.1.2 ip netns exec ns1 ip l s tunl1 up ip netns exec ns2 ip l s tunl2 up ip netns exec ns1 ip a a 10.1.100.10/24 peer 10.1.200.10/24 dev tunl1 ip netns exec ns2 ip a a 10.1.200.10/24 peer 10.1.100.10/24 dev tunl2 ``` 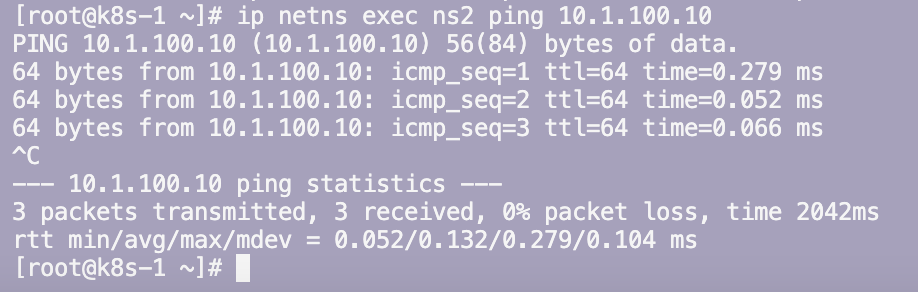 ## 设置IPIP模式 tn>使用IPIP模式Vxlan模式就不可以使用,反之同理。 tn2>首先我们查询IPPool,并编辑开启IPIP模式。 ```bash kubectl get IPPool ```  ```bash kubectl edit IPPool default-ipv4-ippool # 将spec.ipipMode: Never 改成 Always ```  tn2>参数意义如下: | 参数 | 描述 | | ------------ | ------------ | | cidr | IP池,地址范围。 | | blockSize | 定从主IP池CIDR分配每个节点IP块时要使用的CIDR预取长度。26指的是IPV4(多出2位为:00、01、11、10),122指的是IPV6 | | ipipModel | 是否开启这个模式。 | | natOutgoing | 是否开启对外部网络的访问。指定是为传出流量启用还是禁用NAT。默认启用。 | | nodeSelector | 选择运行的节点 | | vxlanMode | 是否开启vxlan模式。 | ## Calico 路由表 IPIP 模式 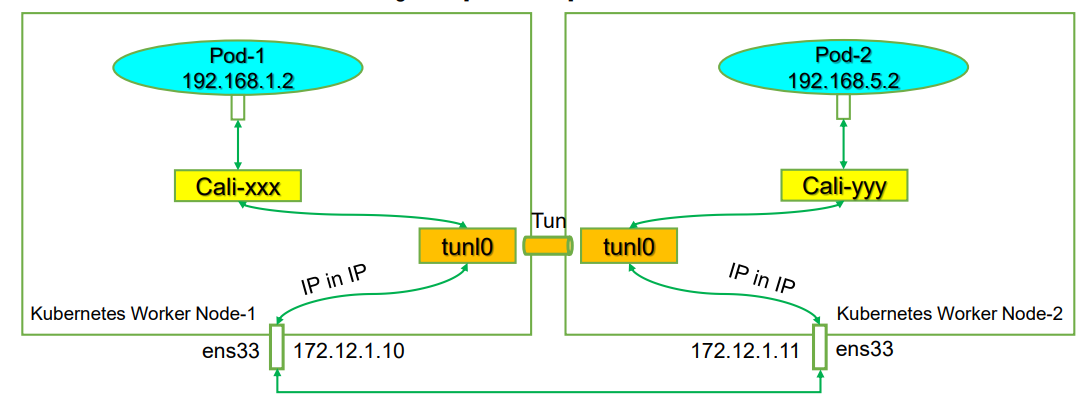 tn2>如果集群节点之间不是二层连通,而是三层连通,需要打开calico的ipip模式,其通信流程如下: ```mermaid graph LR Pod-1 --> master-calixxx master-calixxx --> master-tunl0 master-tunl0 --> master-ens33 master-ens33 --> node01-ens33 node01-ens33 --> node01-tunl0 node01-tunl0 --> node01-calixxx node01-calixxx --> Pod-2 ``` tn2>1.Pod1访问Pod2时,ip包会出现在calixxx 2.根据Pod1宿主机中的路由规则中的下一跳,使用tunl0设备将ip包发送到Pod2的宿主机 3.tunl0是一种ip隧道设备,当ip包进入该设备后,会被Linux中的ipip驱动将该ip包直接封装在宿主机网络的ip包中,然后发送到Pod2的宿主机 4.进入Pod2的宿主机后,该ip包会由ipip驱动解封装,获取原始的ip包,然后根据c2宿主机中路由规则发送到calixxx。 5.最后发送到Pod2上 ## IPIP实践 tn2>首先我们启动两个Pod。 ```bash cat << EOF > cni.yaml apiVersion: apps/v1 kind: Deployment metadata: name: cni spec: selector: matchLabels: app: cni replicas: 2 template: metadata: labels: app: cni spec: containers: - name: cni image: burlyluo/nettoolbox EOF ``` ```bash kubectl apply -f cni.yaml kubectl get pod -w kubectl get pod -o wide ```  tn2>我们可以看到`cni-68878bb9bd-g2kb5`Pod中的eth0网卡的地址为`192.168.36.73`,也可以通过如下命令进行查看。 ```bash kubectl exec -it cni-68878bb9bd-g2kb5 -- ifconfig ``` 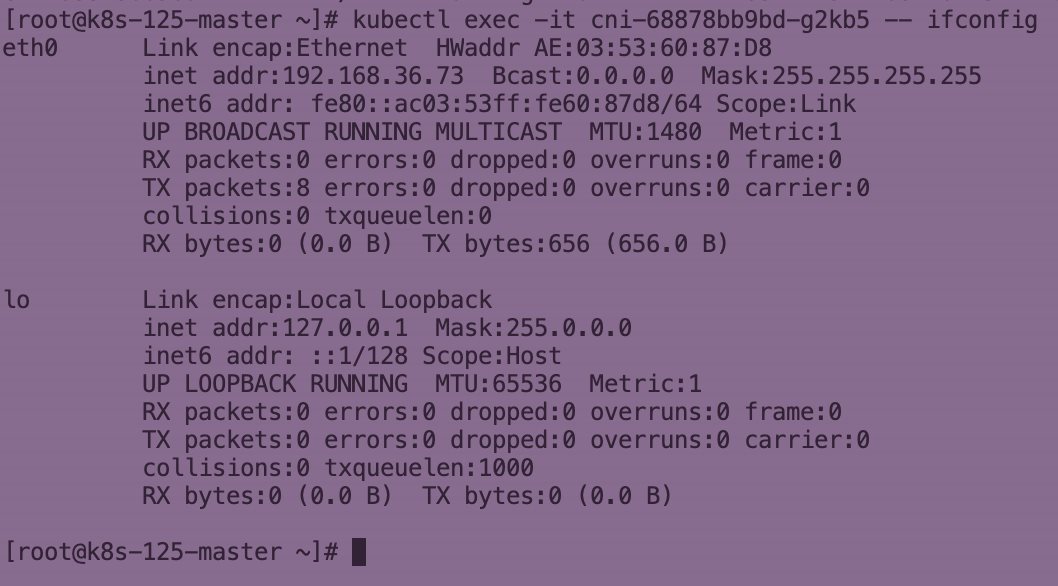 tn2>我们可以通过calicoctl查询wep的方式获取到所对应的接口地址。 ```bash calicoctl get wep calicoctl --allow-version-mismatch get wep ```  tn2>从上图我们可以看到cni-68878bb9bd-g2kb5对应的是k8s-125-node1工作节点上的cali9390782c38f接口,那么这个cali9390782c38f是怎么找到的呢?是通过ethtool找到peer的index,再从ip a里面通过下标去找,找到的。 ```bash kubectl exec -it cni-68878bb9bd-g2kb5 -- ethtool -S eth0 # 到node1节点上去执行 ip a ```   tn2>我们在所有的主机上看到的calico peer的地址都为`ee:ee:ee:ee:ee:ee`这是一个固定的特殊地址,这是因为Calico只关心三层的IP地址,根本不关心二层MAC地址。 再来我们分析一下pod中的路由表 ```bash kubectl exec -it cni-68878bb9bd-g2kb5 -- route -n ```  tn2>第一条路由的意思是:目的地址为`0.0.0.0`网关地址为`169.254.1.1`,子网是`0.0.0.0`说明是默认路由因为范围很大嘛(0.0.0.0-255.255.255.255)Flags标识为UG,U表示启用,G表示网关的,从eth0网卡发出去的。<br/> 第二条路由:目的地址到`169.254.1.1`网关为`0.0.0.0`,子网为`255.255.255.255`说明的没有更多的子网32位,那么所对应的是准确的主机,H表示主机的意思,从eth0网卡发出。<br/> Tag意义展示如下: 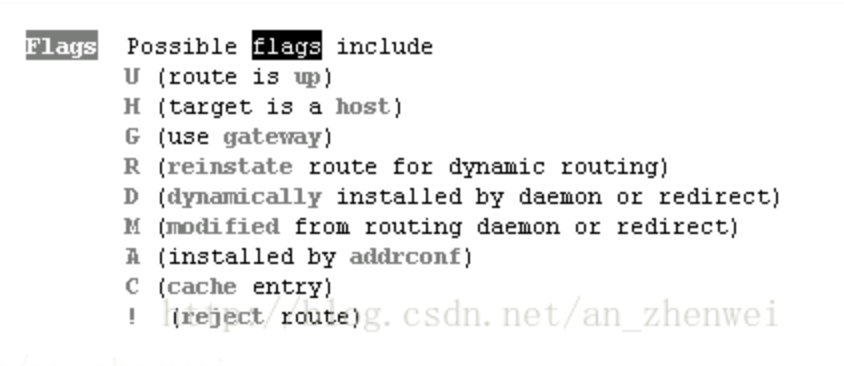 >### ARP Proxy 回顾 tn>那你说这个`169.254.1.1`网关我也没用到过,为什么每个Pod都有呢?有什么作用呢?有什么好处呢? 比如发送一个`ARP`我们知道在发送一个ARP包需要具备4个基本条件:自己的IP(`192.168.36.73`),自己的MAC目标(`AE:03:53:60:87:D8`),目标IP(举例`114.114.114.114`),目标MAC(`???????`)。  tn>你说不知道目标MAC的地址在哪儿?这个时候ARP包会从当前网络名称空间到主机网络名称空间下,在主机下的虚拟网卡对(也就是我们的`cali9390782c38f`)进行应答,应答之后就是将报文中的MAC地址写成自己的MAC地址(`ee:ee:ee:ee:ee:ee`),容器后续的报文IP还是目的IP(`114.114.114.114`)。 后续所有的请求都会先发到主机网络名称空间下,然后在根具IP再做转发。 我们可以简单测试一下。 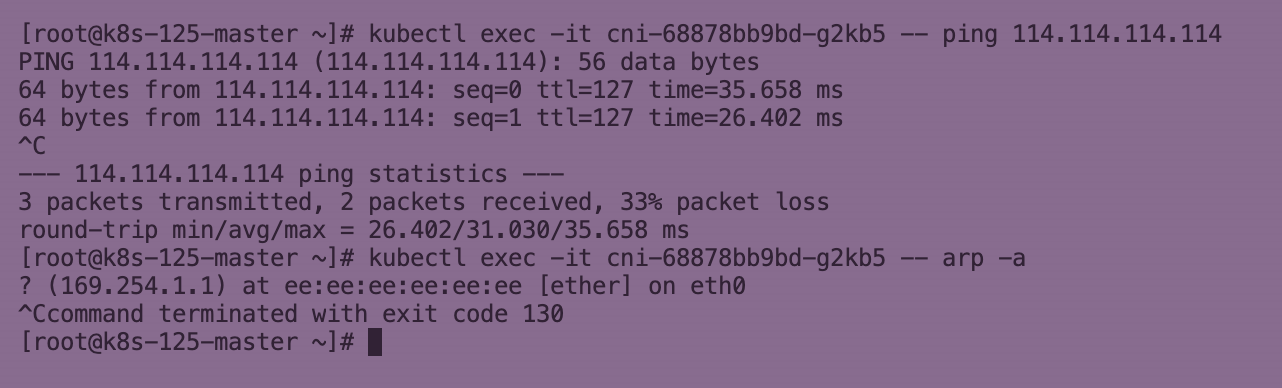 tn2>总之主机不管ARP的请求,把自己的MAC给其他名称空间的ARP请求作为应答的行为叫做`ARP Proxy`。 有兴趣的可回顾我的早期博客:https://www.tnblog.net/hb/article/details/7272#Proxy%20ARP >### 同节点IPIP的Pod通信 tn2>由于刚刚跑的pod是不同节点的,这里我们先跑一个同节点的Pod,如下图所示。 两个都在node2上。 ```bash kubectl run c1 --image=burlyluo/nettoolbox kubectl get pod -o wide ```  | Pod名称 | Pod IP地址 | 节点 | 主机上接口名 | pod的网卡 | | ------------ | ------------ | ------------ | ------------ | ------------ | | c1 | 192.168.202.4/32 | k8s-125-node2 | cali6419776c3a4 | eth0 | | cni-68878bb9bd-kvzrk | 192.168.202.3/32 | k8s-125-node2 | cali116394cbb48 | eth0 | tn2>然后我们通过c1来`ping 192.168.202.3`试试看,可以ping得通。可它是怎么走的呢? 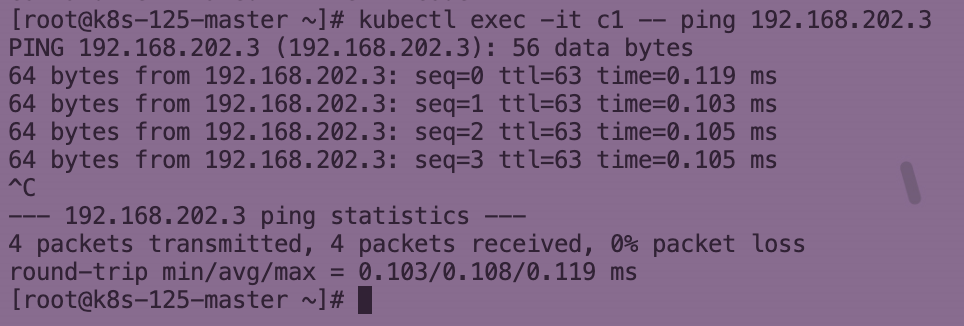 tn2>首先通过发送ARP Proxy,然后发送包到主机,主机查路由表,发送到cali116394cbb48,然后cni-68878bb9bd-kvzrk接收到包。 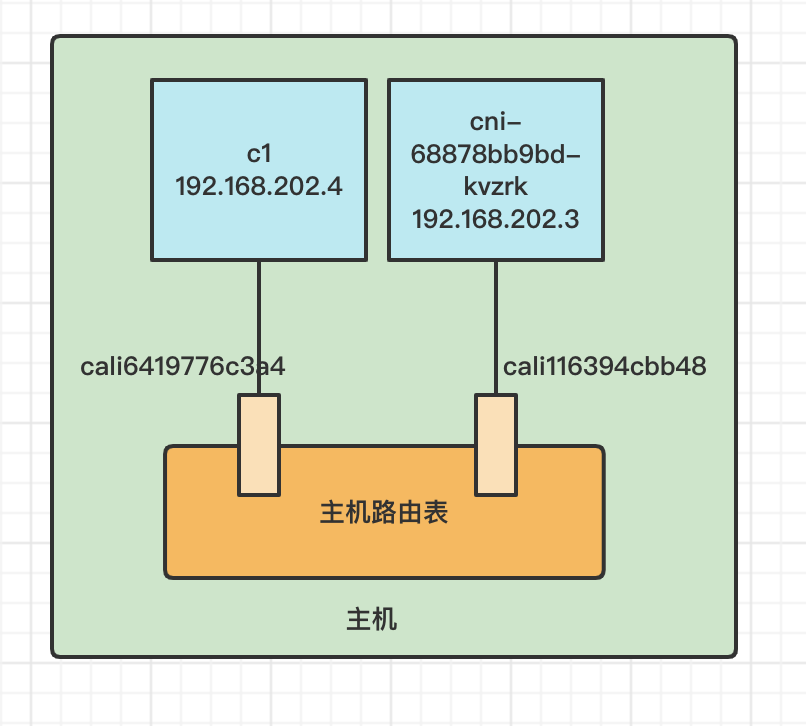 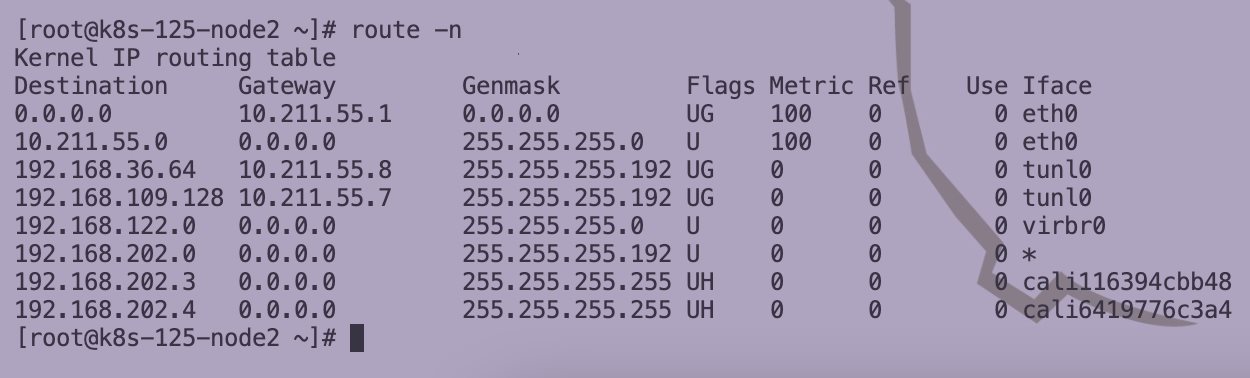 tn2>这里主机是不是就相当于路由器的作用。 那么为什么不用说用的是交换机呢?因为交换机它在发包的时候会去问每一个连接到交换机的主机,这会影响性能。 ## 跨节点通信 tn2>这里我们准备了两个不同节点的Pod名为cni。  tn2>如果从192.168.36.75 ping 192.168.202.5 ,那么第一层原ip地址是节点的地址,所以: 原IP为node1的IP,目标IP为node2的IP,原MAC为node1 mac,目标MAC为node2 mac。 再来我们看node1的路由规则: 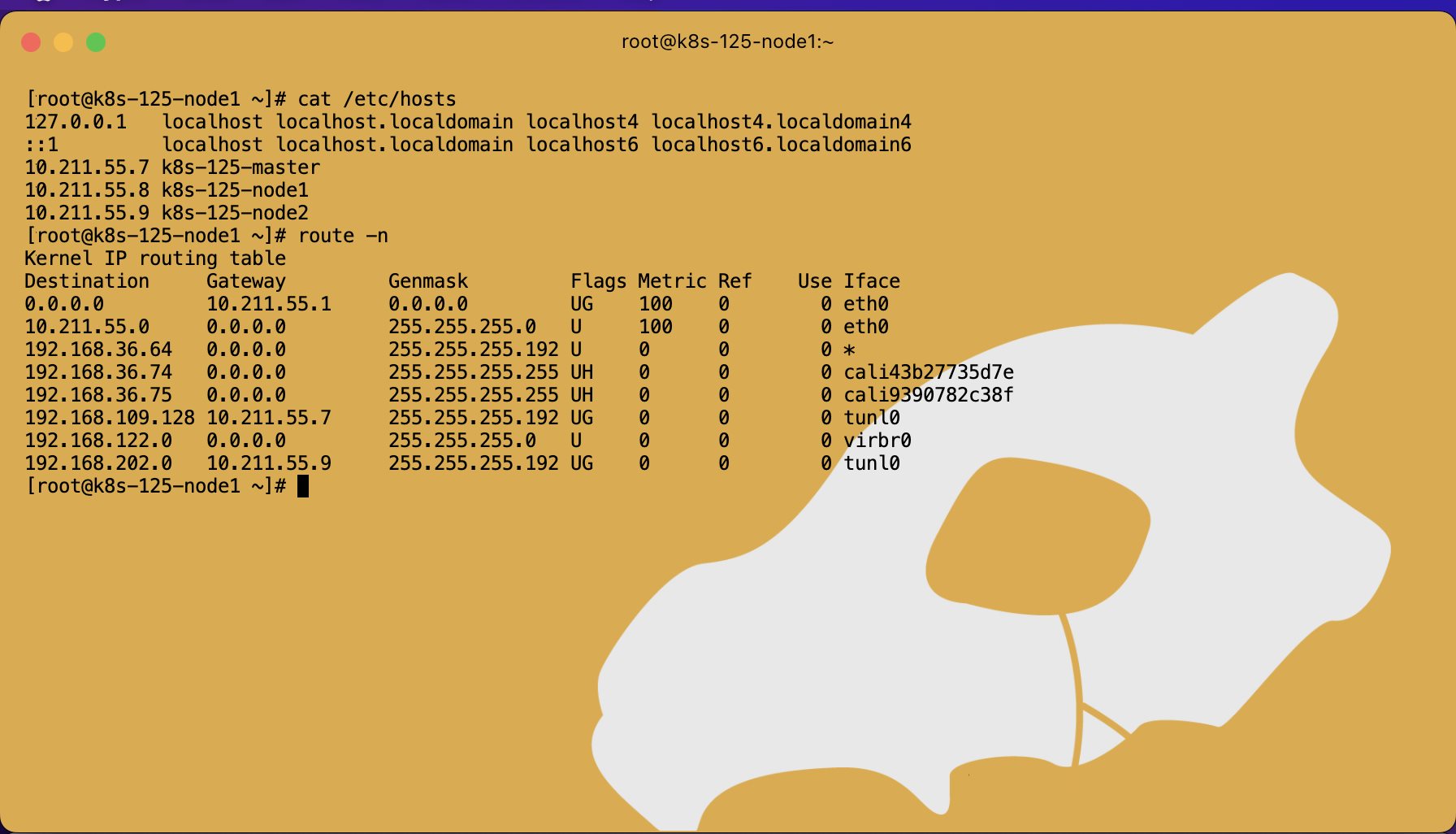 ```bash 192.168.202.0 10.211.55.9 255.255.255.192 UG 0 0 0 tunl0 ``` tn2>我们可以看到要去`192.168.202.5`走的是这条路由,网关是`10.211.55.9`也就是下一跳,`255.255.255.192`就是26位(在128上加的),从tunl0接口出去的。 (执行下面命令给各位抓个包) ```bash # 主机执行 kubectl exec -it cni-68878bb9bd-g2kb5 -- ping -c 3 192.168.202.5 # Node1 执行抓包 tcpdump -pne -i eth0 -w ipip.cap ```