BGP RR路由反射与Calico的初探 电脑版发表于:2022/10/11 19:44  >#BGP RR路由反射与Calico的初探 [TOC] ## BGP RR路由反射介绍 tn2>由于IBGP水平分割的存在,为了保证所有的BGP路由器都能学习到完整的BGP路由,就必须在AS内实现IBGP全互联,这就导致AS内部需要维护大量的BGP连接,从而影响网络性能,路由反射器(Route Reflector,RR)可以**放宽**水平分割原则,解决该问题。<br/> 为保证IBGP对等体之间的连通性,需要在IBGP对等体之间建立全连接关系。假设在一个AS内部有n台设备,那么建立的IBGP连接数就为n(n-1)/2。当设备数目很多时,设备配置将十分复杂,而且配置后网络资源和CPU资源的消耗都很大。在IBGP对等体间使用路由反射器可以解决以上问题。 tn>简单来讲一个区域内所有人都是所有人的对等体,那么所有人都需要再除自己之外的所有人进行获取路由。而路由反射器相当于一个主管告诉下面所有的客户端你们都不需要去每个每个去问了我去获取所有的连接路由的路由表(不管是IBGP、EBGP、非Client的IBGP对等体),再把这些给连接的路由器,相对于这个区域下形成主从关系。 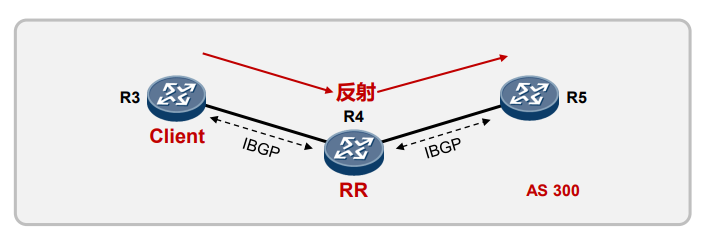 >### RR在接收BGP路由时 tn2>1.如果该路由学习自非Client IBGP对等体,则反射给自己所有的Client。 举例:下图R3为非Client时将反射给R2的Client。 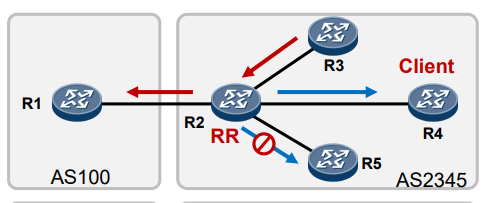 tn2>如果路由学习自Client,则反射给所有非Client IBGP对等体和除了该Client之外的所有Client。 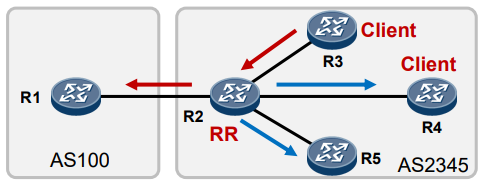 tn2>如果路由学习自己EBGP对等体,则发送给所有Client和非Client IBGP对等体。 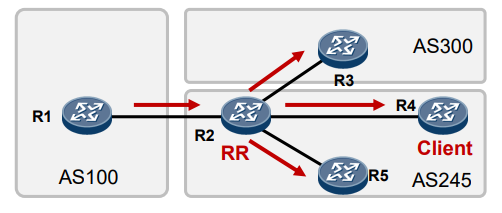 | 名词 | 描述 | | ------------ | ------------ | |路由反射器RR(Route Reflector)|允许把从IBGP对等体学到的路由反射到其他IBGP对等体的BGP设备,类似OSPF网络中的DR。| |客户机(Client)|与RR形成反射邻居关系的IBGP设备。在AS内部客户机只需要与RR直连。| |非客户机(Non-Client)|既不是RR也不是客户机的IBGP设备。在AS内部非客户机与RR之间,以及所有的非客户机之间仍然必须建立全连接关系。| |始发者(Originator)|在AS内部始发路由的设备。Originator_ID属性用于防止集群内产生路由环路。| |集群(Cluster)|路由反射器及其客户机的集合。Cluster_List 属性用于防止集群间产生路由环路。| ## RR反射简单Demo 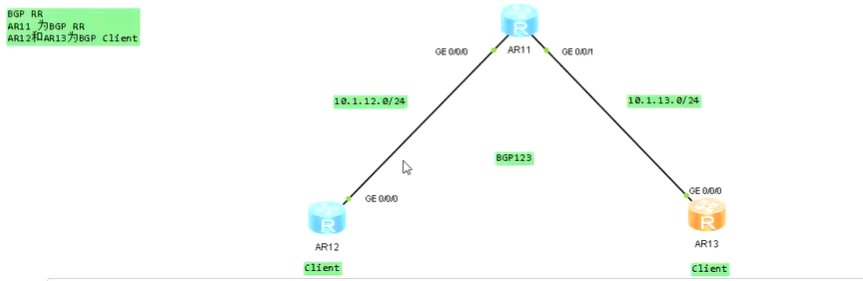 tn2>基本配置 ```bash system-view sysname AR11 int g0/0/0 ip a 10.1.12.11 24 int g0/0/1 ip a 10.1.13.11 24 int L 0 ip a 1.1.1.1 32 dis ip int B q ``` ```bash system-view sysname AR12 int g0/0/0 ip a 10.1.12.12 24 int L 0 ip a 2.2.2.2 32 dis ip int B q ``` ```bash system-view sysname AR13 int g0/0/0 ip a 10.1.13.13 24 int L 0 ip a 3.3.3.3 32 dis ip int B q ``` tn2>配置ospf ```bash ospf router-id 1.1.1.1 A 0 network 0.0.0.0 255.255.255.255 dis this q q ``` ```bash ospf router-id 2.2.2.2 A 0 network 0.0.0.0 255.255.255.255 dis this q q ``` ```bash ospf router-id 3.3.3.3 A 0 network 0.0.0.0 255.255.255.255 dis this dis ospf peer b q q ``` tn2>配置BGP ```bash bgp 123 router-id 1.1.1.1 peer 2.2.2.2 as-number 123 peer 2.2.2.2 connect-interface L0 peer 3.3.3.3 as-number 123 peer 3.3.3.3 connect-interface L0 # 以AR11为中心设置邻居AR12为我的客户端 peer 2.2.2.2 reflect-client # 以AR11为中心设置邻居AR13为我的客户端 peer 3.3.3.3 reflect-client ``` ```bash bgp 123 router-id 2.2.2.2 peer 1.1.1.1 as-number 123 peer 1.1.1.1 connect-interface L0 ``` ```bash bgp 123 router-id 3.3.3.3 peer 1.1.1.1 as-number 123 peer 1.1.1.1 connect-interface L0 dis this ``` tn2>这样就完成了AR11把AR12和AR13当成它的客户端了。 接下来我们通过配置AR13来进行验证反射路由,创建一个L1的口IP为`33.33.33.33/32`,然后在bgp中进行宣告。 ```bash int L1 ip 33.33.33.33 32 q bgp 123 router-id 3.3.3.3 network 33.33.33.33 32 dis bgp routing-table ``` tn2>然后我们在AR12中查看发现它是映射成功了的。 ```bash bgp 123 dis bgp routing-table q q ``` tn2>接下来我们关闭AR11对AR12的客户端认证,再刷新AR12的BGP看能否可以学习到。 ```bash # AR11 bgp 123 undo peer 2.2.2.2 reflect-client dis this ``` ```bash # AR12 refresh bgp external import dis bgp routing-table ``` tn2>我们发现它仍然存在。 放图1 tn2>如果我们再再AR13上添加一个新的口子,由于AR11不再认为AR12为客户端,AR12将学习不到了。 ```bash # AR13 int L2 ip 99.99.99.99 32 q bgp 123 router-id 3.3.3.3 network 99.99.99.99 32 dis bgp routing-table ``` ```bash # AR12 dis bgp routing-table ``` tn2>AR11清理AR13认证的客户端后,AR12以前学习的将丢失。 ```bash # AR11 bgp 123 undo peer 3.3.3.3 reflect-client q q refresh bgp external import ``` ```bash # AR12 dis bgp routing-table ``` tn2>在完成这些之后,我们知道通过RR反射的方式可以获取同一区域下的路由的路由表,但如果AR11挂了AR12是不是就学习不到其他路由器的存在的(其他路由亦是如此),所以我们可以建立一个或多个RR路由,来保证高可用的问题。 Calico为优化k8s网络基于BGP由此诞生。 ## Calico的诞生 tn2>calico是一个比较有趣的虚拟网络解决方案,它完全利用路由规则实现动态组网,通过BGP协议通告路由。 calico的优点:<br/> endpoints组成的网络是单纯的三层网络,报文的流向完全通过路由规则控制,没有overlay等额外开销; calico的endpoint可以漂移,并且实现了acl。 calico的缺点:<br/> 路由的数目与容器数目相同,非常容易超过路由器、三层交换、甚至node的处理能力,从而限制了整个网络的扩张; calico的每个node上会设置大量(海量)的iptables规则、路由,运维、排障难度大; calico的原理决定了它不可能支持VPC,容器只能从calico设置的网段中获取ip; calico目前的实现没有流量控制的功能,会出现少数容器抢占node多数带宽的情况; ## calico设计的BGP网络 tn2>1.AS per rack: 每个rack(机架)组成一个AS,每个rack的TOR交换机与核心交换机组成一个AS 2.AS per server: 每个node做为一个AS,TOR交换机组成一个transit AS >### AS per rack tn2>1.一个机架作为一个AS,分配一个AS号,node是ibgp,TOR交换机是ebgp 2.node只与TOR交换机建立BGP连接,TOR交换机与机架上的所有node建立BGP连接 3.所有TOR交换机之间以node-to-node mesh方式建立BGP连接 <br/> TOR交换机之间可以是接入到同一个核心交换机二层可达的,也可以只是IP可达的。 TOR二层交换机: 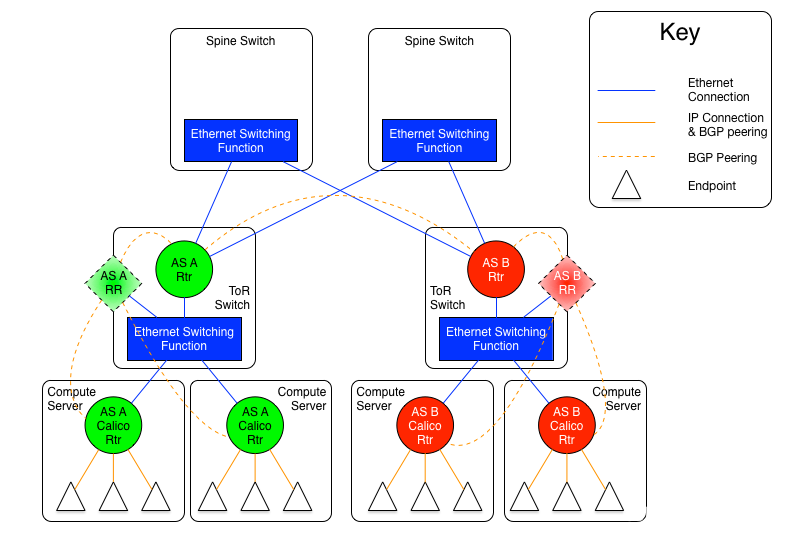 tn2>TOR三层联通: 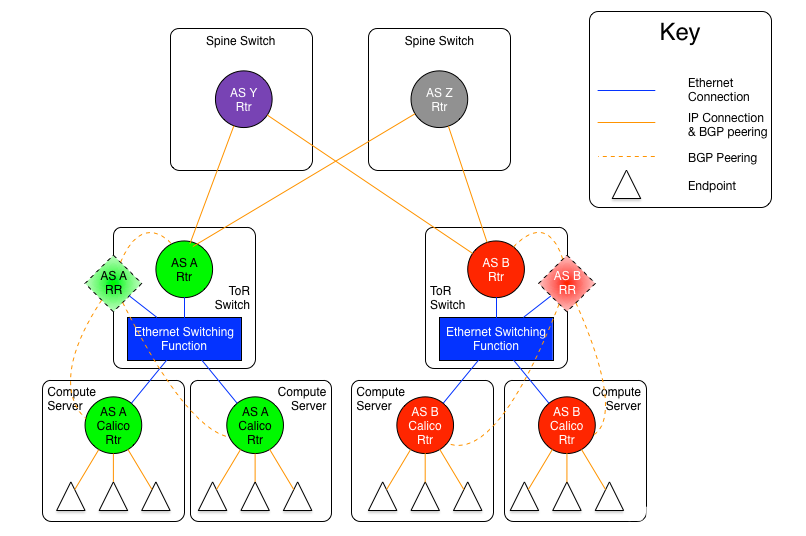 tn2>在这种方案里,每个Tor 交换机到Tor 交换机或者TOR交换机到 spine switch 的链路是EBGP对等的。那就意味着北向 tor 交换机无法使用 RR(Route Reflector)。 如果使用了2层的方式,结果就是每个Tor 交换机之间必须彼此对等(可能有上百个对等),可能会造成负载过重。 如果使用3层的方式,那么每个TOR 交换机只需要和上级的 spine switch 对等即可。虽然spine switch 下会有许多TOR 交换机,可以使用RR(如上图所示),而且绝大部分spine switch拥有比TOR交换机更好的平面控制能力,在多数环境下更易扩展。 两者的配置基本相同,只是在TOR 交换机的北向配置上有些差异。 TOR 交换机,作为EBGP router 会获取其他TOR switch 以及数据中心上的路由,重新分配到该AS下的每个计算节点上。并且会将自身AS内的所有路由信息向外通告。这就意味着,每个计算节点会将该AS内的TOR 交换机视为到外部路由的下一跳。外部路由到该AS的下一跳则是该AS下的某台计算节点 >### AS per server tn2> 1.每个TOR交换机占用一个AS,通过EBGP链接 2.每个node占用一个AS 3.node与TOR交换机交换BGP信息 4.所有的TOR交换机组成BGP mesh,交换BGP信息 <br/> 这种模式的概念同 The AS per rack 类似。在早期的 IETF draft 中,整个架构的路由和汇聚都由TOR发起。在 Calico 中,那么路由和汇聚的起始点为各计算节点。如果TOR为3层的路由器,也只能作为2机的路由和汇聚点。 因此,顺着架构往下分析,计算节点会作为AS的边界router。同 The AS per rack 的差异可从下面2张图体现。 TOR二层联通: 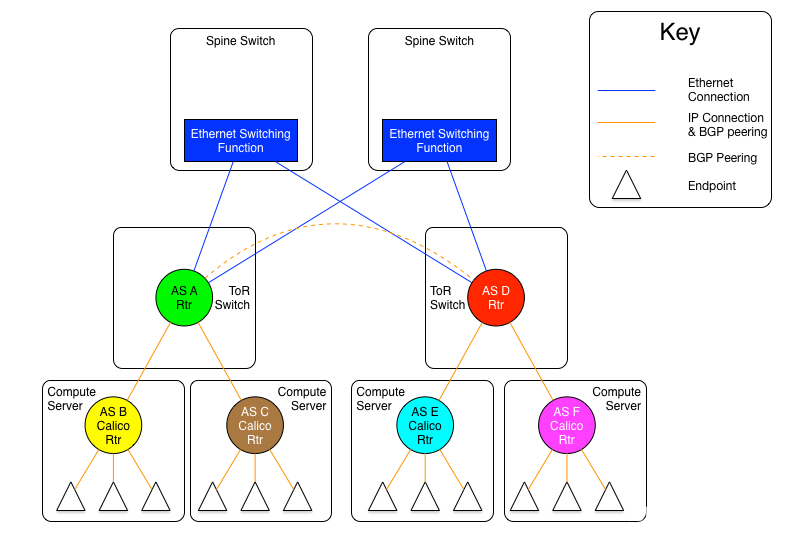 tn2>从上图不难发现,TOR 和 spine swtich 和 AS per rack 模式中一样。真正的不同在于,计算节点和TOR处于不同的AS中。为了扩展集群,需要使用4字节的AS编号(RFC 4893). 如果不使用4字节的AS编号(默认2字节),那么calico 平面中的TOR 和计算节点大约只有5000左右的私有AS编号可使用。如果采用了4字节,则会有接近92,000000私有AS编号可用。 TOR三层联通: 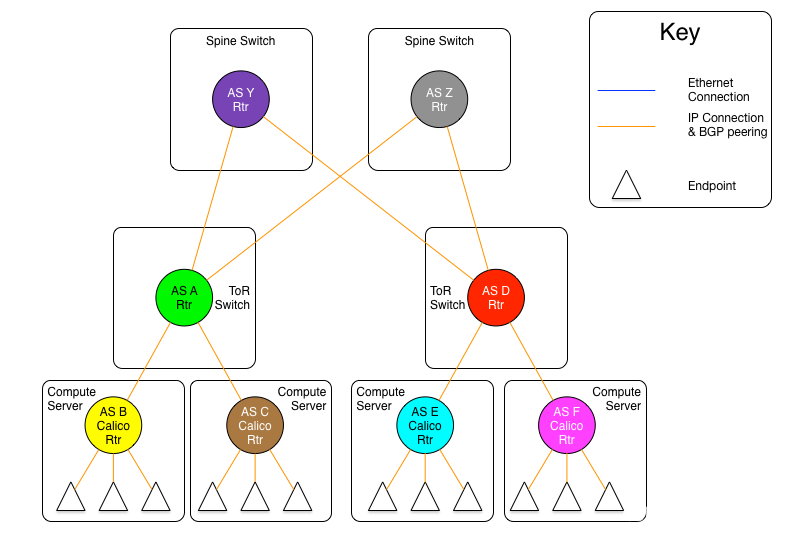 tn2>还有个差异,就是在per AS Compute Server 模式中没有 RR(Router Reflector)。所有设备都是EBGP对等的。当同一机架下的两个计算节点之间需要通信时,会通过TOR来路由。 可以将这种模式看做The AS per rack 的缩影。 >### The Downward Default model tn2>最后一种模式会显得有些不同。在上面介绍的架构中,路由器需要收集机构中所有的路由表,并使他们的AS路径保持原样。这种模式在路由阶段将AS号移除。 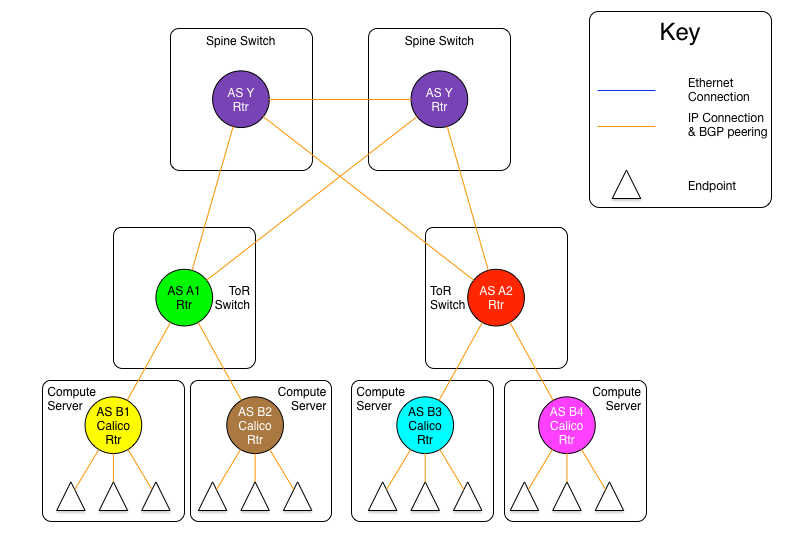 tn2>所有TOR使用一个AS,结算节点使用另一个AS的做法简化了部署(使用标准配置即可),带来的好处就是简化了TOR中的路由表。 这种模式下,每个 Router 都向上级节点汇报自己的路由信息(vRouter –> TOR –> spine switch)。however, 作为回应,上级节点仅仅返回一条默认路由。在这种情况下,vRouter 只有本机Endpoint的路由以及到TOR的默认路由。同样,对于TOR来说只有到直连vRouter和spine switch的路由。即使我们一个机架下有80台计算节点,每个计算节点上有200个Endpoint, 那在TOR上也就16000条记录左右。(大多数交换机都能达到这个数目) 由于路由下发默认是由 spine 发起的,所以下游的AS接受者无法下发路由,这就避免了AS的干扰问题。 这种模式下,有个主要的缺点:非法目的地址(eg. 目的地址不存在)的流量都会被送往spine switch。 值得注意的是,spine switch会收集 calico 网络中所有的路由条目。这种模式并不会使spine switch 中的路由条目比原来更多,但却着实减少了TOR上的路由信息。同时也减少了vRouter上的路由信息。但这并不是关注的重点,因为Calico中的完整路由表所消耗的内存量是现代计算服务器上可用总内存的一部分。 ## 做一个calico模拟 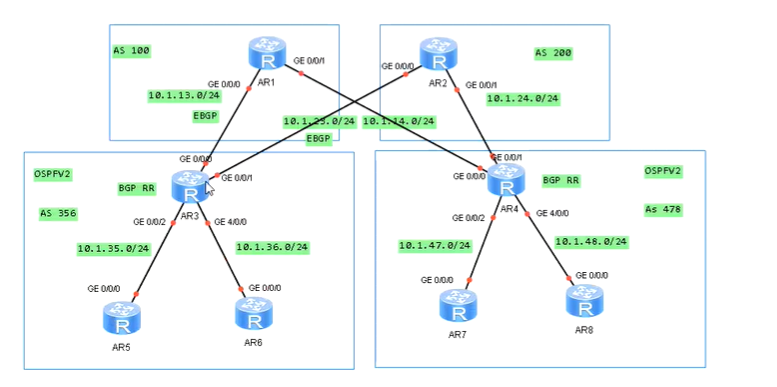 tn2>配置直连基础配置。 ```bash system-view sysname AR1 int g0/0/0 ip a 10.1.13.1 24 dis this int g0/0/1 ip a 10.1.14.1 24 dis this ``` ```bash system-view sysname AR2 int g0/0/0 ip a 10.1.23.2 24 dis this int g0/0/1 ip a 10.1.24.1 24 dis this ``` ```bash system-view sysname AR3 int g0/0/0 ip a 10.1.13.3 24 dis this int g0/0/1 ip a 10.1.23.3 24 int g0/0/2 ip a 10.1.35.3 24 int g4/0/0 ip a 10.1.36.3 24 dis this int L0 ip a 3.3.3.3 32 ``` ```bash system-view sysname AR5 int g0/0/0 ip a 10.1.35.5 24 int L0 ip a 5.5.5.5 32 dis ip int b ping 10.1.35.3 ``` ```bash system-view sysname AR6 int g0/0/0 ip a 10.1.36.6 24 int L0 ip a 6.6.6.6 32 dis ip int b ping 10.1.36.3 ``` ```bash system-view sysname AR4 int g0/0/0 ip a 10.1.14.4 24 dis this int g0/0/1 ip a 10.1.24.4 24 int g0/0/2 ip a 10.1.47.4 24 int g4/0/0 ip a 10.1.48.4 24 dis this int L0 ip a 4.4.4.4 32 dis ip int b ping 10.1.14.1 ping 10.1.24.2 ``` ```bash system-view sysname AR7 int g0/0/0 ip a 10.1.47.7 24 int L0 ip a 7.7.7.7 32 dis ip int b ping 10.1.47.4 ``` ```bash system-view sysname AR8 int g0/0/0 ip a 10.1.48.8 24 int L0 ip a 8.8.8.8 32 dis ip int b ping 10.1.48.4 ``` tn2>配置ospf ```bash # AR5 ospf router-id 5.5.5.5 A 0 network 0.0.0.0 255.255.255.255 q q bgp 356 router-id 5.5.5.5 peer 3.3.3.3 as-number 356 peer 3.3.3.3 conect-interface L0 dis this ``` ```bash # AR6 ospf router-id 6.6.6.6 A 0 network 0.0.0.0 255.255.255.255 q q bgp 356 router-id 6.6.6.6 peer 3.3.3.3 as-number 356 peer 3.3.3.3 conect-interface L0 dis this ``` ```bash # AR3 ospf router-id 3.3.3.3 A 0 network 0.0.0.0 255.255.255.255 q q bgp 356 router-id 3.3.3.3 peer 5.5.5.5 as-number 356 peer 5.5.5.5 conect-interface L0 peer 6.6.6.6 as-number 356 peer 6.6.6.6 conect-interface L0 peer 5.5.5.5 reflect-client peer 6.6.6.6 reflect-client peer 10.1.13.1 as-number 100 peer 10.1.23.2 as-number 200 dis this dis bgp peer dis current-configuration ``` ```bash # AR1 system-view bgp 100 peer 10.1.13.3 as-number 356 dis peer peer 10.1.14.4 as-number 478 dis peer ping 10.1.13.3 dis this ``` ```bash # AR2 system-view bgp 200 peer 10.1.23.3 as-number 356 dis peer peer 10.1.24.4 as-number 478 dis peer ping 10.1.13.3 dis this ``` ```bash # AR4 ospf router-id 4.4.4.4 A 0 network 0.0.0.0 255.255.255.255 q q bgp 478 router-id 4.4.4.4 peer 7.7.7.7 as-number 478 peer 7.7.7.7 conect-interface L0 peer 8.8.8.8 as-number 478 peer 8.8.8.8 conect-interface L0 peer 7.7.7.7 reflect-client peer 8.8.8.8 reflect-client peer 10.1.14.1 as-number 100 peer 10.1.24.2 as-number 200 dis this dis bgp peer dis current-configuration ``` ```bash # AR7 ospf router-id 7.7.7.7 A 0 network 10.1.47.7 0.0.0.255 q q bgp 478 router-id 7.7.7.7 peer 4.4.4.4 as-number 478 peer 4.4.4.4 conect-interface L0 dis this int L1 ip a 77.77.77.77 32 bgp 478 network 77.77.77.77 255.255.255.255 dis this dis bgp routing-table ``` ```bash # AR7 ospf router-id 8.8.8.8 A 0 network 10.1.48.8 0.0.0.255 q q bgp 478 router-id 8.8.8.8 peer 4.4.4.4 as-number 478 peer 4.4.4.4 conect-interface L0 dis this ``` ```bash # AR6 验证 system-view bgp 356 int L1 ip a 66.66.66.66 32 q bgp 356 network 66.66.66.66 255.255.255.255 q dis bgp routing-table dis ip routing-table ```

