Elasticsearch 基于词项和基于全文的搜索 电脑版发表于:2021/1/3 17:22  >#Elasticsearch 基于词项和基于全文的搜索 [TOC] 基于 Term 的查询 ------------ ### Term 的重要性 <blockquote style="border-left-color:#50C1E9">**Term 是表达语意的最小单位。**搜索和利用语言统计模型进行自然语言的处理都需要处理 Term </blockquote> ### 特点 <blockquote style="border-left-color:#50C1E9">—— Term Level Query:Term Query / Range Query / Exists Query / Prefix Query / Wildcard Query —— 在 ES 中,Term 查询,对输入不做分词。会将输入作为一个整体,在倒排索引中查找准确的词项,并且使用**相关度算分**公司为每个包含该词项的文档进行**相关度算分** — 例如 “Apple Store” —— 可以通过 Constant Score 将查询转换成一个 Filtering,避免算分,并利用缓存,提高性能 </blockquote> ### 关于 Term 查询的例子 <blockquote style="border-left-color:#5BE7C4">准备一些案例代码数据 </blockquote> ```bash POST /products/_bulk { "index": { "_id": 1 }} { "productID" : "XHDK-A-1293-#fJ3","desc":"iPhone" } { "index": { "_id": 2 }} { "productID" : "KDKE-B-9947-#kL5","desc":"iPad" } { "index": { "_id": 3 }} { "productID" : "JODL-X-1937-#pV7","desc":"MBP" } ``` 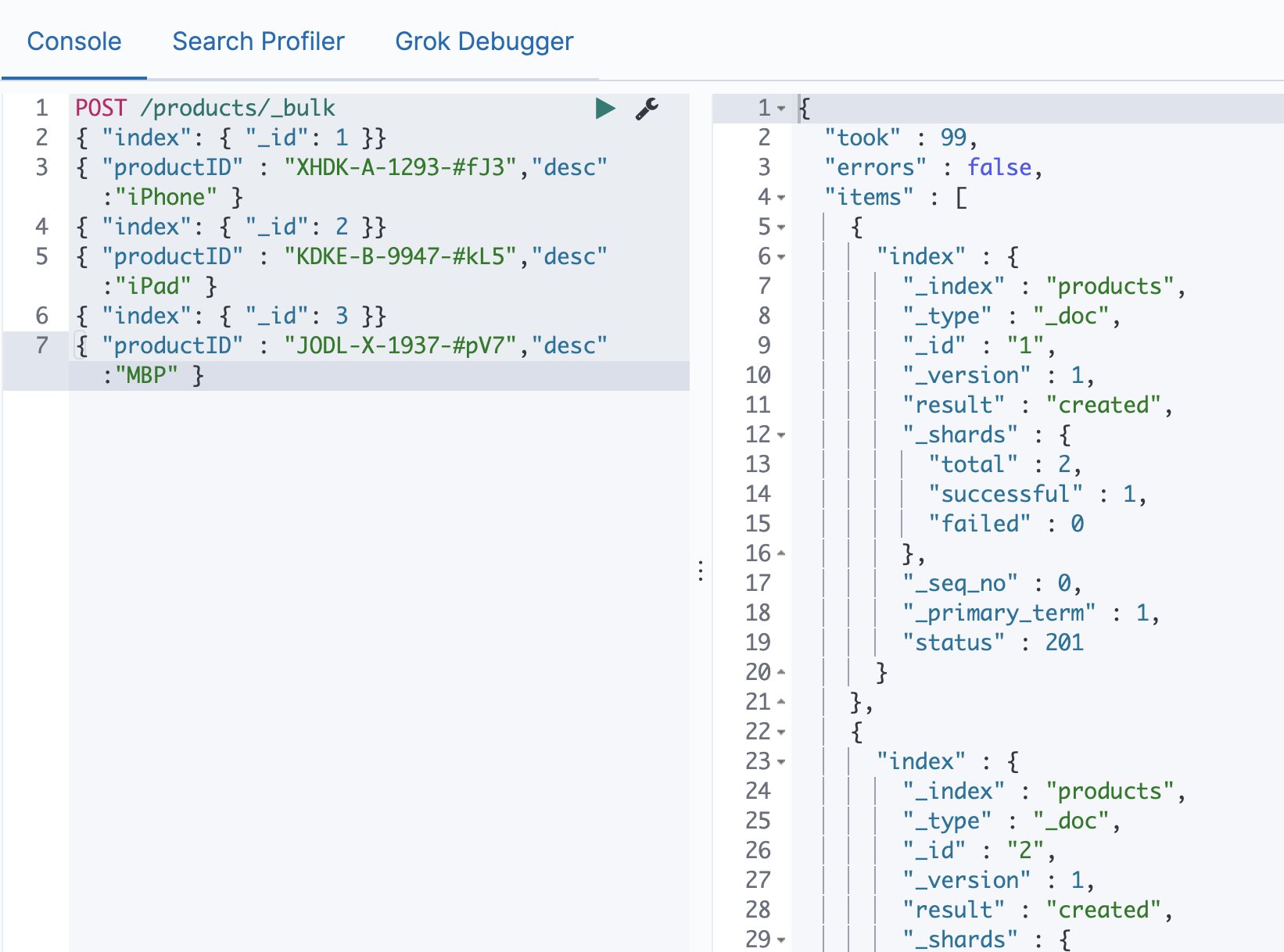 <blockquote style="border-left-color:#5BE7C4">通过Term的方式进行查询。 </blockquote> ```bash POST /products/_search { "query": { "term": { "desc": { //"value": "iPhone" "value":"iphone" } } } } ```  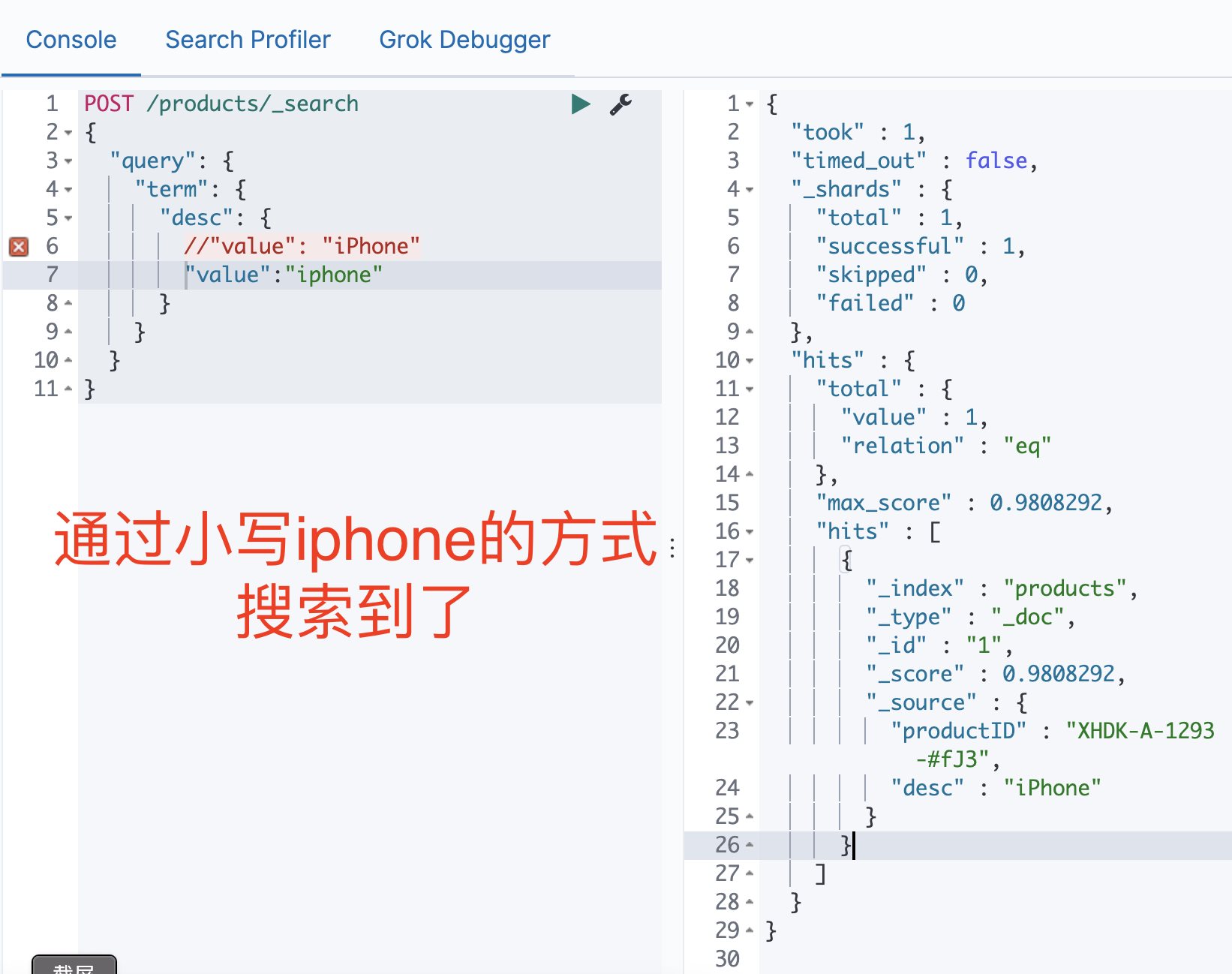 tn>注意:这是因为我们在添加数据进行索引的时候,Elasticsearch 自动的为数据添加默认的analyzer(变为小写),而并不是Term进行了分词处理。 ### 多字段 Mapping 和 Term 查询 <blockquote style="border-left-color:#50C1E9">通过 `GET /products/_mapping` 的查询出 Elasticsearch 会自动为字段赋值类型,这里为`keyword`</blockquote> 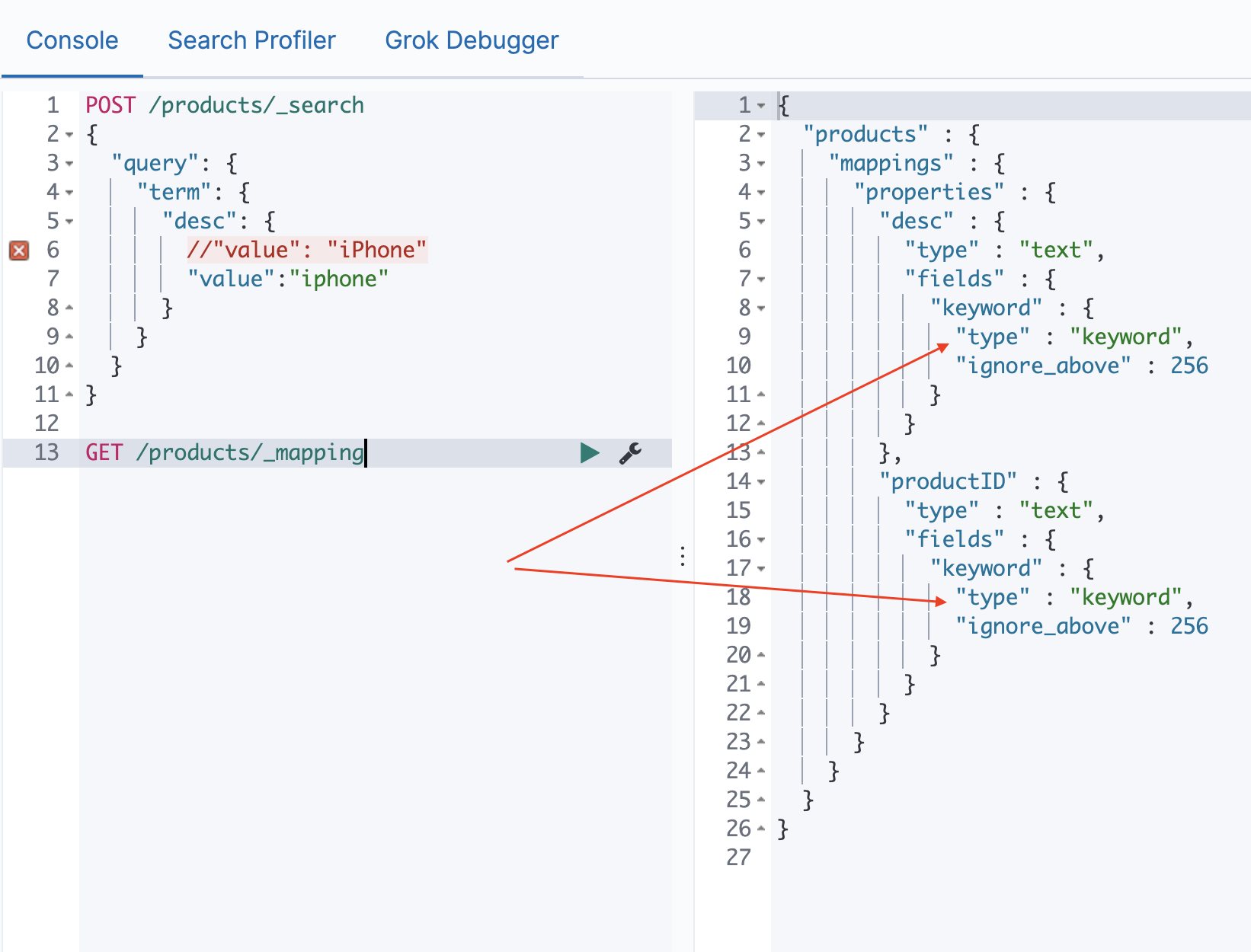 <blockquote style="border-left-color:#50C1E9">这里我们也可以通过指定 `keyword` 来进行查询</blockquote> ```bash POST /products/_search { "query": { "term": { "desc.keyword": { "value": "iPhone" } } } } ``` 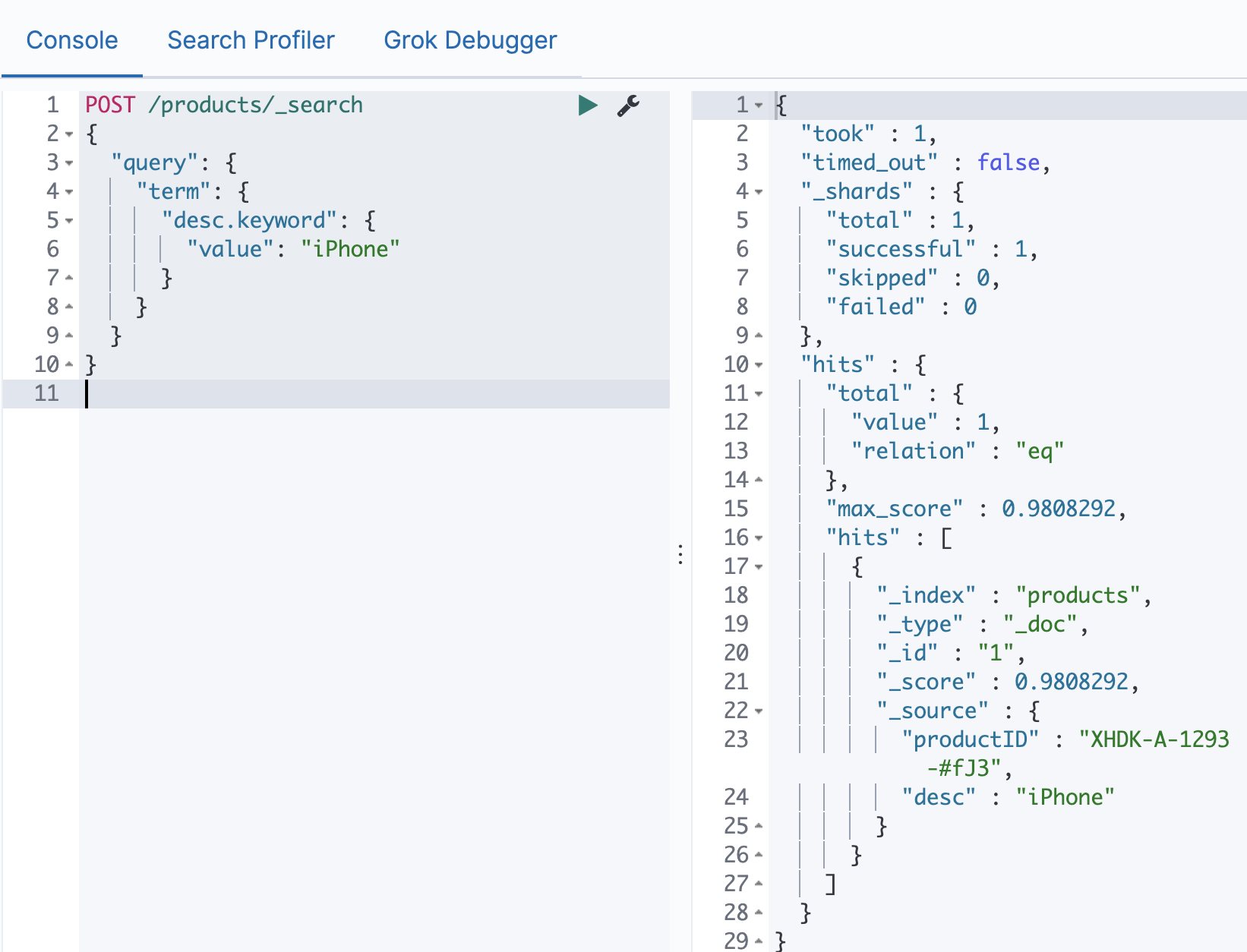 tn>但是在这里我们发现它仍然有一个 `_score` 的算分统计,它或多或少会影响系统性能。我们可以通过 Constant Score 告诉系统不进行算分。 ### 复合查询 — Constant Score 转为 Filter <blockquote style="border-left-color:#50C1E9">—— 将 Query 转成 Filter,忽略 TF-IDE 计算,避免相关性算分的开销。 —— FIlter 可以有效利用缓存。 </blockquote> ```bash POST /products/_search { "explain": true, "query": { "constant_score": { "filter": { "term": { "desc.keyword": { "value": "iPhone" } } } } } } ``` 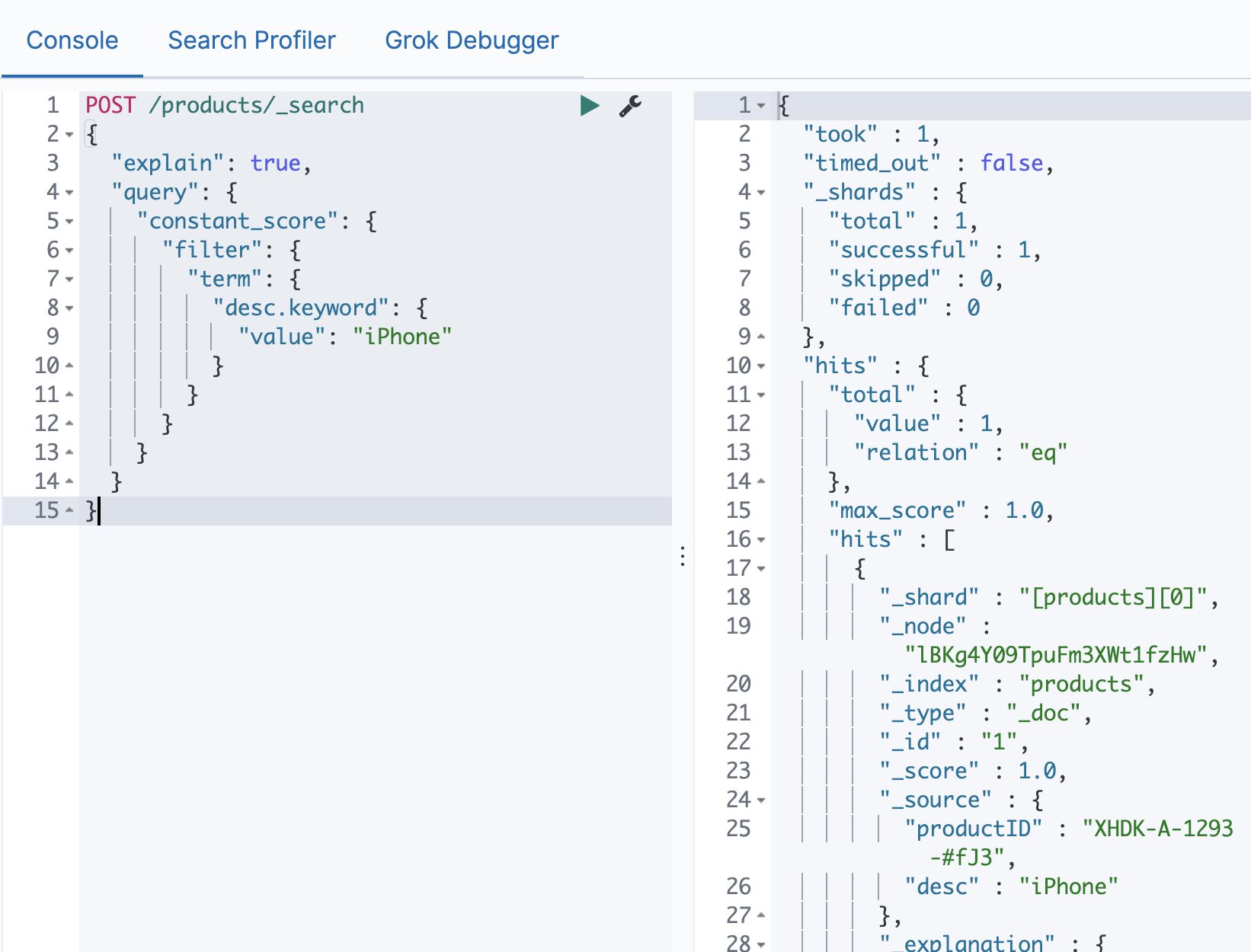 基于全文本的查询 ------------ ### 基于全文本的查找 <blockquote style="border-left-color:#50C1E9">Match Query / Match Phrase Query / Query String Query</blockquote> ### 特点 <blockquote style="border-left-color:#50C1E9">—— 索引和搜索时都会进行分词,查询字符串先传递到一个合适的分词器,然后生成一个供查询的词项列表 —— 查询时候,先会对输入的查询进行分词,然后每个词项逐个进行底层的查询,最终将结果进行合并。并为每一个文档生成一个算分。例如:查“Matrix reloaded”,会查到包括`Matrix` 或者 `reload` 的所有结果。</blockquote> 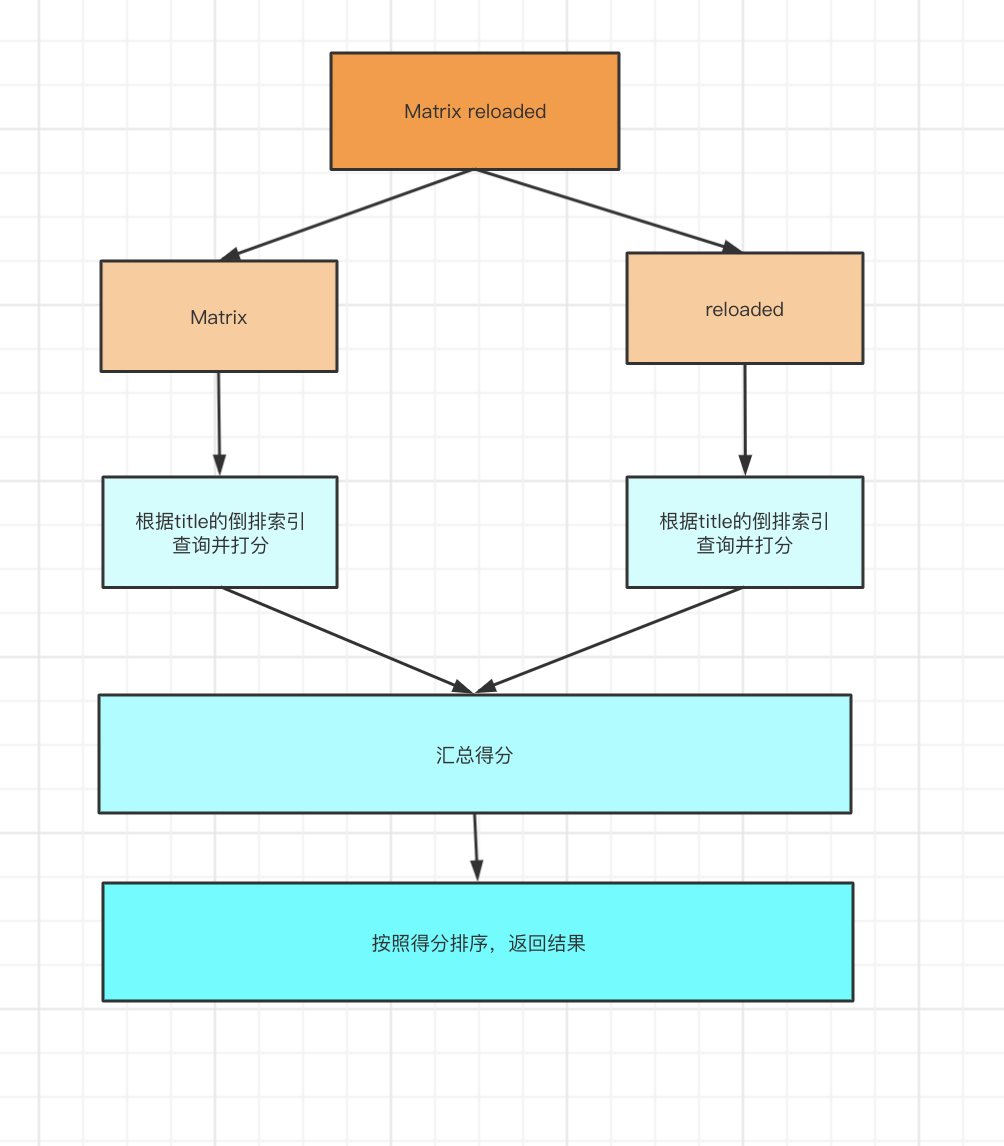 tn>有关更多,大家可以参考以前的文章:https://www.tnblog.net/hb/article/details/5071 总结 ------------ tn>首先Term查询是不会进行分词的,但在添加数据的索引的时候是会进行分词处理的,而全文本也会进行分词处理。 当然在用Term查询时,我们可以用字段 Mapping 去控制字段的分词(将字段类型写成Keyword),在用全文文本查询时也可以用适当的Precision & Recall去进行精确的查找。最后`Constant Score`可以将Term查询转换为Filter,取消算分缓解,以达到提升性能的目的。

