Elasticsearch 倒排索引(运用Analyzer进行分词) 电脑版发表于:2020/8/29 21:28  >#Elasticsearch 倒排索引 [TOC] <br/> 正排与倒排索引 ------------ tn>我们以一本书为例子,一本书的目录为正排索引,它将排列整本书的主要大纲。而倒排索引就像一些书的附页一样,上面记录着大量与本书相关的关键词。在搜索引擎当中,正排索引是从文档id,文档内容,单词的关联;倒排索引则是单词到文档id的关联。 倒排索引的核心索引 ------------ - 倒排索引包含两个部分 - 单词字典(Term Dictionary),记录所有文档的单词,记录单词到倒排索引的关联关系 - 单词字典比较大,可以通过 B+ 树或哈希拉链法的实现,以满足高性能的插入或查询 - 倒排列表(Posting List)记录了单词对应的文档结合,由倒排索引项组成 - 倒排索引项(Posting) - 文档ID - 词频 TF - 该单词在文档中出现的次数,用于相关性评分 - 位置(Position)- 单词在文档中分词的位置。用于语句搜索(phrase query) - 偏移(Offset)- 记录单词的开始结束位置,实现高亮显示。 举一个简单的例子 ------------  tn>当我们从文档内容中去搜索`Elasticsearch`时候,右边就是倒排索引显示的结果。 Elasticsearch 的倒排索引 ------------ - Elasticsearch 的JSON文档中的每个字段,都有自己的倒排索引。 - 可以指定某些字段不做索引 - 优点:节省存储空间 - 缺点:字段无法被搜索 Analysis 与 Analyzer ------------ - Analysis - 文本分析是把全文本转换为一系列单词(term、token)的过程,也叫分词 - Analysis 是通过 Analyzer 来实现的 - 可以使用 Elasticsearch 内置的分析器 / 或者按需定制化分析器 - 除了在数据写入时转换词条,匹配 Query 语句的时候也需要用相同的分析器对查询语句进行分析 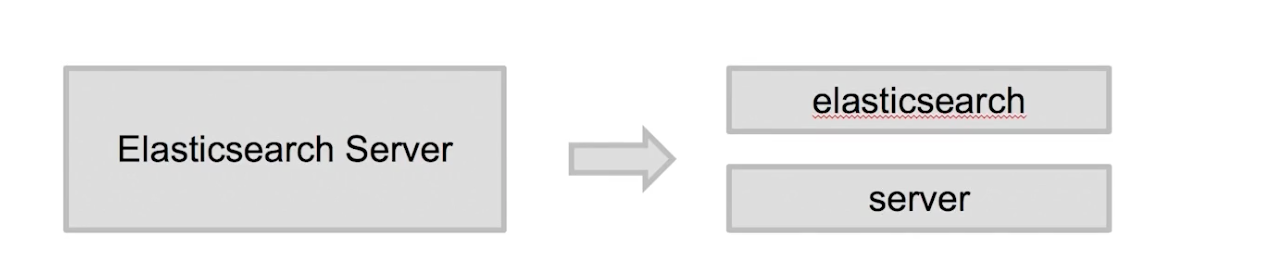 tn>从上图我们可以看见,`Elasticsearch Server`被分成`elasticsearch`与`server`,表明上看通过空格的方式进行的拆分,然后首字母进行小写。 Analyzer 的组成 ------------ - 分词器是专门处理分词的组件,Analyzer 由三部分组成 - Character Filters (针对原始文本处理,例如去除html) / Tokenizer(按照规则切分为单词)/ Token Filter(将切分的单词进行加工,小写,删除 stopwords,增加同义词) 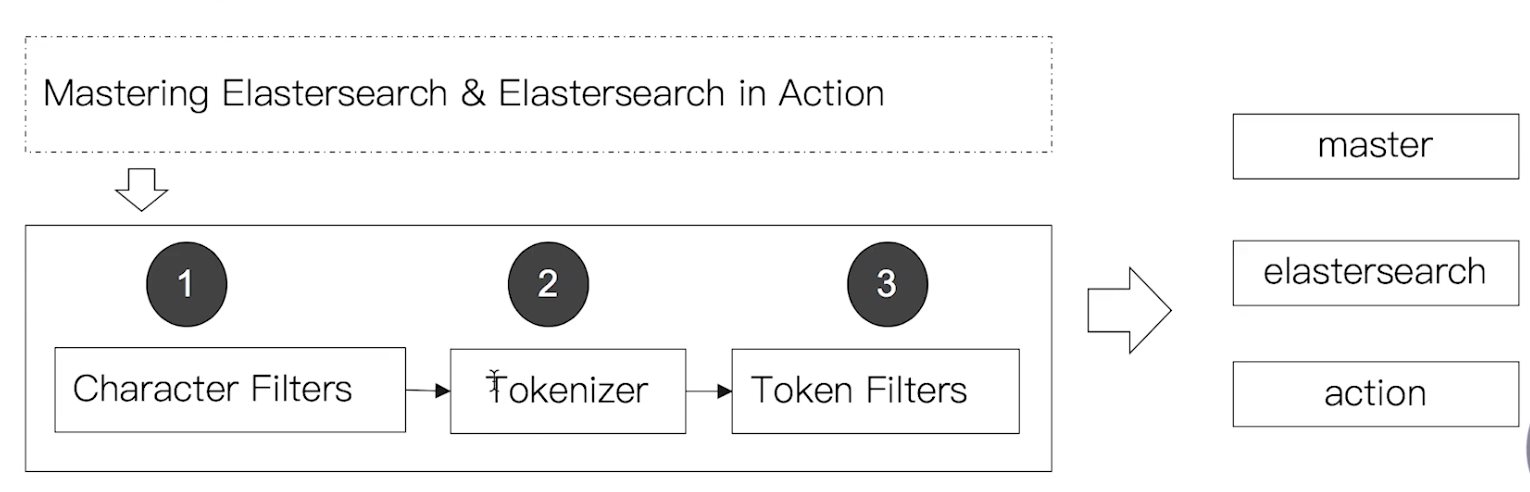 Elasticsearch 的内置分词器 ------------ >- **Standard Analyzer** - 默认分词器,按词切分,小写处理 - **Simple Analyzer** - 按照非字母切分(符号被过滤),小写处理 - **Stop Analyzer** - 小写处理,停用词过滤(the,a,is) - **Whitespace Analyzer** - 按照空格切分,不转小写 - **Keyword Analyzer** - 不分词,直接将输入当作输出 - **Patter Analyzer** - 支持正则表达式,默认 \W+(非字符分割) - **Language** - 提供了30多种常见语言的分词器 - **Customer Analyzer** 自定义分词器 使用 _analyzer API ------------ - 直接指定 Analyzer 进行测试 - 指定索引的字段进行测试 - 自定义分词进行测试 >###Standard Analyzer 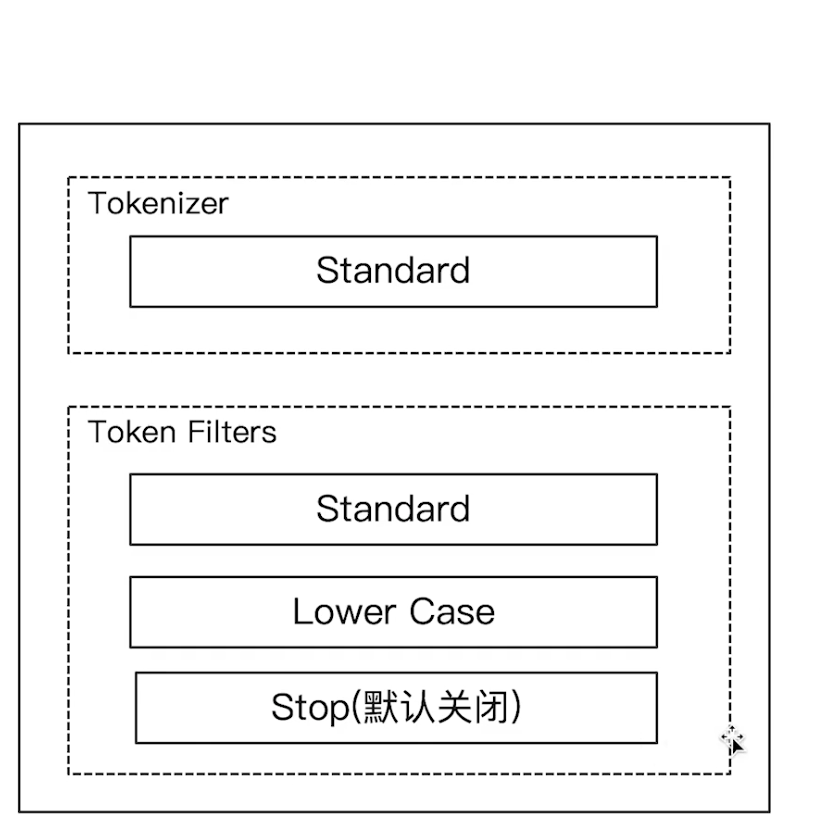 tn>默认分词器、按词切分、小写处理 ```bash #standard GET _analyze { "analyzer": "standard", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } ``` >部分截图  >###Simple Analyzer 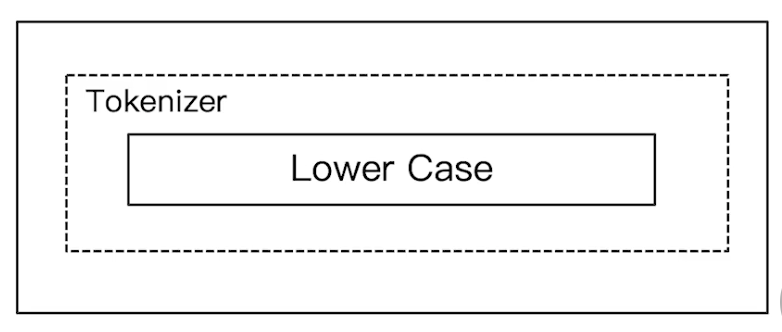 tn>按照非字母切分,非字母的都被去除;小写处理 ```bash #simpe GET _analyze { "analyzer": "simple", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } ``` 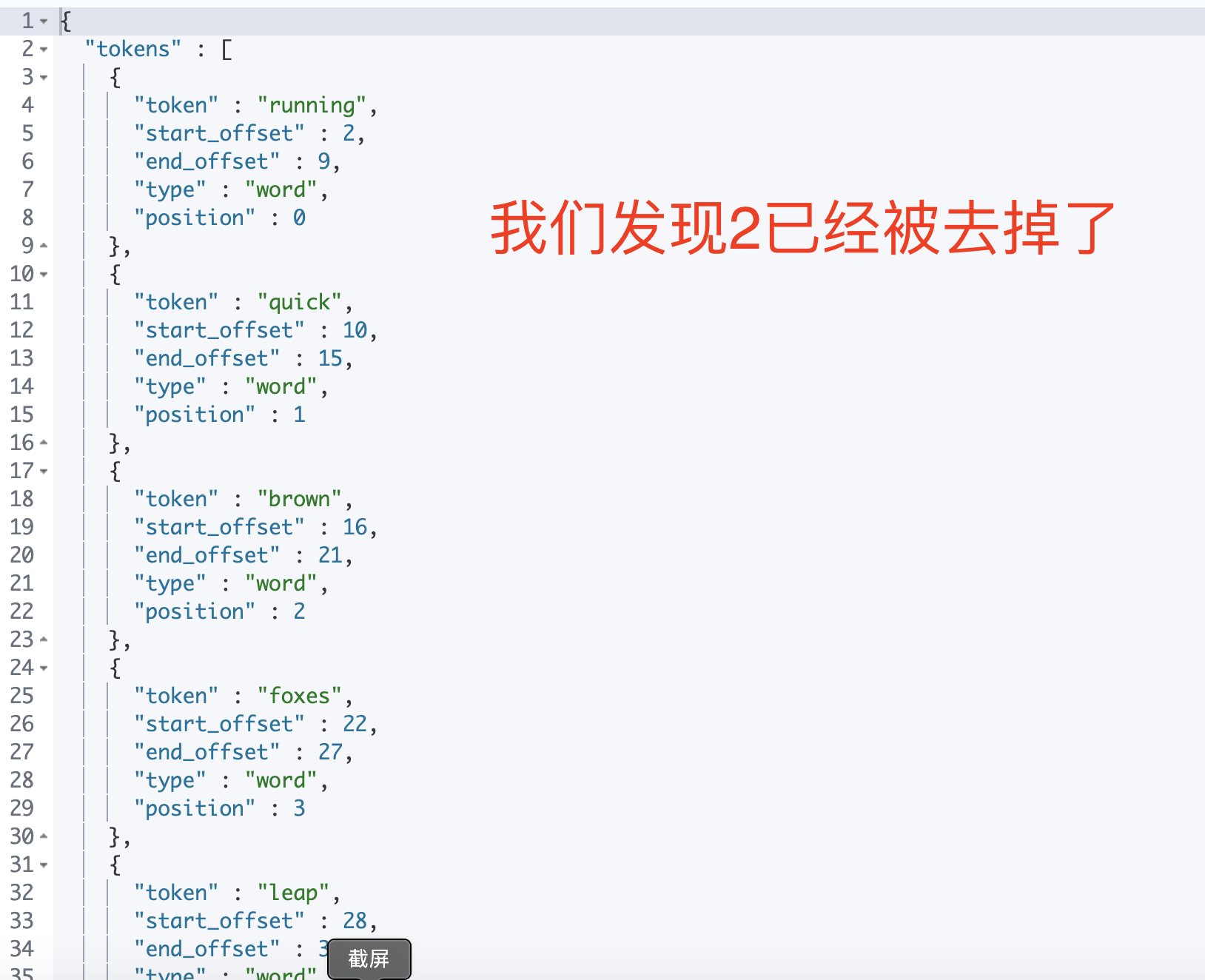 >###Whitespace Analyzer 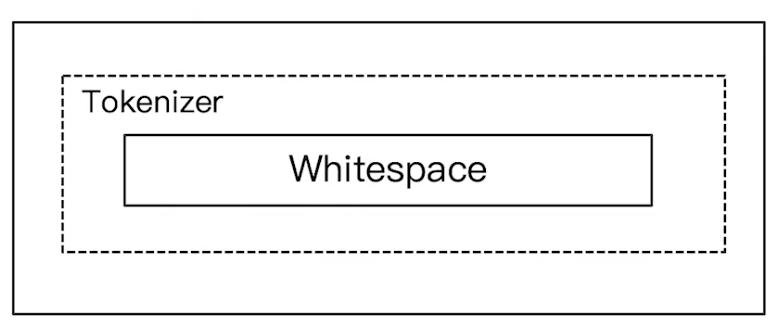 tn>按照空格切分 ```bash GET _analyze { "analyzer": "whitespace", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } ```  >###Stop Analyzer 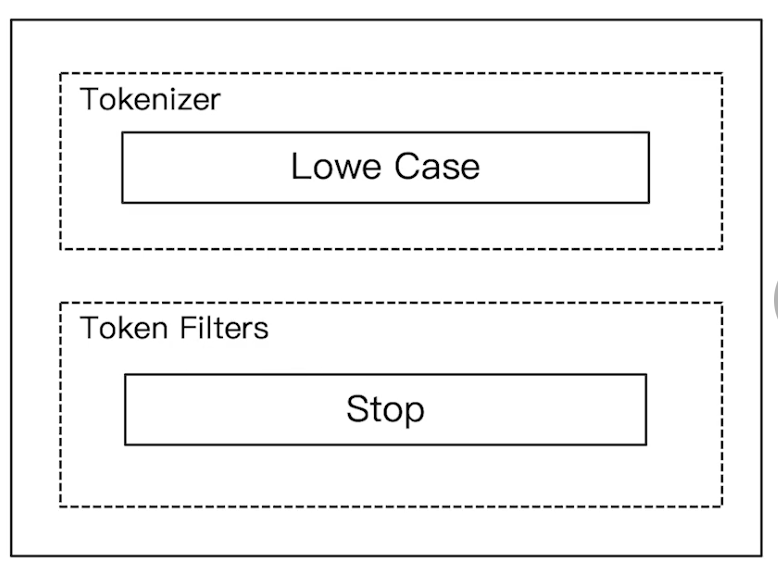 tn>相比 Simple Analyzer 多了stop filter(会把 the、a、is 等修饰性词语去除) ```bash GET _analyze { "analyzer": "stop", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } ```  >###Keyword Analyzer 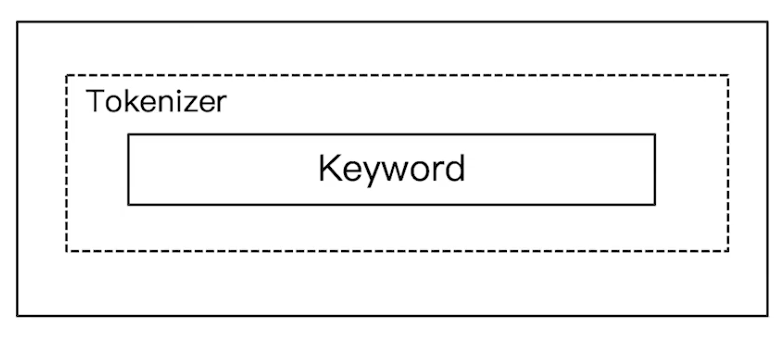 tn>不分词,直接将输入当一个term输出 ```bash #keyword GET _analyze { "analyzer": "keyword", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } ``` 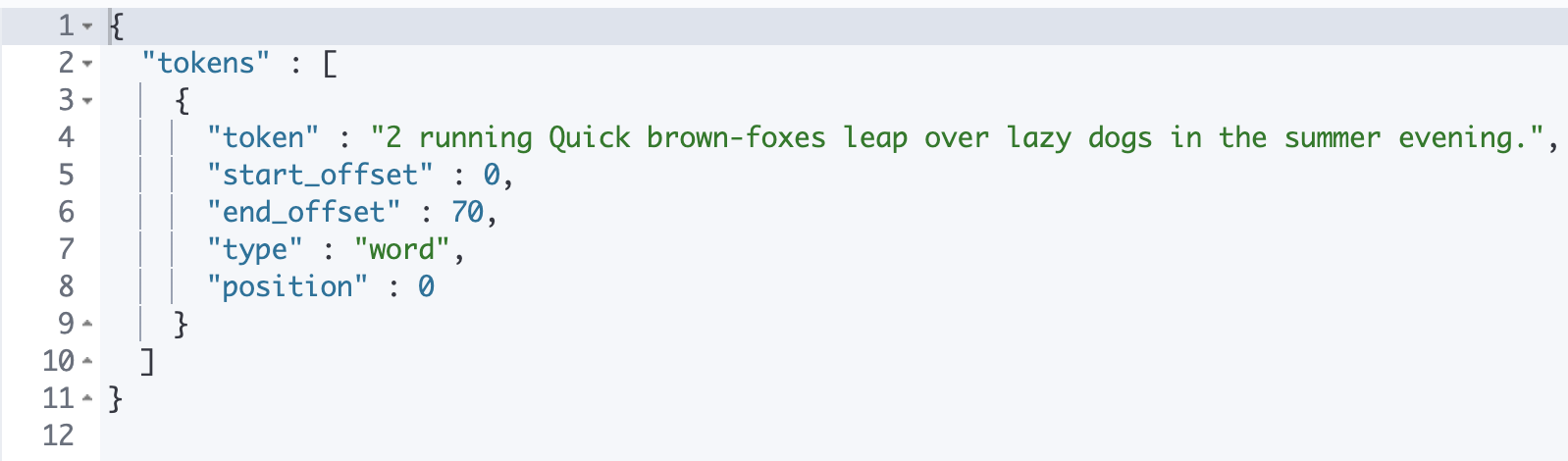 >###Pattern Analyzer 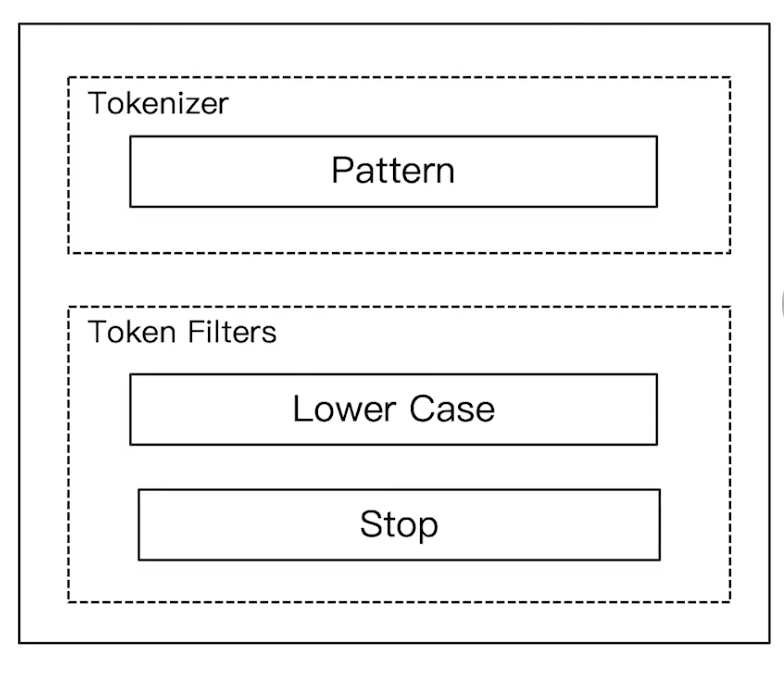 tn>通过正则表达式进行分词;默认是\W+,非字符当符号进行分割 ```bash GET _analyze { "analyzer": "pattern", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } ```  >###Language Analyzer <br/> tn>通过语言的方式进行分割。(这里用英语的方式) ```bash #english GET _analyze { "analyzer": "english", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } ```  >###中文分词(ICU Analyzer与其他) <br/> tn>中文分词难点在于不应该拆分成一个个字 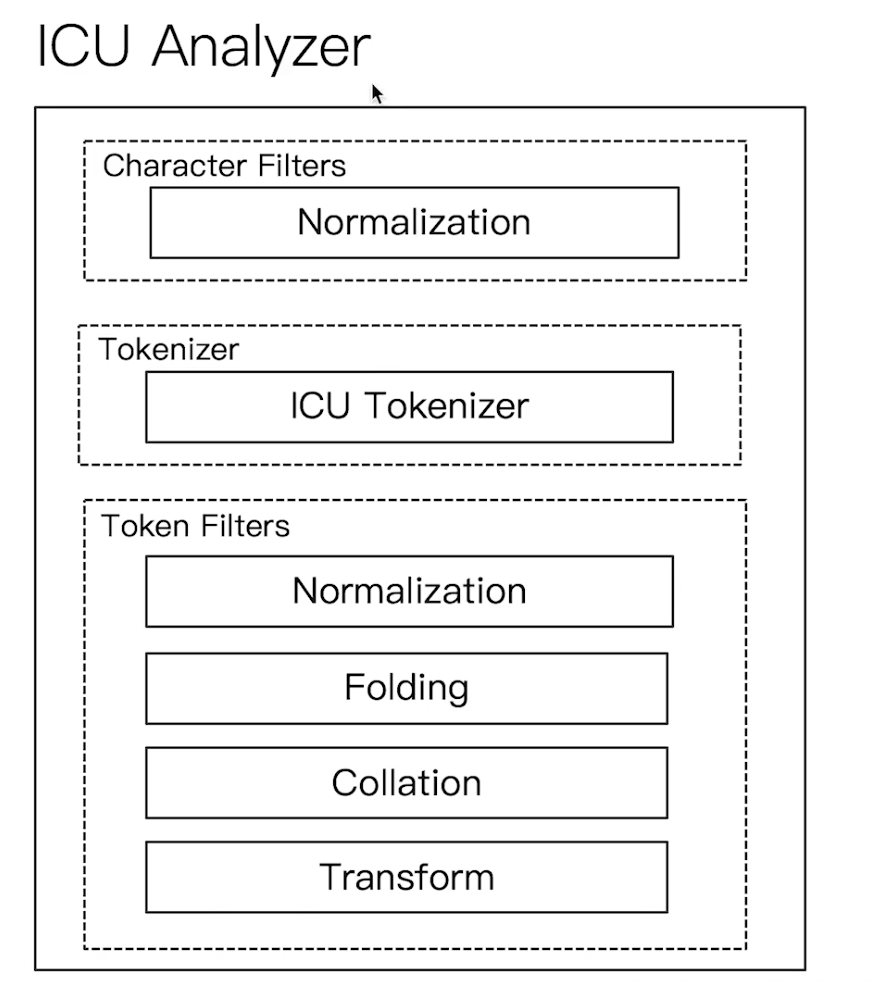 - 需要安装 - Elasticsearch-plugin install analysis-icu - 提供了 Unicode 的支持,更好的支持亚洲语言 ```bash POST _analyze { "analyzer": "icu_analyzer", "text": "他说的确实在理”" } ``` 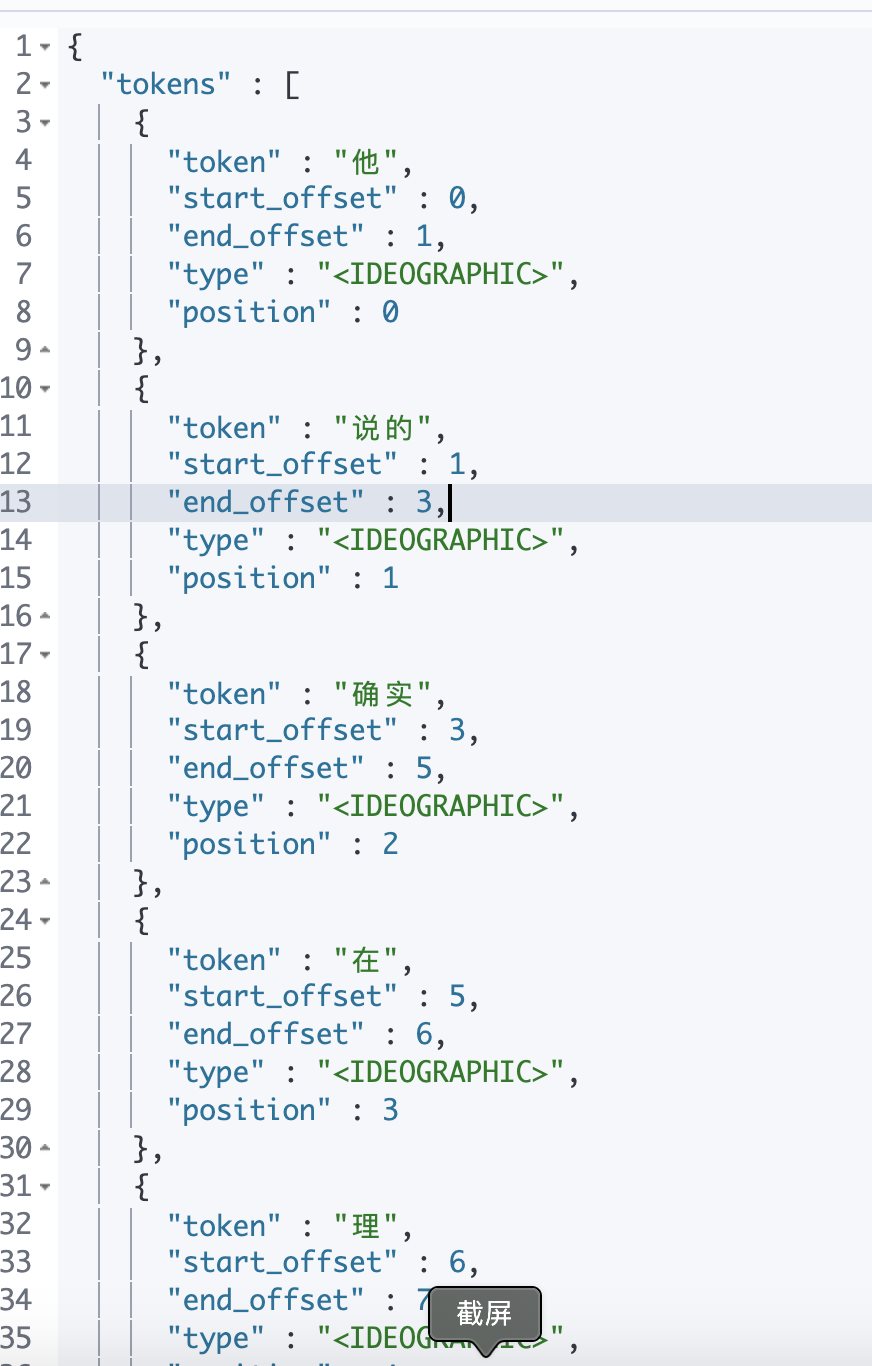 >###更多的中文分词器 - IK - 支持自定义词库,支持热更新分词字典 - https://github.com/medci/elasticsearch-analysis-ik - THULAC - THC Lexucal Analyzer for Chinese,清华大学自然语言处理和社会人文计算实验室的一套中文分词 - https://github.com/microbun/elasticsearch-thulac-plugin

