正则简单实例
电脑版发表于:2019/5/16 17:07
正则:用来查找、替换,拆分某些符合规则的文本
介绍一些常用的一些正则符号、规则!
特殊符号
*:重复多次、贪婪匹配
+:重复一次或多次
?:重复一次、非贪婪匹配
\d:所有数字 => [0-9] 取反:\D => [^0-9]
\w:所有字符(数字,字母,下划线) => [a-zA-Z_0-9] 取反:\W => [^a-zA-Z_0-9_]
|:或
\s:任何不可见字符 换行 空格,换页符 取反:\S:任何可见字符
[\u4e00-\u9fa5]:所有汉字
^ : 从xx开始
$:以xx结尾
[]:包含
[^]:不包含
():分组 将匹配到的内容存起来 一个正则中上限9个
{}:限定匹配。 {n}:匹配n次 {n,}:最少匹配n次 {n,m}:最少匹配n,最多匹配m次
. :单个任意字符
实例
一、.查找
以1开头,5结尾
/^1.*5$/.test('125545345')
//'^1.*5$' 解析 =》 ^1:1开始; .*:多个任意字符; 5$:5结束匹配身份证号
/^(\d{6})([1-9]{1})(\d{10})([0-9]|X)$/.test('32211520080102363X')
//'^(\d{6})([1-9]{1})(\d{10})([0-9]|X)$' 解析 =》 ^(\d{6}):以6位数字开头 ([1-9]{1}) 代表地区码; ([1-9]{1}):1-9的数字 年份 不能为0开头; ([0-9]|X)$:0-9或者X结尾匹配手机号
/^[1-9]{2}[0-9]{9}$/.test('18888888888')
//^[1-9]{2}[0-9]{9}$ 解析 =》 ^[1-9]{2}:前2位不以0开始 [0-9]{9}$ 后9位 以0-9的数字结尾
二、替换
替换所有数字
'1a2b3c4d'.replace(/[\d/g]/,'#') //输出:#a#b#c#d
//[\d/g] 解析:\d:数字; \g:匹配所有; [\d/g]:匹配每个数字
三、分组 拆分
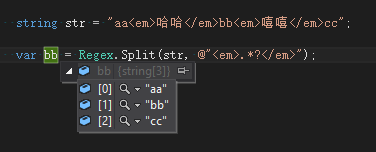
string str = "aa<em>哈哈</em>bb<em>嘻嘻</em>cc";
以<em>..</em>标签内的内容拆分
![]()
解析 <em>.*?</em> : 非贪婪模式匹配 em标签内任意可见字符重复1次
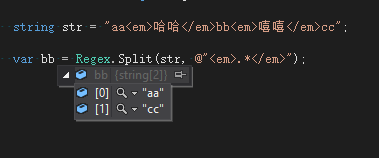
如果不加?则会变成:
![]()
因为*是贪婪模式,他会去匹配第一个em和最后一个/em ![]()
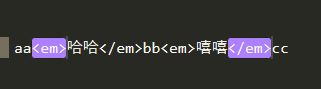
取em标签内的内容
![]()
解析<em>(.*?)</em>: 非贪婪模式 将所有满足条件的内容分组