mysql存储引擎与索引。mysql创建唯一索引 电脑版发表于:2022/5/9 23:15 [TOC] ## mysql存储引擎 ### 一、存储引擎概念介绍 MySQL中的数据用各种不同的技术存储在文件中,每一种技术都使用不同的存储机制、索引技巧、锁定水平并最终提供不同的功能和能力,这些不同的技术以及配套的功能在MySQL中称为存储引擎 存储引擎是MySQL将数据存储在文件系统中的存储方式或者存储格式 MySQL数据库中的组件,负责执行实际的数据I/O操作 MySQL系统中,存储引擎处于文件系统之上,在数据保存到数据文件之前会传输到存储引擎,之后按照各个存储引擎的存储格式进行存储 ### 二、MySQL常用的存储引擎 #### MyISAM的特点 最主要的特点就是不支持:事务,行级锁,外键 - MyISAM不支持事务,也不支持外键约束,只支持全文索引,数据文件和索引文件是分开保存的 - 访问速度快,对事务完整性没有要求 MyISAM 适合查询、插入为主的应用 - MyISAM在磁盘上存储成三个文件,文件名和表名都相同,但是扩展名分别为: .frm 文件存储表结构的定义 数据文件的扩展名为 .MYD (MYData) 索引文件的扩展名是 .MYI (MYIndex) - 表级锁定形式,数据在更新时锁定整个表。不支持行数,只支持表锁 数据库在读写过程中相互阻塞: 会在数据写入的过程阻塞用户数据的读取 也会在数据读取的过程中阻塞用户的数据写入 数据单独写入或读取,速度过程较快且占用资源相对少 #### MyISAM适用的生产场景 公司业务不需要事务的支持 单方面读取或写入数据比较多的业务 MyISAM存储引擎数据读写都比较频繁场景不适合 使用读写并发访问相对较低的业务 数据修改相对较少的业务 对数据业务一致性要求不是非常高的业务 服务器硬件资源相对比较差 #### InnoDB ##### InnoDB特点 其实最主要的区别就是支持:事务,行级锁,外键 - 支持事务,支持4个事务隔离级别 MySQL从5.5.5版本开始,默认的存储引擎为 InnoDB - 读写阻塞与事务隔离级别相关 能非常高效的缓存索引和数据 表与主键以簇的方式存储 支持分区、表空间,类似oracle数据库 支持外键约束,5.5前不支持全文索引,5.5后支持全文索引 - 对硬件资源要求还是比较高的场合 行级锁定,但是全 表扫描仍然会是表级锁定,如 update table set a=1 where user like ‘%lic%’; - InnoDB 中不保存表的行数,如 select count() from table; 时,InnoDB 需要扫描一遍整个表来计算有多少行,但是 MyISAM 只要简单的读出保存好的行数即可。需要注意的是,当 count()语句包含 where 条件时 MyISAM 也需要扫描整个表 对于自增长的字段,InnoDB 中必须包含只有该字段的索引,但是在 MyISAM 表中可以和其他字段一起建立组合索引 #### MEMORY的特点 存放在内存中,速度快,但是数据安全性 ### 三:存储引擎的简单操作 ``` -- 查看系统支持的存储引擎 show ENGINES -- 创建表的时候指定引擎 create table test ( id int primary key ) ENGINE MyISAM -- 可以使用下面的命令查看表的存储引擎 show create table test show create table users ``` ## mysql 索引 高效获取数据的方式,是一种数据结构。类似书的目录,图书馆的目录等,都是为了快速查找,避免轮询,全表扫描的。mysql使用索引是很简单的,但是要理解到原理就并没有那么容易。 tn2> mysql索引是一种数据库结构,并不是越多越好,维护也需要时间空间成本。但是也可以做到以空间换效率,毕竟现在空间相对便宜,而且查询往往比增删改多很多 #### 使用索引与不使用索引查找的区别 比如查询年龄等于45岁的 **不使用索引的查找:** 要挨着挨着进行全表扫描,因为你不能确定45岁的有多少个人 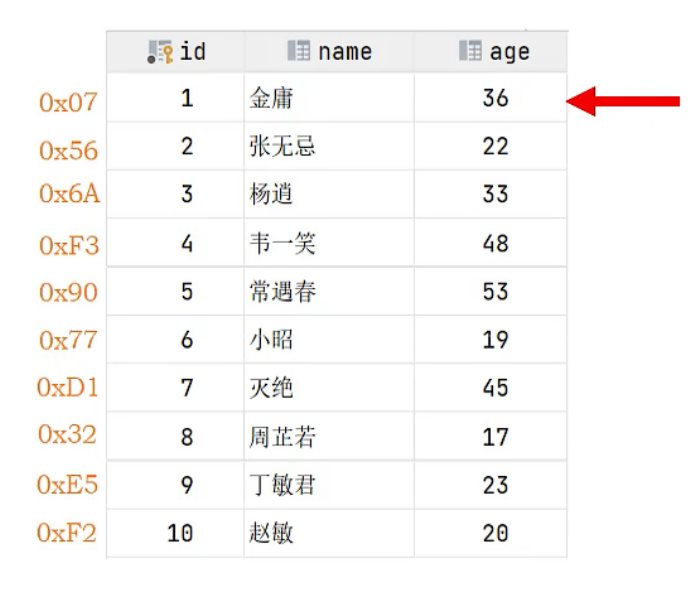 **使用索引的方式:** 例如下面的二叉树结构,当然mysql真正使用的数据库结构是b+数等数据类型  #### MySQL索引使用数据结构 MySQL索引会根据存储引擎的不同,从而选择不同的索引,主要支持下面几种  在不同存储引擎中的支持情况: 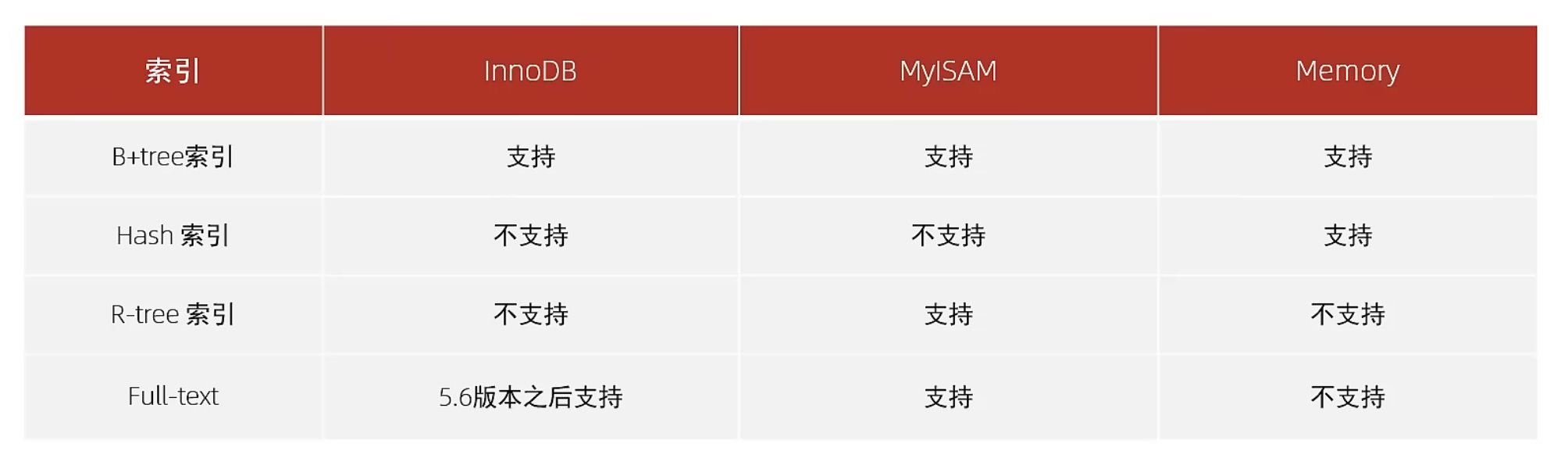 ### 索引数据结构分析 #### 索引数据结构之二叉树 特点:只能存储两个节点,数据库大了其实效率也并不是那么高,大量的数据造成的层级可能会很深。而且可能顺序插入时,形成一个单向链表,查询性能大大降低。 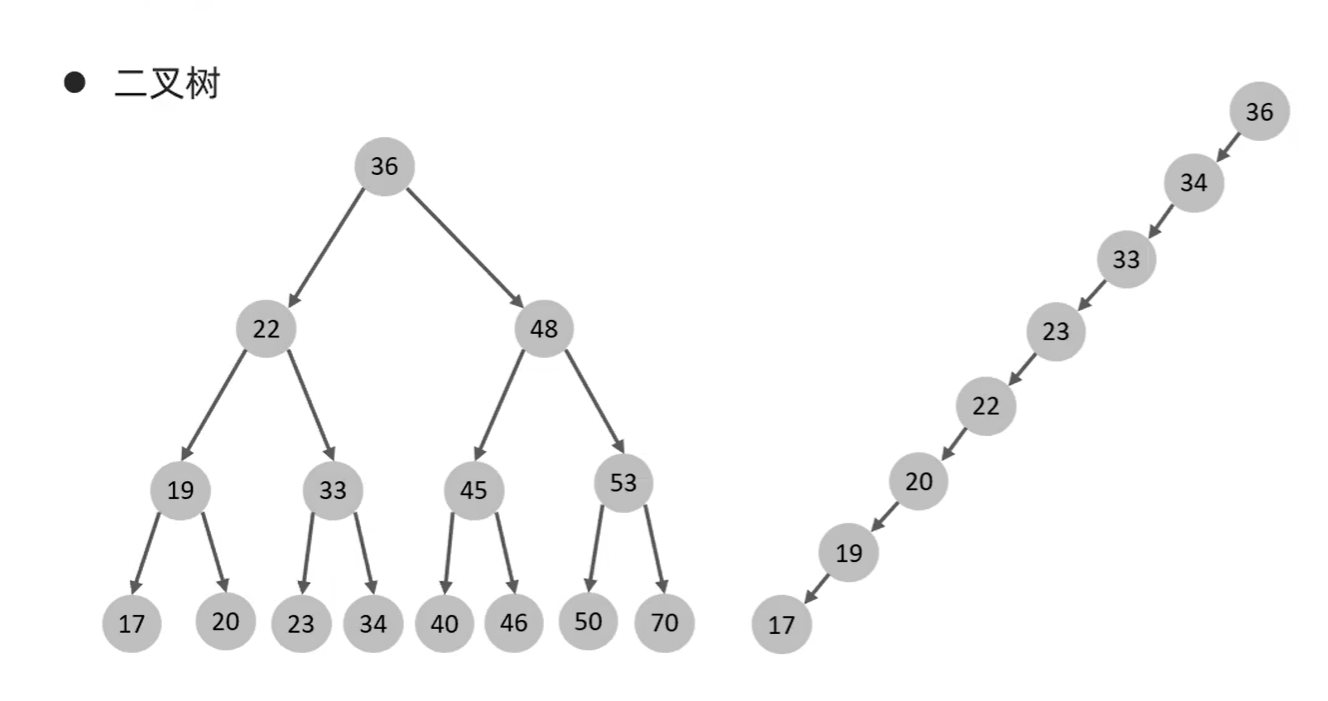 所以二叉树不是太适合用来做数据库的索引。这种问题虽然可以使用自平衡的红黑树来解决,但是红黑色本质也是一个二拆书,大数据量情况下还是会存在层级较深的情况,查询效率也不高,所以我们可以考虑使用B树,就可以有多个子节点 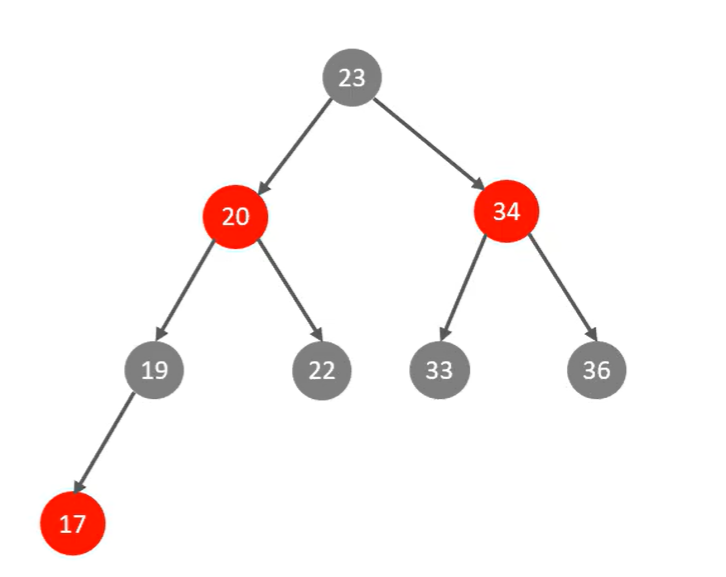 #### 索引数据结构之B Tree(b树) 多路平衡查找树: 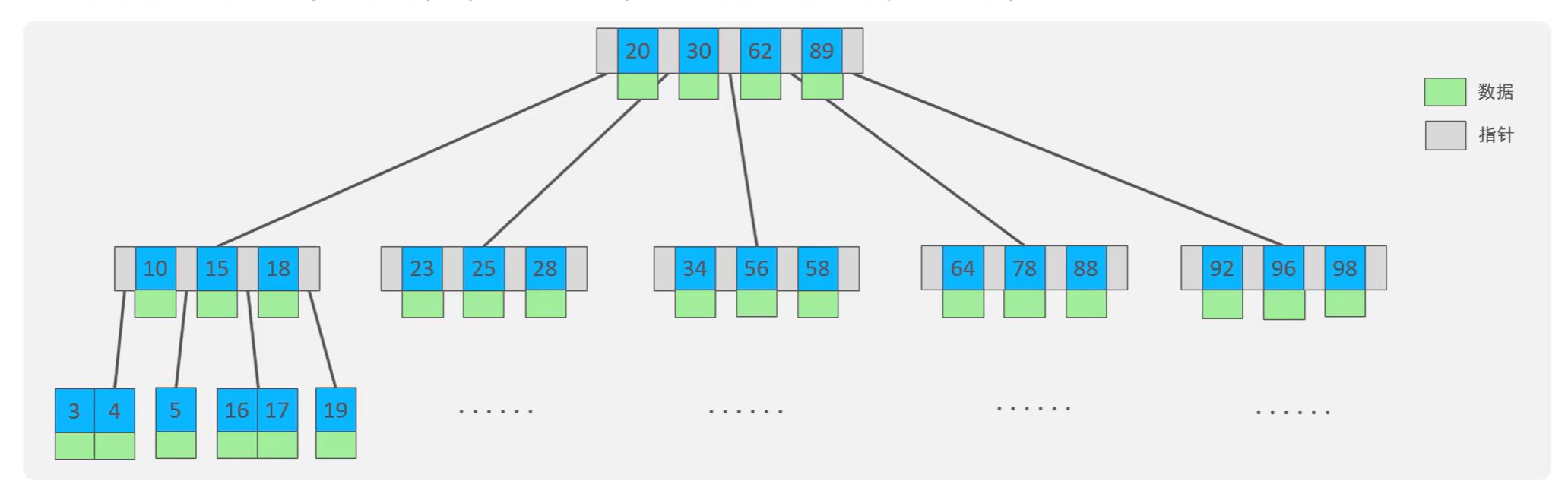 度数就是可以容纳的子节点个数 ##### 动态构建B树,B树的分裂方式 可视化网站: https://www.cs.usfca.edu/~galles/visualization/BTree.html  #### 索引数据结构之B + Tree(b+树) https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html ### 索引的基本语法 ``` -- 查看索引 show index from students -- 创建索引 create index index_age on students(age) -- 创建两个字段的联合索引 ALTER TABLE rep_school_class_course_count_data_code ADD INDEX index_class_courseid (ClassID, CourseID); -- 删除索引 drop index index_age on students ``` #### mysql创建唯一索引 语法: ``` CREATE UNIQUE INDEX index_name ON table_name(column1, column2, ...); ``` 实例: ``` CREATE UNIQUE INDEX index_unique_usercomplete ON project_members_result(ProgramID,SubProgramId,CreateID); ```

