
c# 一个中文按照两个字节处理
电脑版发表于:2019/6/3 21:10
一个字等于多少个字节,是一个不严谨的问法。因为使用不同的编码方式获取的字节数是不同的
英文字母:
字节数 : 1;编码:GB2312
字节数 : 1;编码:GBK
字数 : 1;编码:GB18030
字节数 : 1;编码:ISO-8859-1
字节数 : 1;编码:UTF-8
字节数 : 4;编码:UTF-16
字节数 : 2;编码:UTF-16BE
字节数 : 2;编码:UTF-16LE
中文汉字:
字节数 : 2;编码:GB2312
字节数 : 2;编码:GBK
字节数 : 2;编码:GB18030
字节数 : 1;编码:ISO-8859-1
字节数 : 3;编码:UTF-8
字节数 : 4;编码:UTF-16
字节数 : 2;编码:UTF-16BE
字节数 : 2;编码:UTF-16LE
所以想要一个中文当中两个字节处理的话,可以这样写
int count = Encoding.GetEncoding("GB2312").GetBytes("中级").Length;
Console.WriteLine(count);但是...在net core中居然说不支持gb2312编码方式
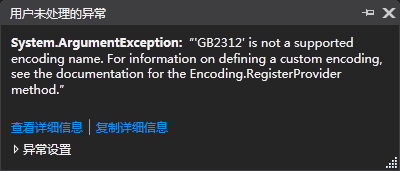
试试GBK呢,果然还是不支持......
安装System.Text.Encoding.CodePages:
Install-Package System.Text.Encoding.CodePages
居然还不行,我勒个去......我想出教室了啊
要在ConfigureServices注入一下才行!
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
然后发布之后又报错 我艹,错误日志也不报错一下
我艹,错误日志也不报错一下
哎还是自己太着急了,想早点下班,有错误日志的,错也很简单
